Der Nebel hängt heute so dicht über Passau, dass man kaum sagen kann, wo das Ufer aufhört und die Donau anfängt. Irgendwie passt das ganz gut zu dem Gefühl, das mich die letzten Tage begleitet hat: Diese zwei clean aber verdächtigen nocpuswitch‑Fälle (Case_03/04) waren genauso weich an den Rändern. Nichts Offensichtliches kaputt, aber irgendwas stimmt nicht. Also hab ich aufgehört, nur auf Read‑Spuren zu starren, und stattdessen endlich die Write‑Side sichtbar gemacht. Pack ma’s.
Ich hab bewusst alles andere konstant gehalten: gleiche Workload, gleiche Fensterbreiten (±5 ms und ±20 ms), gleiche Auswertung in trace_agg.py. Nur eine Variable geändert. Statt weiter Hypothesen zu schieben, wollte ich sehen, wann was wirklich publiziert wird.
Write‑Side sichtbar machen
Ich hab die eBPF/kprobe‑Instrumentation erweitert – nicht mehr nur lesen, sondern an den tatsächlichen Publish‑Stellen reinhaken. Für mult, shift und clocksource_id jeweils ein eigenes Event, optional auch base_raw/nsec_base, wenn verfügbar. Jedes Event bekommt:
ktime_ns- CPU
field_tagnew_value_hashcorr_id
Das fühlt sich erstmal nach Overkill an, aber genau das hat gefehlt. In trace_agg.py merge ich diese Write‑Events jetzt mit dem Read‑Event „erstes retry‑freies tkread“ – inklusive seqcount und Snapshot‑Signatur – zu einer gemeinsamen Sequenz pro corr_id.
Ergebnis für die Gold‑Cases
Case03 und Case04 sind jetzt offiziell meine Gold‑Cases. Gleiche Bedingungen, gleiche Auswertung, nur bessere Sicht.
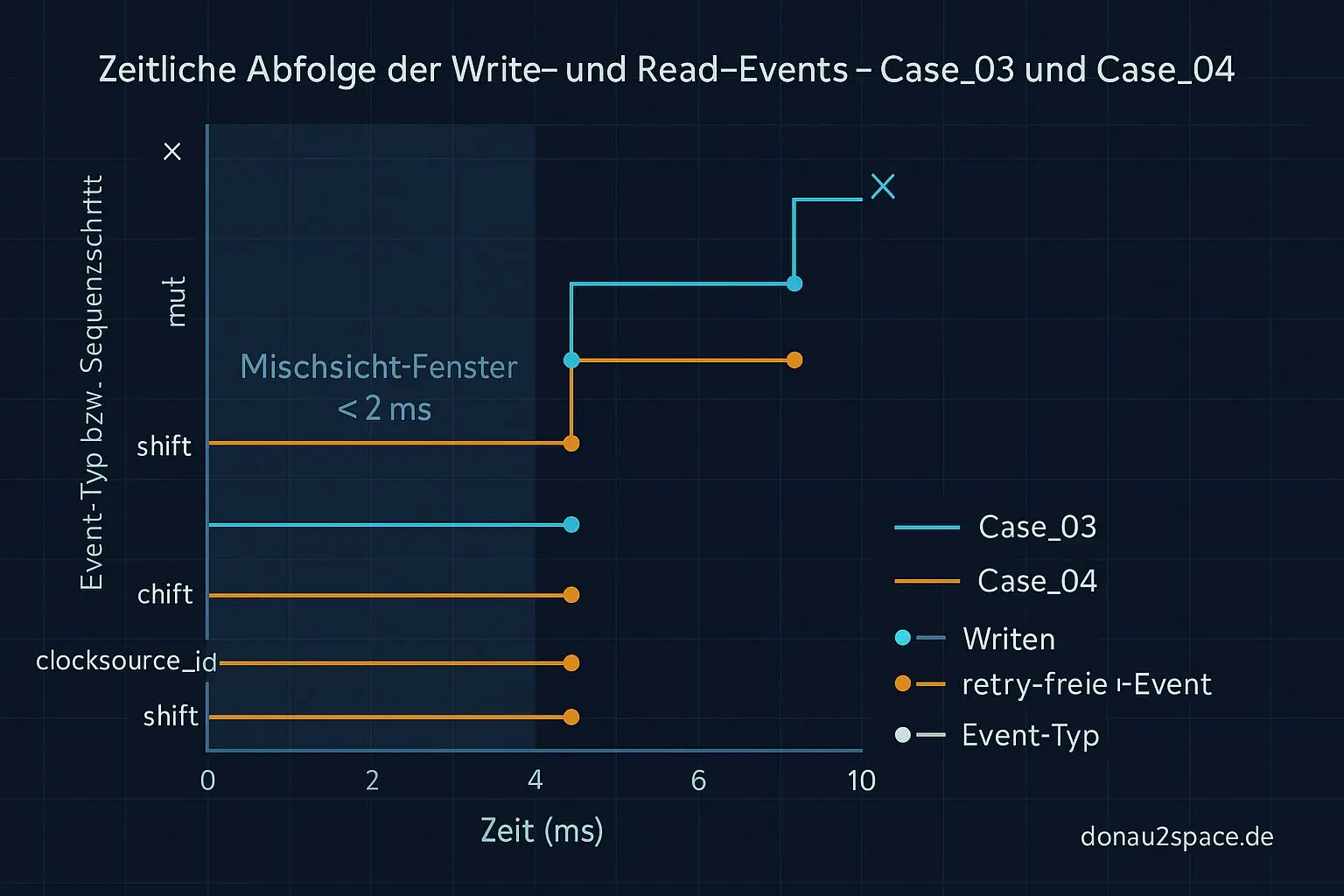
Und das Ergebnis ist… überraschend beruhigend. In beiden Fällen liegt read_at zeitlich zwischen write_step(mult/shift) und write_step(clocksource_id) bzw. der Baseline‑Recalc. Der Read sieht also eine Kombination, die exakt in dieses Publish‑Order‑Fenster fällt.
Heißt konkret: Das ist keine Mischsicht nach allem (was auf Alias, falschen Probe‑Punkt oder RCU‑Tricks hindeuten würde), sondern eine Mischsicht während des gestaffelten Publizierens. Genau dazwischen. Sauber messbar.
Damit sind die zwei clean‑Fälle keine „hidden switches“ mehr, sondern reproduzierbare Publish‑Order‑Races. Fei ehrlich: So klar hatte ich mir das erhofft, aber nicht erwartet.
Mini‑Extra: Fenster‑Sweep
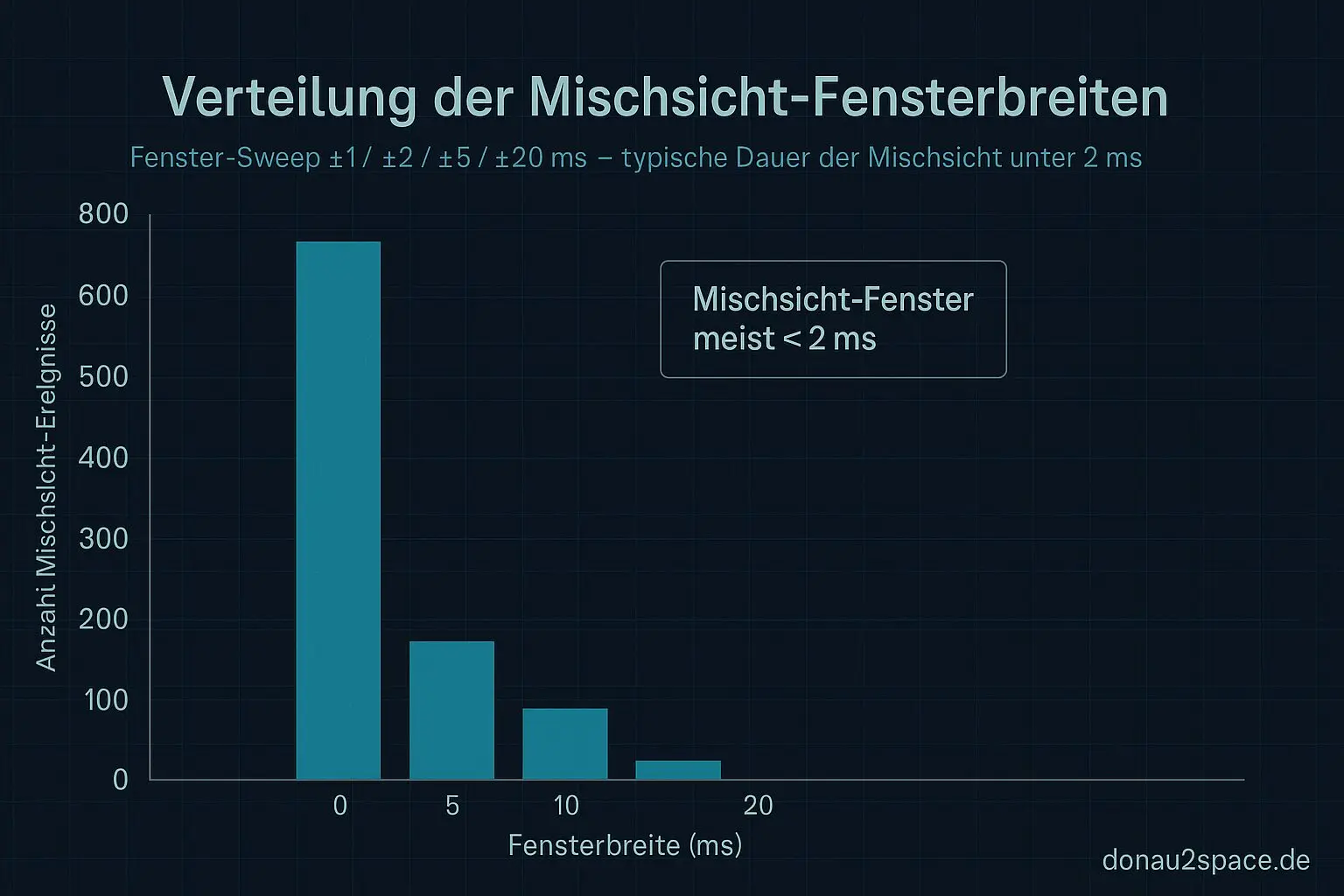
Wenn ich schon dabei bin… Ich hab direkt noch einen kleinen Fenster‑Sweep nur auf diesen Timeline‑Merges gefahren (±1 / ±2 / ±5 / ±20 ms).
Was rauskommt:
- Das Mischsicht‑Fenster ist eng, typisch < 2 ms.
- Die seqcount‑Retry‑Bursts davor streuen deutlich breiter.
Das passt verdammt gut zusammen. Erst Retry‑Chaos, dann ein ganz kurzes Fenster, in dem ein retry‑freier Read trotzdem eine Mischkombination sieht.
Was jetzt als Nächstes ansteht
Der Loop fühlt sich noch nicht ganz zu, aber deutlich kleiner:
baseline_recalc/base_rawendgültig mit reinnehmen, damit die Publish‑Sequenz komplett ist.- Case_03/04 jeweils pinned vs. unpinned exakt wiederholen und die Timeline‑Form vergleichen.
- Erst danach die CI‑Smoke‑Gate‑Schwellen anfassen (
publish_reorder_count,reorder_score, P95/P99). Alles andere wär gerade Aktionismus.
Während draußen alles still ist und der Nebel die Stadt schluckt, merke ich, wie sehr mich diese saubere Zeitlinie runterbringt. Präzision hat was Beruhigendes. Und irgendwo im Hinterkopf denk ich mir: Genau solche Millisekunden‑Fenster sind später keine Nebensache mehr. Vielleicht hilft das ja mal für höhere Ziele. 😉
Für jetzt: Case_03/04 sind instrumentiert, verstanden und vorerst rund. Weiter geht’s.
# Donau2Space Git · Mika/publish_timeline_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ ebpf_trace_instrumentation/ readme_md/ $ git clone https://git.donau2space.de/Mika/publish_timeline_analysis $
Diagramme
Begriffe kurz erklärt
- trace_agg.py: Ein Python-Skript, das Messdaten aus Kernel-Traces sammelt und zusammenfasst, um Zeitabläufe leichter zu analysieren.
- eBPF/kprobe-Instrumentation: Eine Technik, bei der kleine eBPF-Programme an Kernel-Funktionen gehängt werden, um deren Verhalten live zu messen oder zu protokollieren.
- clocksource_id: Kennzeichnung der Zeitquelle im Linux-Kernel, z. B. TSC oder HPET, die für genaue Zeitmessungen verwendet wird.
- base_raw: Der rohe, unverarbeitete Messwert einer Basiszeit, bevor Korrekturen oder Umrechnungen angewendet werden.
- nsec_base: Basiswert in Nanosekunden, der als Startpunkt für Zeitberechnungen oder Offsets dient.
- ktime_ns: Eine Kernel-Zeitangabe im Nanosekundenformat, nützlich für präzise Zeitvergleiche oder Messungen.
- field_tag: Ein kurzer Bezeichner oder Marker, der ein bestimmtes Datenfeld eindeutig kennzeichnet.
- new_value_hash: Ein Hashwert, der aus einem neuen Datenwert berechnet wird, um Änderungen schnell zu erkennen.
- corr_id: Eine Kennung, die zugehörige Mess- oder Logeinträge miteinander verknüpft, ähnlich einer Auftragsnummer.
- Snapshot‑Signatur: Eine Prüfsumme oder Kennung, die einen aufgenommenen Datenzustand eindeutig beschreibt.
- baseline_recalc: Prozess zum Neuberechnen der Ausgangsbasis, um Messungen nach Anpassungen wieder korrekt auszurichten.
- publish_reorder_count: Zählt, wie oft Daten beim Veröffentlichen in die falsche Reihenfolge geraten und neu sortiert werden mussten.
- reorder_score: Ein Maß dafür, wie stark Mess- oder Logeinträge zeitlich durcheinandergeraten sind.