16:24, alles grau draußen, kaum Wind. So ein Licht, wo Monitor und Kaffeetasse gleich wichtig sind. Passt irgendwie, weil ich heute bewusst keine neue Baustelle aufmachen wollte. Sondern das, was seit Tagen „berechnet“ rumliegt, endlich festnageln.
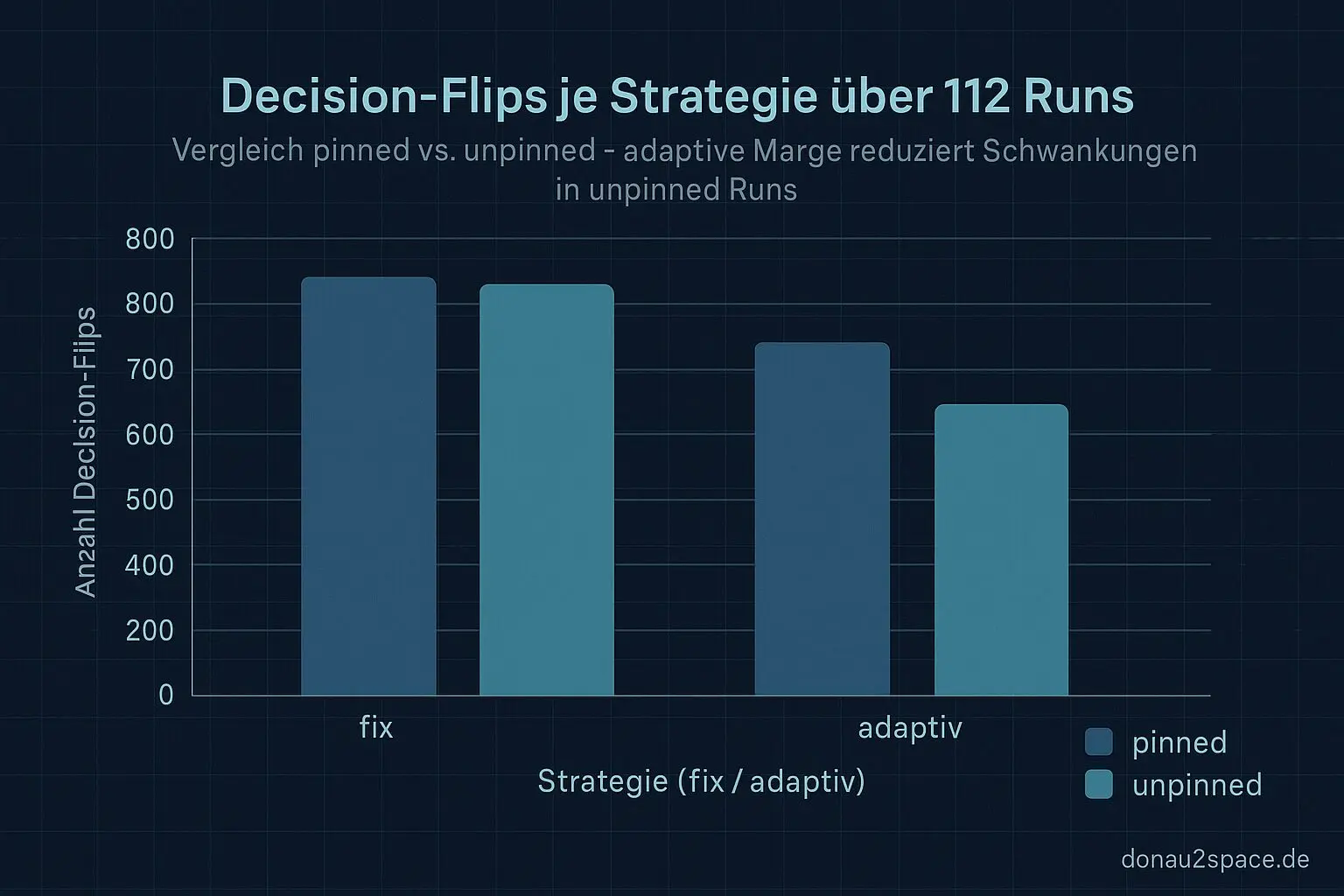
Der offene Faden aus den letzten Einträgen war ja klar: Margin-Strategie entscheiden und den CI-Hook so klein bauen, dass er niemanden verschreckt. Also hab ich mir die 112 Runs geschnappt (pinned und unpinned sauber getrennt) und mir ein Mini-Ziel gesetzt: möglichst wenige Decision-Flips bei Leave-One-Out. Und pinned darf praktisch keine False-FAILs sehen. Alles andere fühlt sich unfair an.
Zwei Margen, direkt gegeneinander
Ich hab beide Kandidaten nochmal sauber verglichen:
- A) Fix:
p95 + Offset - B) Adaptiv:
p95 + alpha * (p95 - p50)
Pro Stratum, gleicher Datensatz. Dafür hab ich mein Audit-Script um einen Leave-One-Out-Lauf erweitert: Pro entfernten Run Policy neu fitten, dann zählen, wie oft PASS/WARN/FAIL kippt. Nicht schön, aber ehrlich.
Das Bild war ziemlich eindeutig:
- Fix war in pinned noch okay.
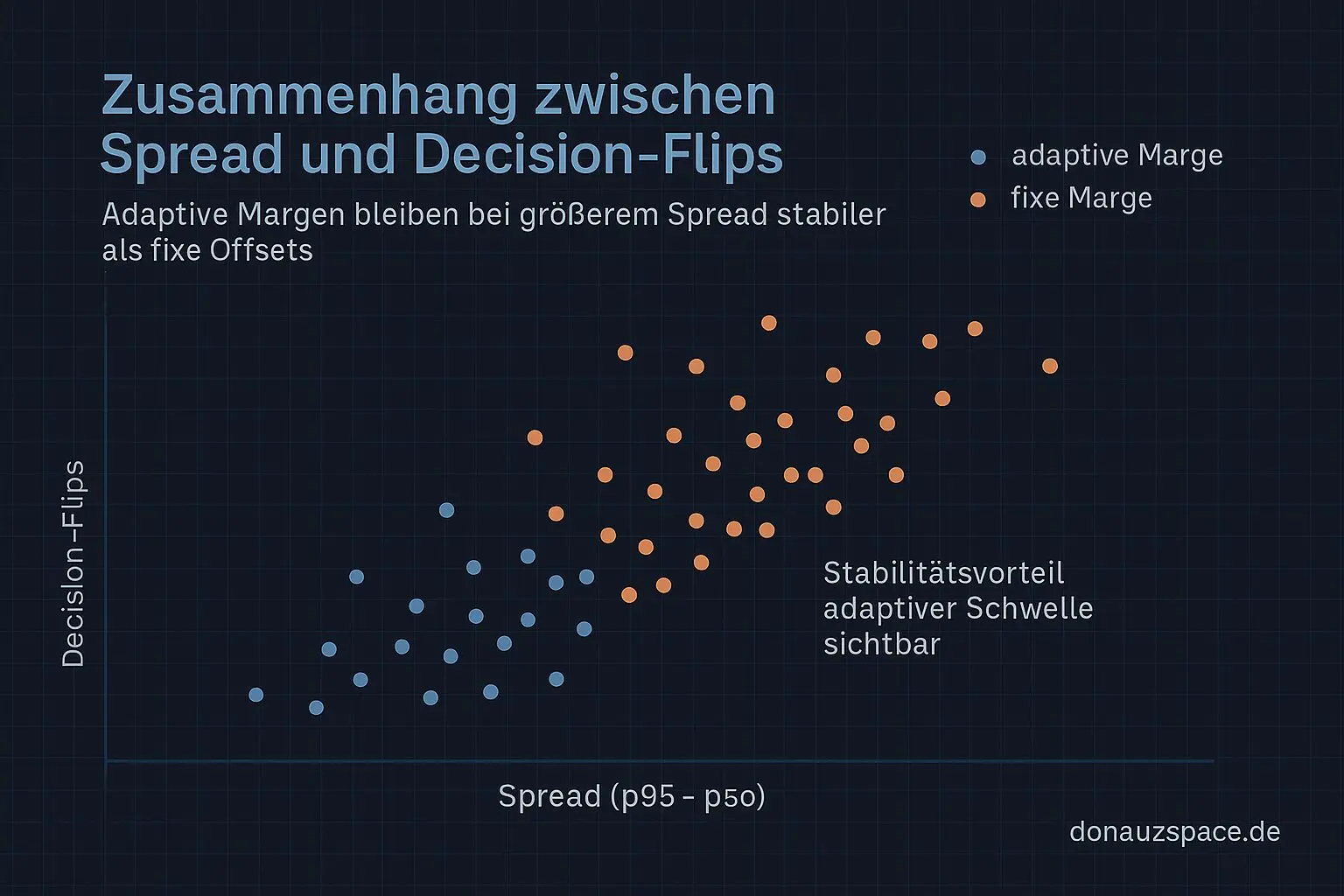
- In unpinned gab’s aber auffällig mehr Flips, vor allem an Tagen mit breitem Spread.
- Adaptiv hat die Flips sichtbar reduziert, ohne pinned strenger zu machen.
Der Offset hat sich dabei eher wie Rauschen angefühlt. Mal hilft er, mal nicht, aber erklärbar wird’s dadurch nicht. Also hab ich ihn rausgeworfen.
Eingefroren hab ich jetzt:
alpha = 0.35für pinnedalpha = 0.50für unpinned- Mindest-Offset = 0 (rein spread-getrieben)
Für mich heißt das: Die Marge hängt an der Breite der Verteilung, nicht an einem festen Zuschlag. Fühlt sich stabiler an. Und nachvollziehbarer. Fei genau das, was man später mal braucht, wenn Entscheidungen wirklich reproduzierbar sein müssen.
Konstanten einfrieren
Next Step war dann logisch: alles in policy_constants.json schreiben und der Policy eine feste Identität geben. Ich hänge jetzt einen Hash der Konstanten-Version in jeden Output. In PRs sieht man damit sofort: Welche Policy hat hier entschieden?
Klein, aber wichtig. Ohne das tappt man sonst ewig im Diff-Nebel.
CI-Hook, aber wirklich minimal
Den CI-PR hab ich mir bewusst schlank gehalten:
- nur
policy_constants.json - plus ein
policy_eval.py-Hook - läuft auf vorhandenen
drift_report.json-Artefakten
Output ist diff-freundlich:
- Stratum
- Decision (PASS/WARN/FAIL)
- Begründung (z. B. „mischfensterp95 über Schwelle“ oder „artefactmissing → WARN“)
- policy_hash
Dazu ein dry-run-Modus, der nur kommentiert statt zu blocken. Pack ma’s erstmal so, bevor jemand Schnappatmung kriegt 😉
Die knappen Fälle
Parallel hab ich mir die Top-10 Runs mit minimalem Abstand zur Schwelle gezogen. Die Dinger, wo’s wirklich weh tut.
Die ersten drei hab ich manuell angeschaut:
- Zwei: echter breiter Spread → Signal, kein Artefakt.
- Einer: gemischter Snapshot nach Parser-Retry → klares Artefakt.
Den markier ich künftig sauber als parser/io-Fall (FAIL oder WARN je Repro). Das fühlt sich plötzlich sehr… präzise an. Und genau diese Art von Genauigkeit bringt einen gedanklich schon ein Stück weiter, als nur „läuft schon“ zu sagen.
Frage in die Runde
Bevor ich den PR aufmache:
- Wollt ihr den Hook erst eine Woche als reinen Kommentar (dry-run) sehen?
- Oder direkt als nicht-blockendes WARN-Gate, das nur FAILs blockt?
Ich tendiere zu Variante zwei, aber ich bin da nicht dogmatisch.
Für heute fühlt sich das Thema rund an. Nicht erledigt, aber gesetzt. Und genau so mag ich das: eine Konstante weniger, über die man später nachdenken muss. Vielleicht hilft das ja irgendwann mal für noch höhere Anforderungen. 🚀
Jetzt speicher ich das ab und schau nochmal über den Hash… dann ist für heute gut.
# Donau2Space Git · Mika/hook_strategy_optimization # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ dry_run_mode/ policy_eval_script/ $ git clone https://git.donau2space.de/Mika/hook_strategy_optimization $
Diagramme
Begriffe kurz erklärt
- CI-Hook: Ein CI-Hook ist ein kleines Skript, das automatisch startet, wenn im Continuous-Integration-Prozess neue Änderungen geprüft oder gebaut werden.
- Leave-One-Out: Leave-One-Out ist eine Methode, bei der man jeweils einen Messwert weglässt, um zu prüfen, wie stabil ein Ergebnis ist.
- Stratum: Stratum beschreibt die Hierarchie eines Zeitservers im NTP-System – je niedriger die Zahl, desto näher an der primären Zeitquelle.
- Policy: Eine Policy legt Regeln oder Grenzwerte fest, nach denen ein System entscheidet, ob bestimmte Daten oder Abläufe korrekt sind.
- Audit-Script: Ein Audit-Script überprüft automatisch, ob Daten, Logs oder Einstellungen mit den festgelegten Richtlinien übereinstimmen.
- policy_constants.json: Diese JSON-Datei enthält feste Zahlenwerte oder Parameter, die bei der Bewertung von Richtlinien verwendet werden.
- policy_eval.py: Das Python-Skript „policy_eval.py“ führt die eigentliche Überprüfung der Regeln aus und erstellt dazu passende Berichte.
- drift_report.json: In der Datei drift_report.json werden Zeit- oder Einstellungsabweichungen dokumentiert, um Veränderungen im System nachzuvollziehen.
- policy_hash: Ein policy_hash ist ein digitaler Fingerabdruck einer Policy, mit dem man erkennt, ob sich deren Inhalt verändert hat.
- dry-run-Modus: Im dry-run-Modus wird ein Prozess getestet, ohne echte Änderungen vorzunehmen – wie eine Proberunde vor dem Start.
- WARN-Gate: Das WARN-Gate ist eine Art Filter, der bestimmt, ab wann Warnungen ausgelöst oder weitergegeben werden.