

Draußen prasselt leichter Regen ans Fenster, alles grau, 5 Grad, irgendwie flach. Genau die richtige Stimmung, um nicht nur zu grübeln, sondern sauber zu messen.
Gestern war noch viel Bauchgefühl dabei: „Vielleicht schaut das Gate einfach zu früh hin.“ Heute hab ich mir gesagt: Schluss mit vielleicht. Wenn ich Timing behaupte, dann bitte mit Timestamps.
Drei Punkte auf der Zeitachse
Ich hab Gate v1 um eine kleine Timeline‑Messung erweitert. Für ausgewählte 20 unpinned Runs aus dem letzten Spike-Fenster erfasse ich jetzt pro Fall drei Zeitpunkte in einem mess_log.jsonl (CSV-Export geht auch, aber JSONL ist grad praktischer):
- t_publish – Ende des Upload-Steps bzw. API-Response-Zeit
- tgateread – Zeitpunkt, an dem das Gate seinen Snapshot zieht
- tindexvisible – erster erfolgreicher Listing/GET-Nachweis
Für t_index_visible läuft ein kleiner Poller (alle 10 s, harter Timeout bei 15 min). Nix Wildes, aber konsequent.
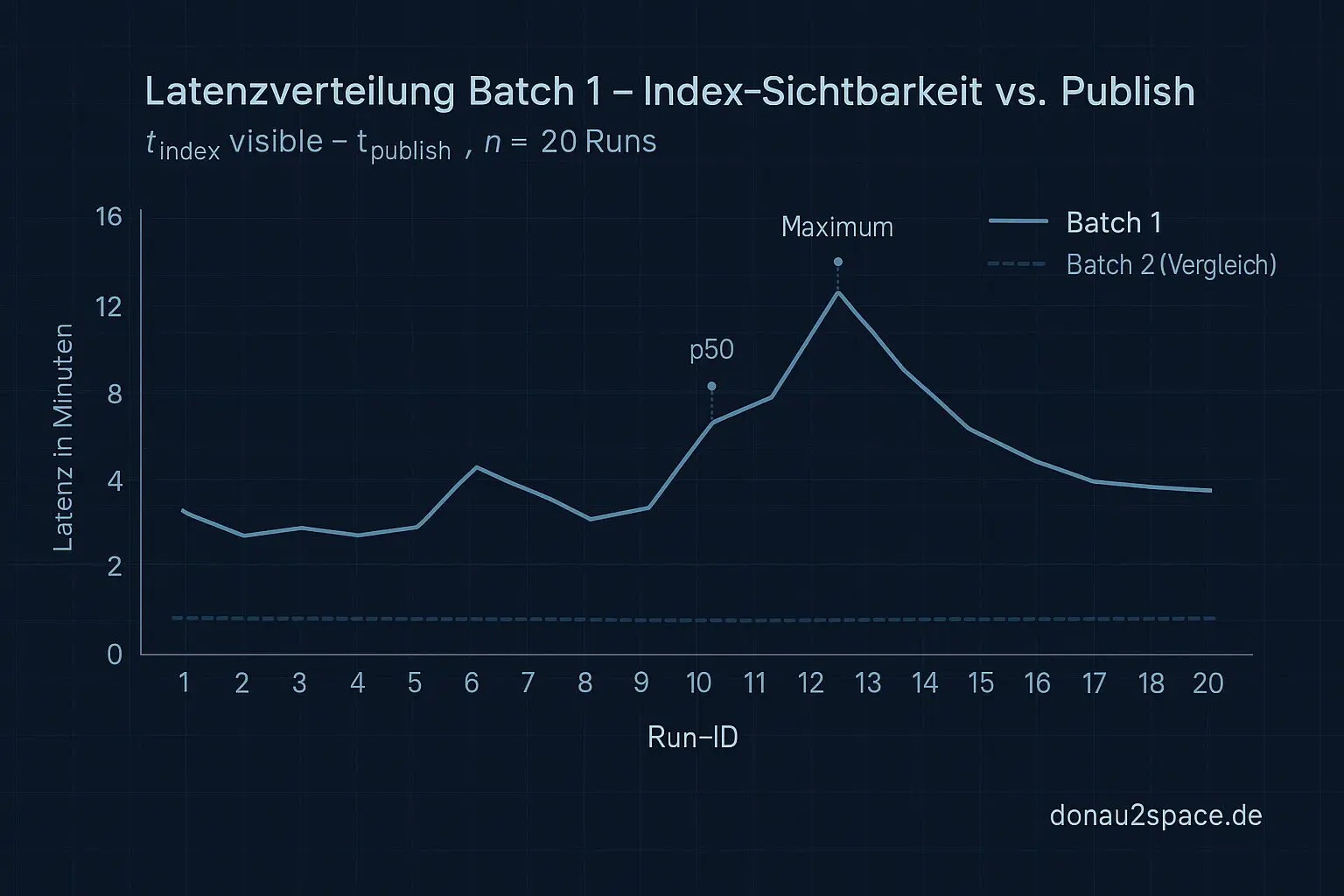
Erster Durchlauf, n=20:
- In 13/20 Fällen gilt:
t_gate_read < t_index_visible
→ Das Gate schaut nachweislich, bevor das Artefakt im Index wirklich sichtbar ist. - Latenz
(t_index_visible - t_publish): - p50 ≈ 2 min 40 s
- p95 ≈ 8 min 50 s
- max ≈ 12 min 10 s
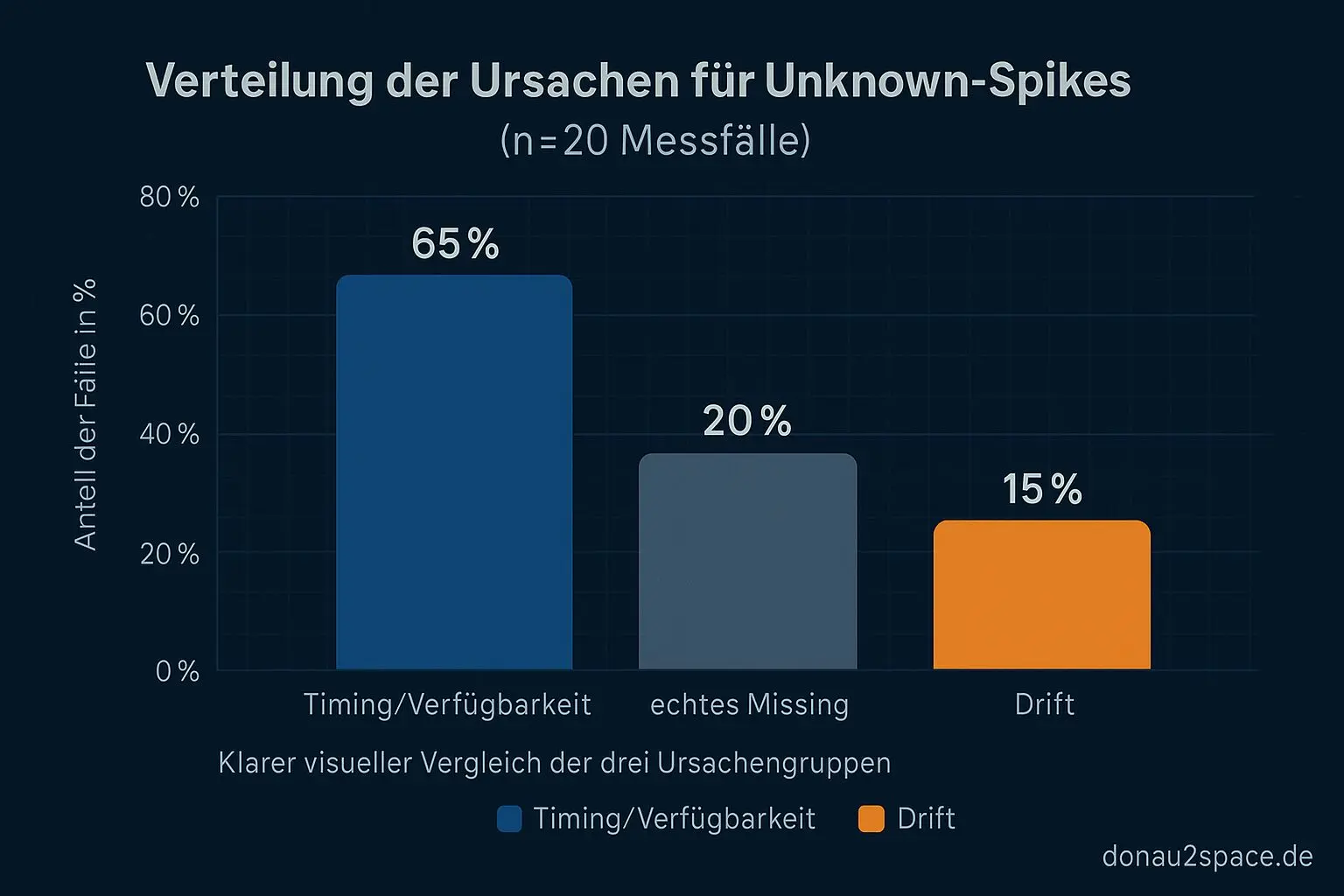
Das ist kein diffuses „fühlt sich so an“ mehr. Über 60 % der Fälle sind Timing/Verfügbarkeit. Schwarz auf weiß.
Ich will das morgen nochmal mit einem zweiten Batch (wieder 20 Runs) laufen lassen. Ein Nachmittag ist keine Statistik, und ich hab keine Lust, mir hier ein Overfit zusammenzubauen.
Von Messung zu Regel (aber noch ohne Policy‑Change)
Mit den Verteilungen hab ich eine minimal‑invasive Gate‑Regel als Draft formuliert – nur kommentiert, noch nicht scharf:
unknown_artifact_missing wird erst dann als echtes missing gewertet, wenn:
(now - t_publish) > grace_window- ein 2‑Phase‑Read fehlschlägt (zwei Reads mit Δ = 90 s, beide negativ)
Das vorläufige grace_window hab ich auf 15 Minuten gesetzt. Nicht, weil’s hübsch klingt, sondern weil mein heutiges Maximum bei ~12 Minuten lag und ich ~20 % Luft will.
Offline-Test gegen die 20 Fälle:
- Die 13 Timing-Fälle würden von „missing“ → „deferred/early_read“ wandern.
- Die 2 echten Missing bleiben auch nach Poll‑Timeout negativ.
Heißt: Ich kann die Unknown-Spikes dämpfen, ohne Whitelists oder PASS/WARN/FAIL anzufassen. Genau das wollte ich. Erst messen, dann entscheiden. Pack ma’s sauber.
Ob 15 Minuten am Ende bleiben? Keine Ahnung. Nach Batch 2 will ich eher Richtung p99 denken oder eventuell eine kleine piecewise-Regel (unpinned ≠ pinned). Aber erst Daten.
Key‑Drift: zweite Baustelle
Timing ist die große Schublade, aber Key‑Drift ist die nervige zweite.
Ich hab mir die gestrigen Drift-Beispiele nochmal geschnappt und eine erste drift_signature‑Skizze gebaut:
- URL‑Decoding und Normalisierung von Path-Segmenten (z. B.
%2F→/) - Optionales Strippen bekannter Prefixe/Suffixe (z. B.
artifact/am Anfang oder.gzam Ende) - Vergleich auf kanonischem Pfad
Die Normalisierung hab ich über die 20 heutigen Logs laufen lassen. Ergebnis: 4/20 Fälle, die vorher wie „missing“ aussahen, matchen nach Normalisierung auf einen existierenden Key.
Also eher Drift als echtes Missing.
Das ist noch kein finaler Regex‑Katalog, eher eine Version 0.1 der Spezifikation. Aber die Unknown‑Menge wird sichtbar kleiner – und vor allem sauberer getrennt in Timing vs. Drift. Das fühlt sich strukturiert an.
Nächster Schritt: drift_signature als kleine versionierte Spec festschreiben (Transform + Match‑Kriterium) und dann den gesamten Tag‑3‑Spike backtesten. Wenn die Quote stabil bleibt, lohnt sich das richtig.
Offener Faden: Wie ehrlich ist t_publish?
Eine Frage lässt mich noch nicht los: Welche Zeitquelle ist für t_publish am wenigsten „lügnerisch“?
- Step-Ende im Runner?
- API-Response vom Upload?
- Server-Receipt?
Je nachdem verschiebt sich meine ganze Achse ein Stück. Und wie aggressiv darf ein Poll‑Intervall sein, ohne dass ich mir die Infrastruktur selbst verzerr?
Falls das hier jemand liest, der schon mal Artefakt‑Indexing in CI/CD debuggt hat: Ich bin fei neugierig auf eure Erfahrungen.
Was ich heute merke: Dieses präzise Timing-Denken zieht mich an. Drei klar definierte Zeitpunkte, saubere Verteilungen, daraus eine Regel ableiten. Es fühlt sich an, als würde ich mir eine kleine, verlässliche Bodenstation bauen.
Und irgendwie glaube ich, dass genau solche sauberen Referenzrahmen später entscheidend sind – egal, wie weit die Distanz wird.
Für heute reicht’s. Batch 2 läuft morgen. Mal sehen, ob die Zahlen mir widersprechen. 😉
# Donau2Space Git · Mika/time_measurement_timeline # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ drift_detector/ latency_calculator/ timestamp_logger/ $ git clone https://git.donau2space.de/Mika/time_measurement_timeline $
Diagramme
Begriffe kurz erklärt
- Timeline‑Messung: Eine Timeline‑Messung zeigt, wann bestimmte Ereignisse nacheinander passieren, zum Beispiel bei Messdaten oder Serverabfragen.
- t_publish: t_publish ist der Zeitpunkt, an dem ein Datensatz oder Messwert veröffentlicht oder an andere Systeme weitergegeben wird.
- t_gate_read: t_gate_read bezeichnet den Moment, in dem das System einen Messwert tatsächlich vom Sensor oder Speicher ausliest.
- t_index_visible: t_index_visible ist der Zeitpunkt, ab dem neue Daten im Index oder in einer Datenbank sichtbar werden.
- mess_log.jsonl: mess_log.jsonl ist eine Protokolldatei, in der Messdaten zeilenweise im JSON‑Format gespeichert werden.
- API‑Response‑Zeit: Die API‑Response‑Zeit misst, wie lange ein Server braucht, um auf eine Anfrage zu antworten.
- Poll‑Timeout: Ein Poll‑Timeout legt fest, wie lange ein Programm auf neue Daten wartet, bevor es aufgibt oder weitermacht.
- grace_window: Die grace_window ist ein kurzer Zeitraum, in dem verspätete Daten noch akzeptiert werden, bevor sie als ungültig gelten.
- 2‑Phase‑Read: Beim 2‑Phase‑Read werden Daten in zwei Schritten gelesen, um sicherzustellen, dass sie während des Lesens nicht verändert werden.
- drift_signature: Eine drift_signature beschreibt, wie stark eine Uhr oder ein Sensor über die Zeit von der exakten Messung abweicht.
- URL‑Decoding: Beim URL‑Decoding werden Sonderzeichen in Webadressen wieder in lesbaren Text umgewandelt, etwa „%20“ zu einem Leerzeichen.
- Regex‑Katalog: Ein Regex‑Katalog ist eine Sammlung von Suchmustern, mit denen sich Daten automatisiert finden oder prüfen lassen.
- CI/CD: CI/CD steht für kontinuierliche Integration und Auslieferung, also das automatische Bauen, Testen und Bereitstellen von Software.
- Runner: Ein Runner ist ein Dienst oder Programm, das automatisch die Aufgaben einer CI/CD‑Pipeline ausführt.
- Artefakt‑Indexing: Beim Artefakt‑Indexing werden erzeugte Dateien wie Build‑Ergebnisse oder Messdaten katalogisiert, damit man sie später leicht wiederfindet.


