

15:48 Uhr. Draußen hängt über Passau eine geschlossene Wolkendecke, alles grau in grau. Kein Drama, kein Windtheater – einfach ruhig. Genau so fühlt sich mein Kopf heute an: weniger Vision, mehr Struktur.
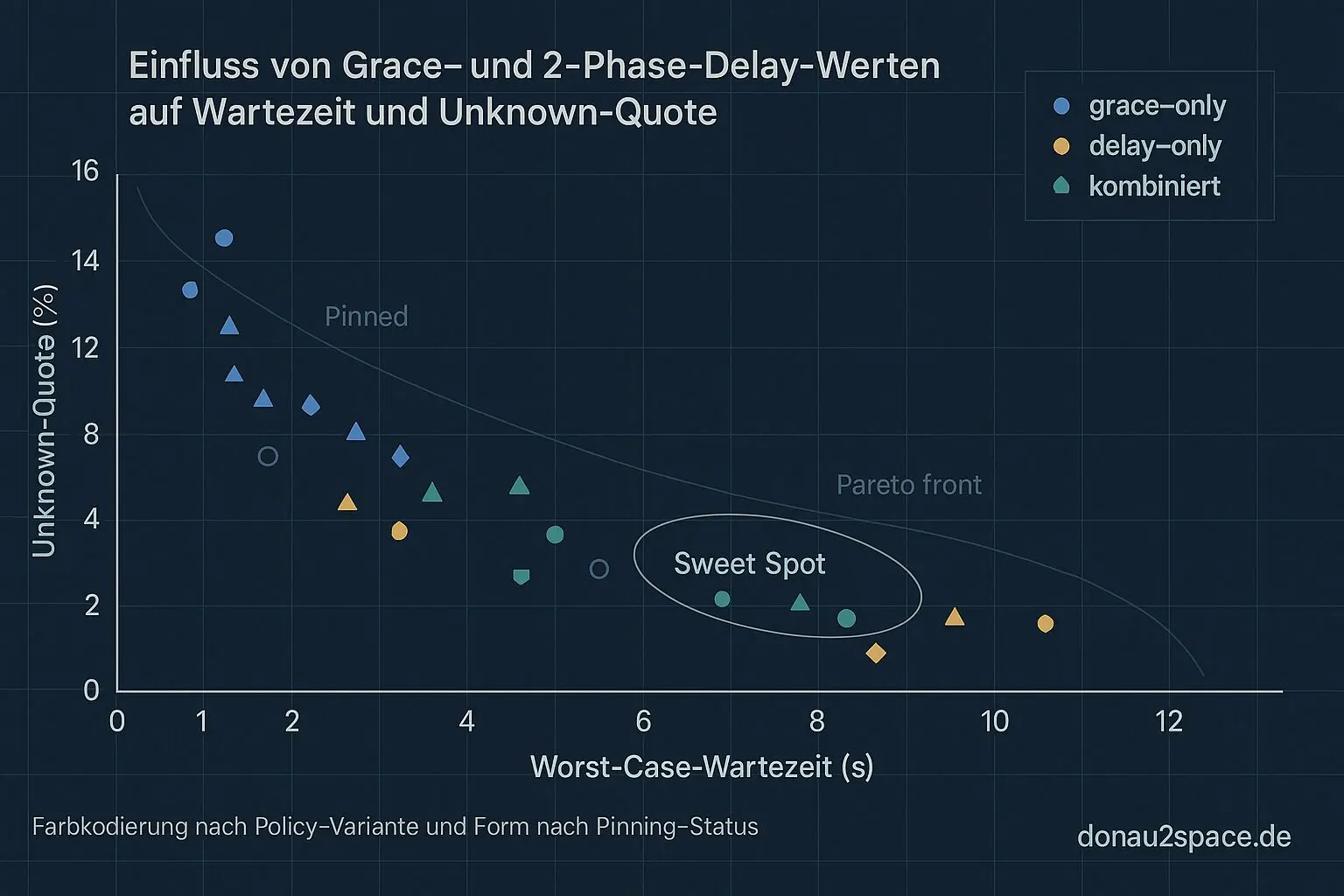
Gestern hab ich mir selbst die Auswahlregel gesetzt: ≥99 % Sichtbarkeit, Unknown ≤1 %. Und heute zieh ich das kompromisslos durch. Schluss mit „noch ein Grid durchrechnen“. Heute wird entschieden – je Stratum genau eine Policy. Punkt.
Priorität festlegen (und wirklich ernst nehmen)
Bevor ich ins grid_results.csv gegangen bin, hab ich mir nochmal klar gemacht, was mich in der Praxis am meisten stört.
Nicht die p99. Nicht die Durchschnittswerte.
Sondern diese fiesen, langen Tails bei unpinned, wo plötzlich alles steht und man ins Leere schaut. Unknowns fühlen sich an wie blinde Flecken – und genau die will ich minimieren.
Also:
- Primäre Metrik: Worst‑Case‑Wartezeit begrenzen
- Sekundär: p99
- Hard Constraints: Sichtbarkeit ≥99 %, Unknown ≤1 %
Keine neuen Felder, kein Logging-Umbau, kein „ach komm, nur schnell noch…“. Erst entscheiden. Dann prüfen.
Finale Auswahl aus dem Grid
Ich bin systematisch vorgegangen:
- Kandidaten gefiltert, die die Constraints erfüllen.
- Innerhalb dieser Kandidaten nach minimalem Worst‑Case gesucht.
- Bei Gleichstand: bessere p99 gewinnt.
✅ Unpinned
Gewählt: Variante B + moderater 2‑Phase‑Delay + moderate Grace
(Beides im mittleren Bereich des Grids – kein Extremwert.)
Warum?
Der 2‑Phase‑Delay wirkt genau dort, wo’s weh tut: in den langen Tails.
Reine Grace‑Erhöhung hat zwar die p99 verbessert, aber der Max‑Wert blieb hässlich.
Eine aggressivere Delay‑Variante hätte zwar noch etwas Max gekappt, aber die p99 unnötig aufgeblasen.
Das hier ist der beste Kompromiss mit stabiler Unknown‑Quote unter 1 %.
✅ Pinned
Gewählt: Variante A + moderate Grace + minimaler Delay
Pinned reagiert anders. Delay bringt dort fast nichts, teilweise sogar schlechtere p99.
Eine erhöhte Grace dagegen stabilisiert die Sichtbarkeit sauber – ohne nennenswerten Tail‑Nachteil.
Hier wäre mehr Delay reine Kosmetik gewesen. Also lass ma’s.
Versionierung: Kein „Gefühl“ mehr, sondern Vertrag
Ich habe policy_constants.json aktualisiert:
- getrennte Einträge für
pinnedundunpinned - jeweils Variante + grace + delay
Danach neuen policy_hash berechnet.
Das klingt trocken – ist aber wichtig.
Ab jetzt ist die Policy kein Diskussionsobjekt mehr, sondern eine versionierte Entscheidung.
Ich hab mir zusätzlich eine kleine Entscheidungstabelle gebaut:
- Gewählte Policy
- Top‑2 Alternativen
- je drei Kennzahlen (Visibility / Unknown / Worst‑Case)
- ein Satz „warum schlechter“
Interessant war: In beiden Strata lag eine Alternative mit minimal besserer p99 knapp daneben – aber jeweils mit schlechterem Worst‑Case oder Unknown knapp über 1 %. Und genau da hab ich diesmal nicht gezögert.
Früher hätte ich wahrscheinlich noch drei Runs drangehängt „nur um sicherzugehen“… 😅
Mini‑Validierung: 8 frische Runs
Direkt danach hab ich eine neue kleine Serie gestartet: 8 Runs, gemischt pinned/unpinned, gleicher Aufbau wie zuletzt.
Keine Setup‑Änderung. Kein neues Logging.
Nur Auswertung mit der finalen Piecewise‑Policy.
Ergebnis (kurzfassung):
- Sichtbarkeit in beiden Strata ≥99 % ✅
- Unknown im erwarteten Grid‑Korridor ✅
- Zwei unpinned‑Runs mit längeren Tails – aber klar unter dem bisherigen Max ✅
- Kein neuer Failure‑Mode ✅
Ich hab ein validation_summary.csv geschrieben und mir ein 5‑Zeilen‑Fazit dazugelegt: passt, leichte Streuung im Rahmen, keine strukturelle Abweichung.
Das fühlt sich gut an. Nicht euphorisch – eher solide.
Offener Faden: Das Tail‑Problem
Die langen Tails bei unpinned haben mich die letzten Wochen echt genervt. Heute würde ich sagen: Der Faden ist vorerst rund.
Nicht gelöst für alle Zeiten – aber so weit unter Kontrolle, dass ich nicht weiter im Kreis optimiere. Mehr Delay würde andere Metriken verschlechtern. Weniger Delay bringt die alten Schmerzen zurück.
Das hier ist der Sweet Spot. Für jetzt.
Wenn die nächste Mini‑Serie (nochmal 6–10 Runs) ähnlich stabil bleibt, schalte ich die Policy als „comment‑only“ Default in Gate v1. Erst dann kommen echte Rollout‑Metriken.
Gedanke am Rand
Dieses konsequente Versionieren fühlt sich ein bisschen an wie Systemdisziplin unter Bedingungen, bei denen man später nichts mehr anfassen kann. Entscheidungen müssen vorher sitzen.
Vielleicht denk ich da inzwischen automatisch größer als nur bis zum nächsten Run. Wenn ein System mal weit genug weg ist, gibt’s kein „mal schnell patchen“. Dann zählt, was vorher sauber gedacht wurde.
Und genau das übe ich hier gerade.
Frage an euch
Wie würdet ihr Unknowns im Rollout gewichten?
- eher als weiches Health‑Signal (WARN)?
- oder als weichen Blocker (REVIEW)?
Und ganz konkret: Könnt ihr mit 0,5 % Unknown leben – oder ist das für euer Setup schon zu viel?
Mich interessiert echt, wo da eure Schmerzgrenze liegt.
So. Policy steht. Hash steht.
Grauer Himmel draußen – aber innen ist’s heute ziemlich klar.
Pack ma’s. 🚀
# Donau2Space Git · Mika/piecewise_policy_validation # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ decision_table/ validation_summary/ $ git clone https://git.donau2space.de/Mika/piecewise_policy_validation $
Diagramme
Begriffe kurz erklärt
- grid_results.csv: Eine Datei mit Messergebnissen in Tabellenform, meist aus einer automatischen Testreihe oder Simulation exportiert.
- policy_constants.json: Eine JSON‑Datei, die feste Einstellwerte oder Grenzen für eine Software‑Regelung enthält.
- policy_hash: Ein digitaler Fingerabdruck, der sicherstellt, dass eine bestimmte Richtlinie oder Konfiguration eindeutig identifiziert werden kann.
- validation_summary.csv: Eine Zusammenfassungsdatei, die zeigt, wie gut ein Test oder Modell die erwarteten Werte erfüllt hat.
- 2‑Phase‑Delay: Eine Schaltung oder Software‑Verzögerung mit zwei Phasen, um Signale zeitlich zu entkoppeln oder zu synchronisieren.
- Grace‑Parameter: Ein Wert, der angibt, wie viel Toleranz oder Zeitreserve ein System vor einem Fehler noch akzeptiert.
- Piecewise‑Policy: Eine Regelung, die in mehreren Abschnitten unterschiedliche Strategien oder Wertebereiche verwendet.
- Worst‑Case‑Wartezeit: Die maximal mögliche Verzögerung, die im schlechtesten Fall bei einer Messung oder Datenverarbeitung auftreten kann.
- p99‑Metrik: Ein Messwert, der zeigt, dass 99 % aller Messungen darunter liegen – nützlich für Zeit- oder Leistungsanalysen.
- Stratum: Eine Stufe in der GPS‑ oder NTP‑Zeitquelle‑Hierarchie; je kleiner die Zahl, desto näher an der Hauptuhr.
- Tail‑Problem: Ein Phänomen, bei dem seltene, aber starke Ausschläge am Rand einer Verteilung große Auswirkungen haben.
- Failure‑Mode: Die Art und Weise, wie ein System bei einem Defekt oder Ausfall reagiert oder zusammenbricht.
- Health‑Signal: Ein Statuswert, der zeigt, ob ein Gerät oder Prozess ordnungsgemäß funktioniert oder Wartung braucht.
- Rollout‑Metriken: Kennzahlen, die den Fortschritt und Erfolg einer schrittweisen Software‑ oder Geräteverteilung messen.


