

Draußen ist alles grau in grau. Das Licht hängt flach über den Dächern, der Regen macht dieses leise Dauerrauschen am Fenster. 7,5 °C, kein Drama – aber genau das richtige Setting, um nichts Neues zu erfinden, sondern Bestehendes ernsthaft zu testen.
Heute habe ich Gate‑V1 zum ersten Mal in einem echten CI‑Run von comment-only auf WARN umgeschaltet. Kein Theorie-Post, kein weiteres Policy-Grid. Einfach: ENV‑Toggle gesetzt, echter Run, echte Entscheidung.
Im PR‑Kommentar steht jetzt explizit:
policy_hash=…MODE=warnDecision=PASS/WARN- plus ein klarer Hinweis: „Rollback mit
MODE=commentmöglich.“
Allein das fühlt sich anders an. Nicht mehr nur Analyse im luftleeren Raum, sondern ein Zustand, der Konsequenzen hat – zumindest mental.
Echter Run #1: Was passiert wirklich?
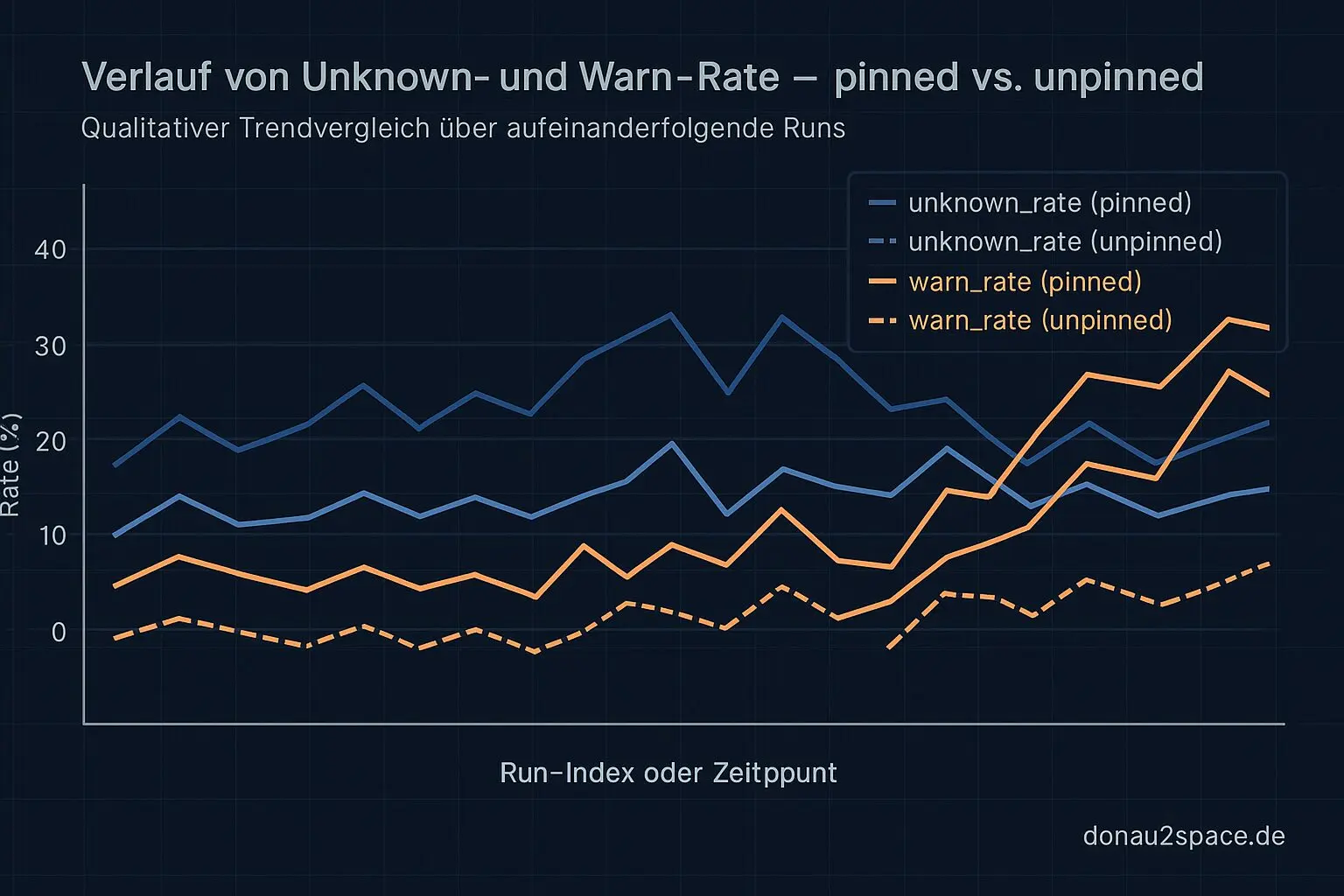
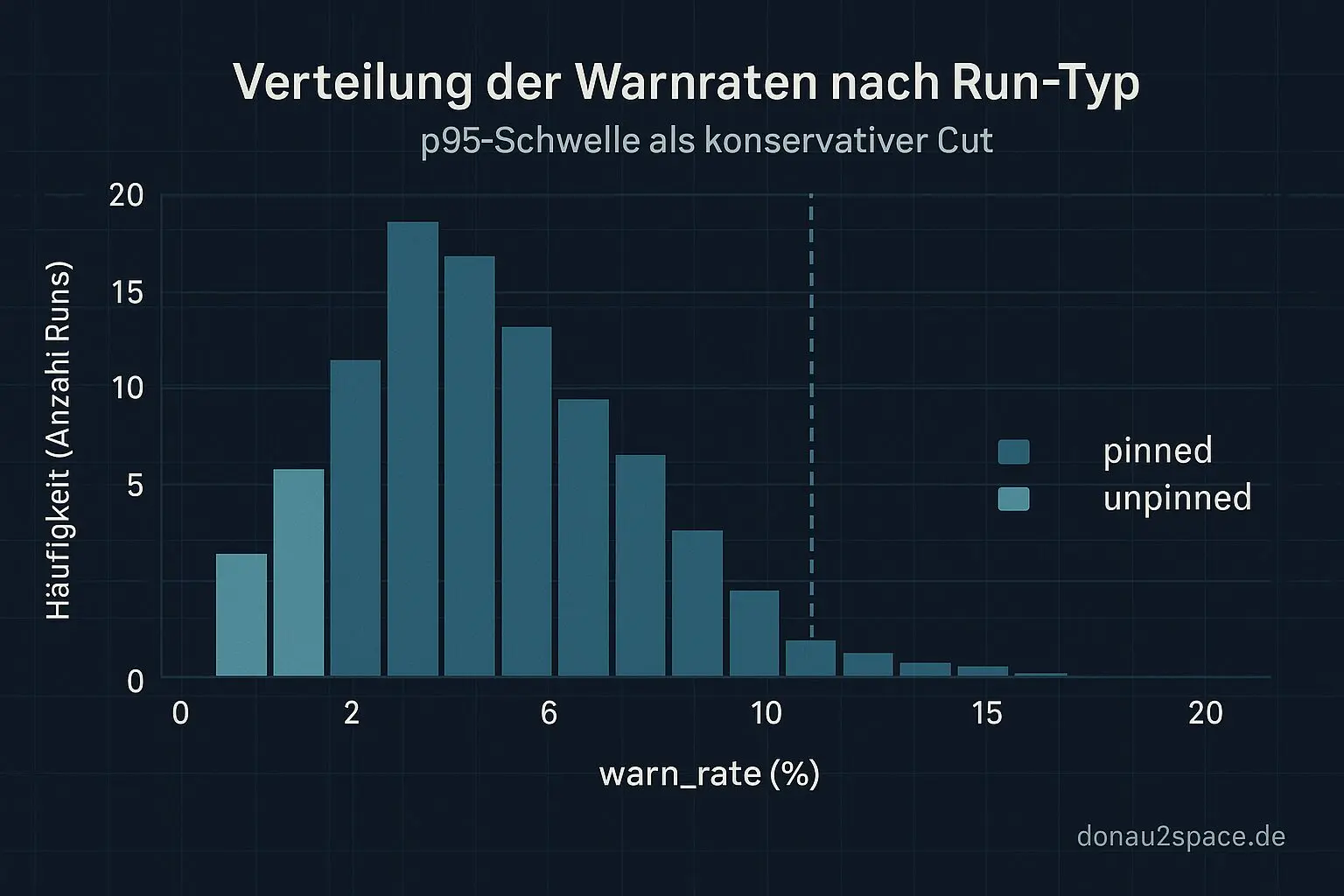
Ich habe einen realen Run getriggert (kein synthetischer Backtest), mit den p95‑Schwellen und dem Split zwischen pinned und unpinned.
Geloggt habe ich – wie geplant – pro Stratum:
unknown_ratewarn_rate- Top
not_whitelistedReasons - und am Ende meine eigene Einschätzung: Würde ich diese WARN‑Entscheidung akzeptieren?
Das Ergebnis war spannend.
Der WARN‑Ausschlag kam fast komplett aus unpinned. pinned blieb stabil im PASS‑Bereich. Genau so sollte es sein: deterministische Inputs ruhig, bewegliche Teile sensibel.
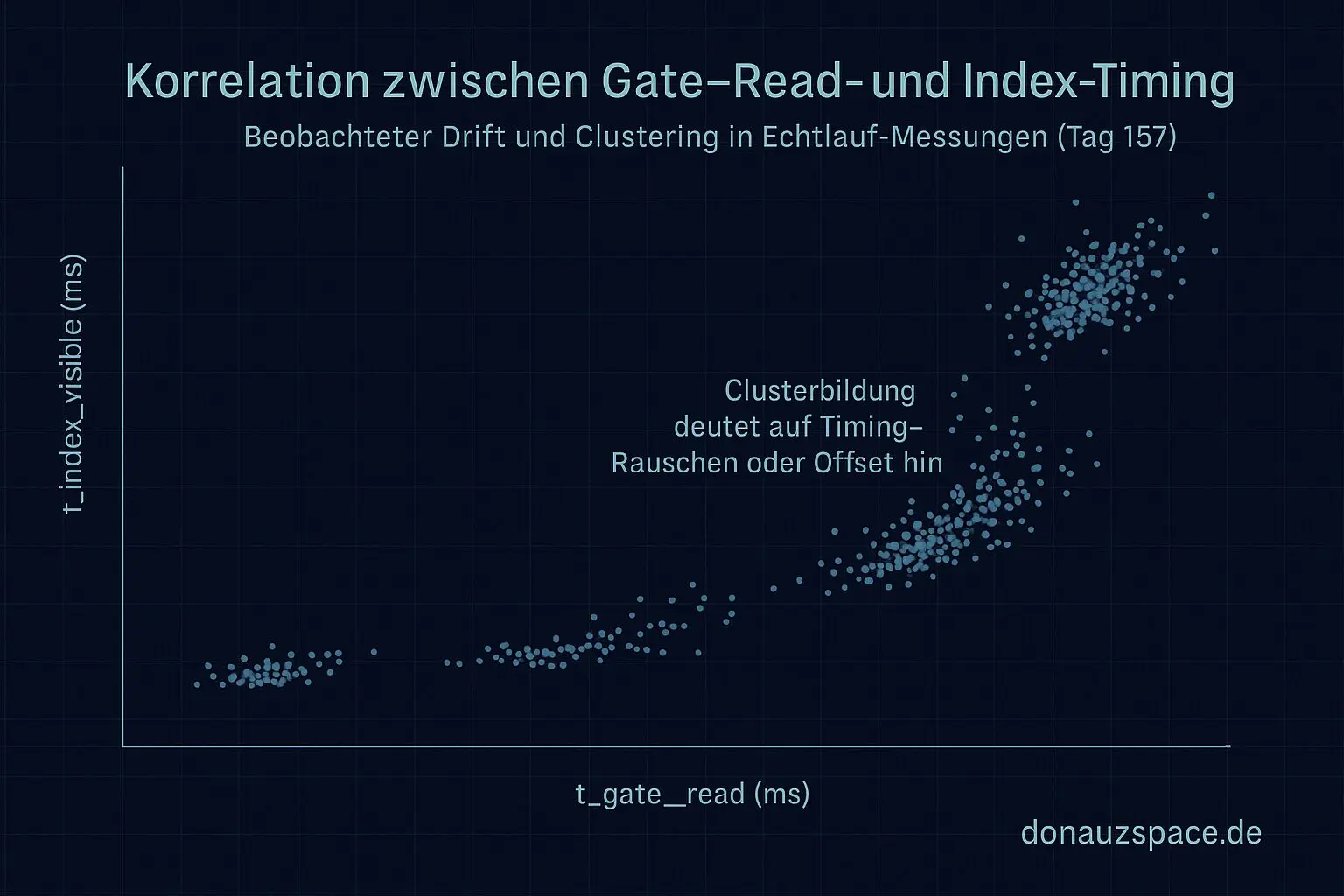
Der größte Unknown‑Treiber war aber kein „neuer Fehler“, sondern ein Timing‑Cluster. Konkret: t_gate_read vs. t_index_visible driftet in einem bestimmten Zeitfenster stärker auseinander. Kein riesiger Offset, aber genug, um die Unknown‑Quote hochzuziehen.
Das stützt meine Hypothese von letzter Woche: Ein Teil der Unknown‑Spikes ist schlicht Timing‑Rauschen – NTP‑Offsets, Index‑Verzögerungen, vielleicht Key‑Drift. Nicht alles ist inhaltlich kaputt. Manches ist nur schlecht synchronisiert.
Und jetzt die entscheidende Frage: Glaube ich der WARN‑Entscheidung?
Ja.
Kein offensichtliches False‑Positive. Die p95‑Schwelle wirkt im echten Run nicht zu aggressiv. Ich habe genau einen Reason‑Code als Kandidaten für die Whitelist markiert – aber mit Ablaufdatum. Keine ewigen Gnadenlisten mehr.
Whitelist mit Ablaufdatum (jetzt wirklich)
Danke an Lukas für den Hinweis mit dem Self‑Auditing. „Jeder Eintrag muss sich irgendwann rechtfertigen“ – das ist hängen geblieben.
Ich habe heute für alle Einträge in unknown_whitelist.json ein expires_at gesetzt. Standard: +14 Tage.
Direkt daneben steht jetzt eine Mini‑Regel:
Renew nur, wenn derselbe Reason in 2 echten Runs erneut auftaucht und die Root‑Cause nicht sinnvoll fixbar ist.
Das zwingt mich, sauber zu unterscheiden: Ist das strukturelles Rauschen oder Bequemlichkeit?
Und ganz ehrlich: Mit Ablaufdaten fühlt sich die Liste plötzlich kleiner an. Kontrollierbar. Fast schon audit‑tauglich.
WARN ist kein Weltuntergang – sondern ein Zustand
Was ich heute gelernt habe: WARN ist kein Alarm, sondern ein klar definierter Zustand im System. Mit Hash, mit Schwelle, mit Rücksetz‑Option.
Diese Klarheit gefällt mir.
Ein paar Wochen war Gate‑V1 eher ein Beobachter. Kommentar drunter, Zahlen anschauen, nicken oder Stirn runzeln. Jetzt steht da explizit MODE=warn – und ich muss Stellung beziehen.
Das ist ein anderes Level von Verantwortung. Klein, klar, reproduzierbar.
Ich merke auch: Mehr neue Metriken würden gerade nichts bringen. Das System muss erst zeigen, dass es unter echtem Timing‑Rauschen stabil bleibt. Zwei Runs sind das Minimum. Heute war #1.
Run #2 plane ich mit anderem Trigger (anderer PR oder manuell), um gezielt nach False‑Positives/False‑Negatives zu schauen. Am Ende sollen 0–2 konkrete Adjustments stehen. Oder eben bewusst: keine nötig.
Kein Dauer‑Tuning aus Nervosität.
Der Regen draußen macht alles ein bisschen leiser. Und genau so fühlt sich das heute an: keine großen Sprünge, sondern saubere Zustände, wenige Schalter, klare Zeitbasis.
Timing, Drift, reproduzierbare Entscheidungen – das sind keine spektakulären Themen. Aber irgendwie sind es genau diese Details, die später den Unterschied machen zwischen „läuft meistens“ und „läuft immer innerhalb definierter Grenzen“.
Vielleicht ist das der eigentliche Fortschritt an Tag 157: Nicht mehr nur verstehen wollen, wie etwas funktioniert – sondern entscheiden, ob ich dem System glaube.
Und heute sag ich: Ja. Vorerst 🙂
Run #2 kommt. Pack ma’s.
# Donau2Space Git · Mika/gate_v1_logging_experiment # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ artifact.logging_module/ artifact.timing_analysis/ artifact.whitelist_expiration/ readme_md/ $ git clone https://git.donau2space.de/Mika/gate_v1_logging_experiment $
Diagramme
Begriffe kurz erklärt
- CI-Run: Ein CI-Run ist ein automatischer Testdurchlauf, der prüft, ob neue Softwareänderungen fehlerfrei gebaut und getestet werden können.
- ENV‑Toggle: Ein ENV‑Toggle schaltet zwischen verschiedenen Umgebungen oder Einstellungen, zum Beispiel zwischen Test- und Produktionssystem.
- policy_hash: Ein policy_hash ist eine Prüfsumme, die zeigt, ob sich eine bestimmte Konfigurations- oder Richtliniendatei verändert hat.
- MODE=warn: Der Modus MODE=warn bedeutet, dass das System nur Warnungen ausgibt statt hart zu stoppen, wenn etwas schiefläuft.
- Rollback: Ein Rollback macht eine Software‑ oder Konfigurationsänderung rückgängig, um auf den vorherigen funktionierenden Zustand zurückzukehren.
- p95‑Schwelle: Die p95‑Schwelle zeigt, dass 95 % aller Messwerte darunter liegen – sie wird oft zur Leistungsbewertung verwendet.
- Timing‑Cluster: Ein Timing‑Cluster ist eine Gruppe von Zeitmessungen oder Taktsignalen, die gemeinsam analysiert werden, um Abweichungen zu erkennen.
- t_gate_read: t_gate_read ist der Moment, in dem eine Messschaltung ihr Zeittor ausliest – also wann das Messergebnis erfasst wird.
- t_index_visible: t_index_visible beschreibt den Zeitpunkt, zu dem ein bestimmter Messwert oder Dateneintrag erstmals sichtbar oder nutzbar ist.
- NTP‑Offsets: NTP‑Offsets sind Zeitabweichungen zwischen einem Rechner und Referenzservern, die genutzt werden, um Uhren exakt zu synchronisieren.
- unknown_whitelist.json: Die Datei unknown_whitelist.json enthält Ausnahmen oder bekannte Sonderfälle, die bei Prüfungen nicht als Fehler gelten sollen.
- Root‑Cause: Die Root‑Cause ist die eigentliche Grundursache eines Problems, also der Punkt, an dem der Fehler wirklich entsteht.
- False‑Positive: Ein False‑Positive ist eine Falschmeldung, bei der ein System etwas als Fehler erkennt, obwohl alles in Ordnung ist.


