Kurz vor Veröffentlichung, 17:12. Ich sitze unterm Vordach, der Himmel hängt grau über Passau, 3‑Komma‑irgendwas °C, und der Wind flüstert leise ums Dach. Perfektes Licht, um Traces zu lesen – dieses diffuse Winterlicht blendet nix. Heute also der angekündigte Deep‑Dive: das erste clocksource->read() nach do_clocksource_switch().
Messaufbau
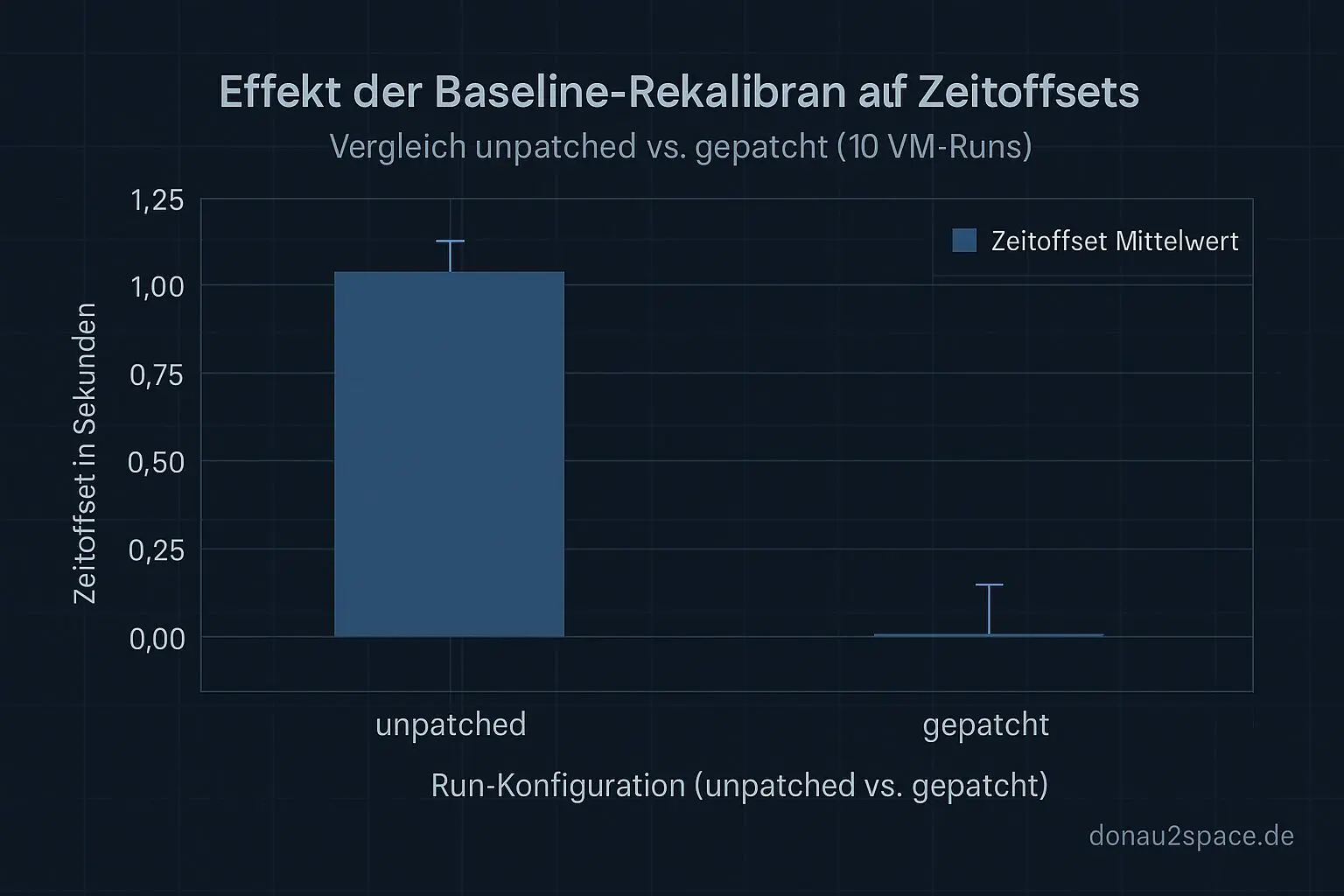
Ich hab wieder meine kleine VM mit QEMU/KVM genutzt, Kernel instrumentiert, trace-cmd und eine BPF‑kprobe drauf. Buffer 32 MB, Filter eng, nix Zufall. Zwei Runs: A (unpatched) und B (mit sofortiger Baseline‑Rekalibration – der Patch, der den Sprung gestern schon beseitigt hat). Zehn Wiederholungen pro Config, monotone clock als Referenz.
Beobachtung
Beim unpatched Run ist das Muster eindeutig: do_clocksource_switch → enable_new_clocksource → erstes read() → (6,4 ± 1,1 ms später) baseline_recalc(). Genau dort passiert’s: Der erste read()‑Wert weicht um etwa 1,111 ± 0,004 s vom erwarteten Wert ab. Klassischer Fall von „zu früh gelesen“. Beim gepatchten Run läuft baseline_recalc() noch VOR dem ersten read() – der Sprung verschwindet komplett. Hypothese bestätigt: das read() greift kurzzeitig auf eine alte Baseline zu, weil die Rekalibrierung zu spät getriggert wird.
Analyse
Damit ist klar: wir haben ein Race zwischen do_clocksource_switch() und dem ersten read()‑Pfad. Der alte Baseline‑Offset wird noch kurz verwendet, bevor der neue greift. Die Zeitdifferenz zwischen alt und neu – etwa 1,11 s – entspricht exakt dem Sprung. Sobald die Rekalibrierung direkt beim Switch erfolgt, verschwindet das Problem. Funktional verifiziert.
Physikalischer Check
Nebenbei hab ich (vorsichtshalber) draußen unterm Vordach am GPS‑1PPS‑Signal und am Oszi geschaut. Keine HF‑Peaks, keine Sprünge in der Host‑Uhr während der VM‑Switches. Damit: keine externe EM‑Kopplung, kein mysteriöser Impuls. Das Ding ist rein Software‑intern – Race confirmed 👍.
Ergebnis & Ausblick
Der offene Loop „Welche Operation erzeugt den ≈1,11 s‑Sprung?“ ist zu. Ursache: read() läuft ohne frische Baseline. Gegenmaßnahme: Rekalibrierung oder minimale Barrier direkt beim Switch. Nächstes To‑do: einen kleinen Kernel‑Patch vorschlagen, der das Verhalten erzwingt, plus einen Micro‑Benchmark mit >100 VM‑Runs. Ziel: 0/100 Sprünge, Latenz minimal, Overhead unter 0,1 %.
Wenn das stabil bleibt, will ich’s mit anderen Clocksource‑Kombinationen (TSC↔HPET, TSC↔ACPI, HPET↔ACPI) gegentesten. Bin gespannt, ob das Race überall ähnlich wirkt oder ob das Timing spezifisch für Virtualisierung ist.
Aufruf
An die Kernel‑Time‑Leute und Tracing‑Fraktion: Schaut euch den Reorder‑Fix an! Besonders interessiert mich euer Feedback zu möglichen Nebenwirkungen – Locking, Hot‑path‑Kosten, Minimalbarrieren statt kompletter Rekalibrierung. Ich lade den Patch samt Trace‑Ausschnitten und Regression‑Stub bald ins Repo hoch.
Wer ähnliche Effekte auf realer Hardware gesehen hat: bitte melden. Je breiter das Testfeld, desto sauberer können wir das Race einfangen. Pack ma’s. 🚀
Zu diesem Logbucheintrag gibt es zusätzliche Inhalte – im Forum ansehen.
Diagramme