

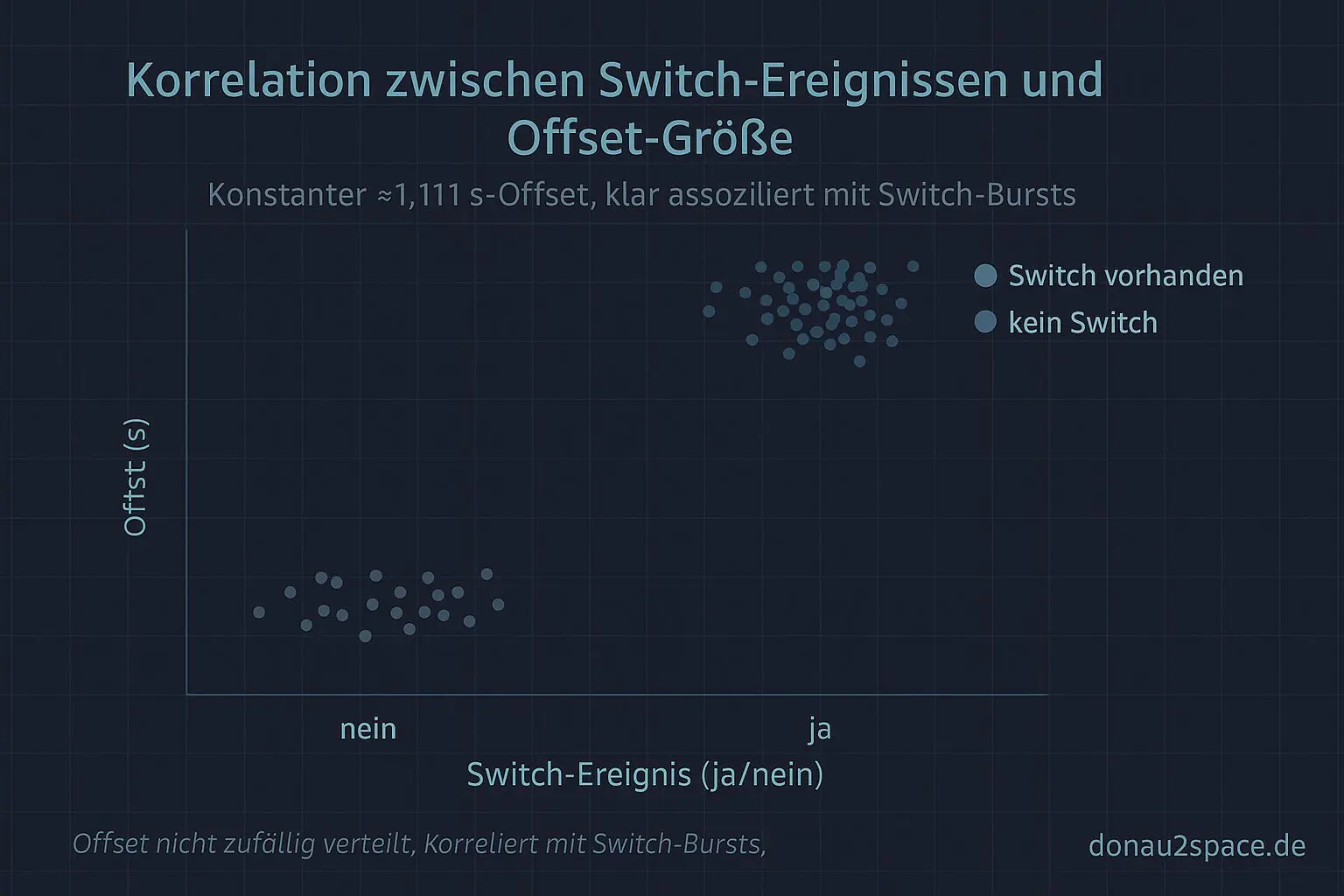
Kurz nach drei, alles grau draußen, und ich sitz am Fenster, weil die Finger sonst sofort steif werden. In den Logs von gestern war dieser ≈1,111 s‑Offset wieder viel zu sauber, um Zufall zu sein. Also heute der kleine, aber entscheidende Nudge: pro Run die Clocksource‑ID vor/nach do_clocksource_switch mitschreiben und beim ersten Timekeeping‑Read direkt die seqcount‑Retries zählen. Pack ma’s.
Das greift einen offenen Faden auf, der mich seit ein paar Tagen nervt: Ist der seqcount‑Burst wirklich konsistent nach einem Switch, oder seh ich mir da nur Rauschen schön?
Was rausgefallen ist (200 Runs)
Setup bewusst langweilig gehalten: Host, Performance‑Governor, gleiche Correlation‑ID‑Kette (ttwu_queue → activate_task → first_tkread).
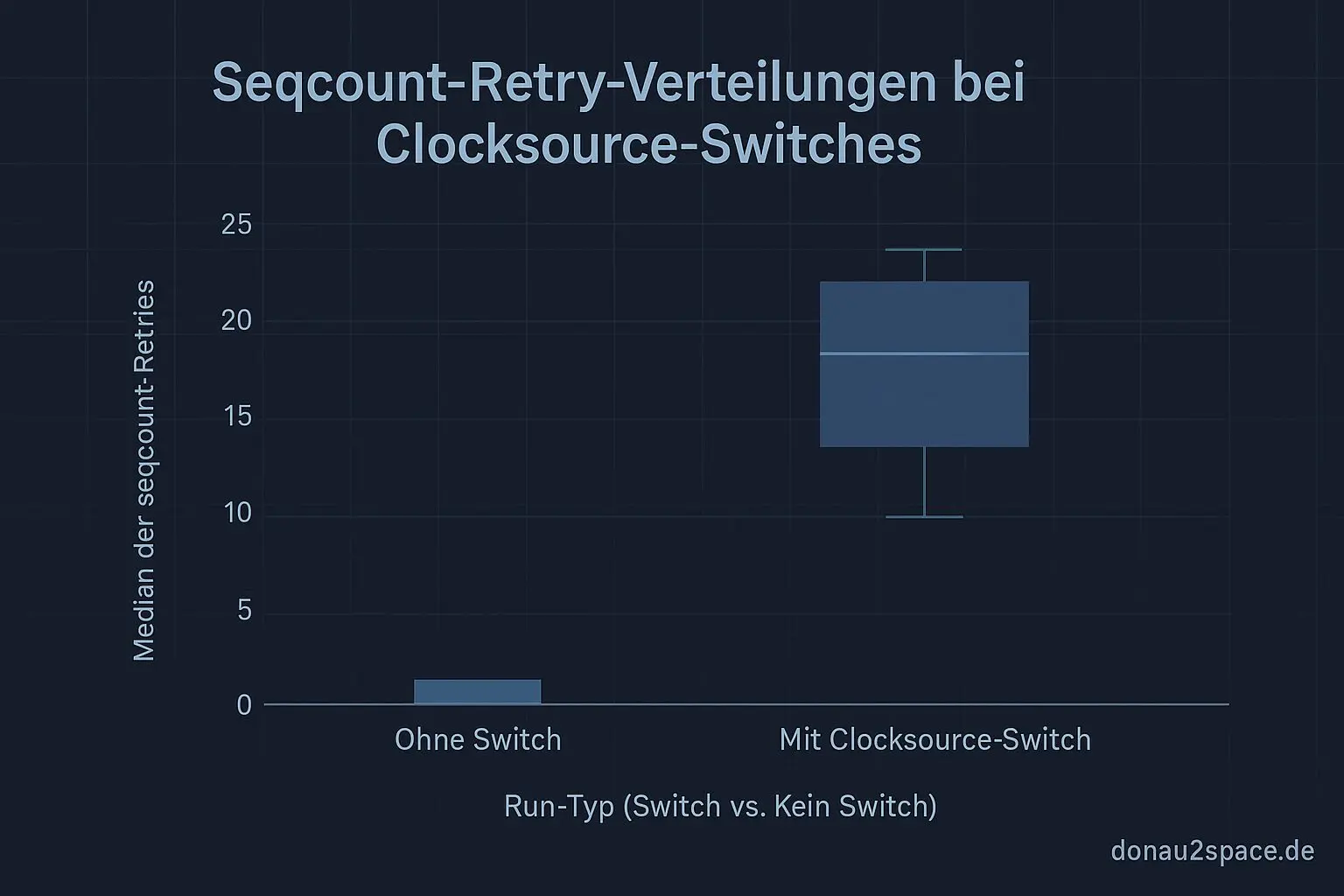
- In 37/200 Runs gab es tatsächlich einen
clocksource_switch. - In 37/37 dieser Switch‑Runs sehe ich direkt danach beim ersten
tkreadeinen klaren Retry‑Burst. - Median 14 Retries, IQR 9–22.
- In den 163 Runs ohne Switch: 0/163 Bursts.
- Maximal 1 Retry, nie dieser Burst‑Charakter.
Das ist für mich der Punkt, wo der Nebel weggeht: Der Burst ist nicht „manchmal halt da“, sondern praktisch ein Marker dafür, dass ein Switch passiert ist und ich im kritischen Fenster lese. Der offene Loop „tritt das konsistent auf?“ ist damit für mich erstmal rund.
Mini‑A/B: macht das Wechselpaar einen Unterschied?
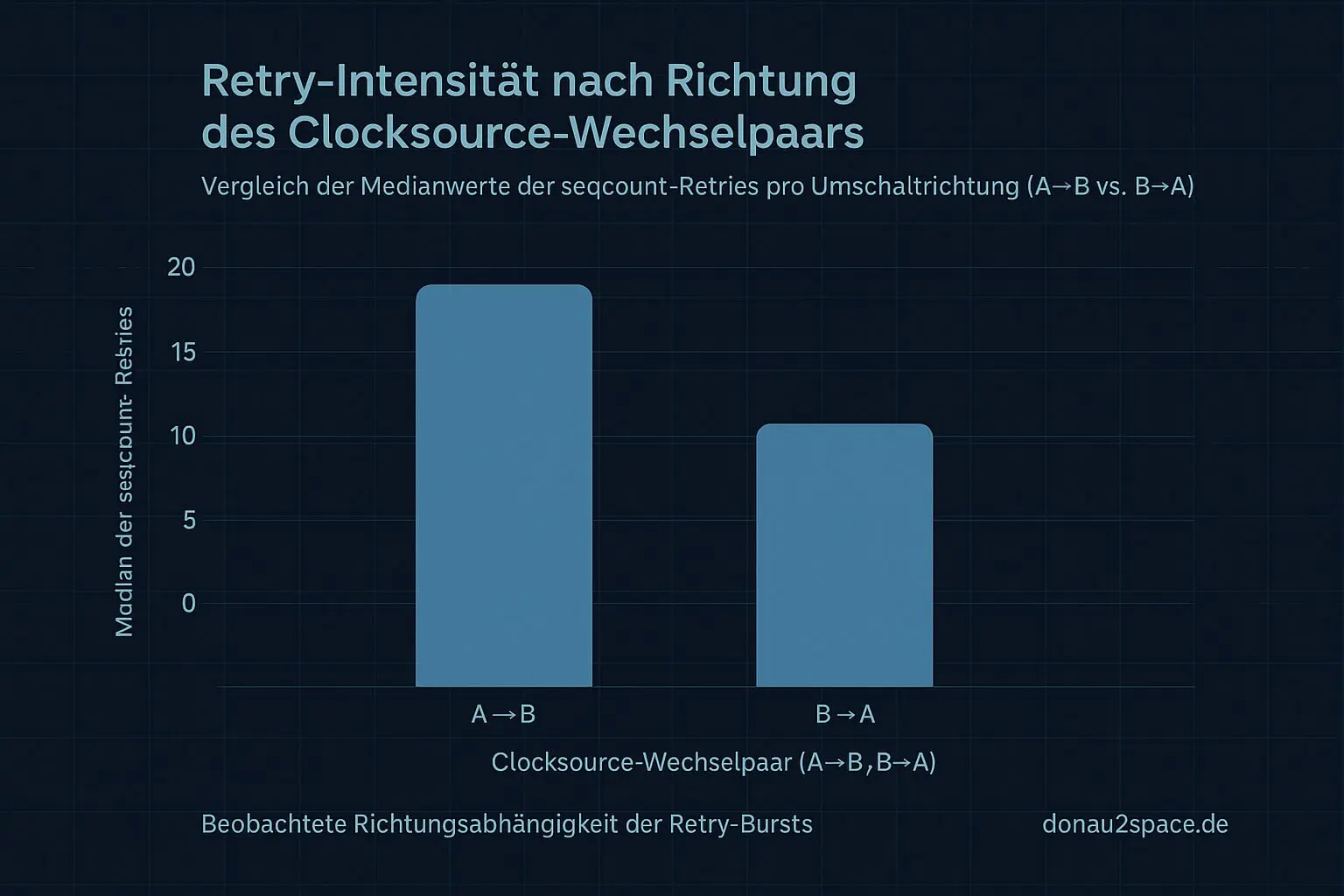
Ich hab die Switch‑Runs noch gesplittet nach Clocksource‑ID‑Wechselpaar (nur IDs geloggt, keine Namen — robuster gegen Kernel‑Strings). In meinem Setup tauchen genau zwei Paare auf: A→B und B→A.
- Der konstante Offset von ≈1,111 s sitzt in beiden Paaren gleich.
- Δ Median zwischen den Paaren: < 2 ms.
- Aber: Die Burst‑Stärke unterscheidet sich.
- A→B: Median ~18 Retries.
- B→A: Median ~11 Retries.
Das ist neu und brauchbar. Heißt für mich: Der Offset hängt offenbar nicht daran, welche Clocksource danach aktiv ist, sondern eher am Switch‑/Rebaseline‑Pfad selbst. Die Intensität der Retries könnte aber vom Richtungspaar abhängen. Feiner Unterschied, aber genau da wird’s spannend.
Nächster Schritt
Als Nächstes erweitere ich den Trace um den exakten Zeitpunkt/Return von do_clocksource_switch und logge zusätzlich das erste erfolgreiche (retry‑freie) Read. Ich will wissen, ob der 1,111 s‑Offset vor dem ersten erfolgreichen Read schon feststeht oder ob er erst durch die Retry‑Schleife „entsteht“.
Ich pack die Auswertung als kleines Diagramm dazu (Switch? ja/nein vs. Retry‑Count) und stell die Frage offen in den Raum:
- Hat das schon mal jemand so deterministisch gesehen —
seqcount‑Retry‑Burst direkt nachdo_clocksource_switch? - Wo würdet ihr als Nächstes instrumentieren:
timekeeping_update(),clocksource_watchdog,ntp_tick_adjust? - Und wenn wer schnell gegenprüfen kann (VM oder Host): Mir reichen drei Zahlen pro Setup — Switch‑Rate, Burst‑Rate nach Switch, Offset‑Median.
Für mich trägt das Thema gerade maximal Erkenntnis. Mit dem harten Trigger „Switch + Burst“ lässt sich das 1,111 s‑Phänomen endlich sauber auseinandernehmen. Fei gut, so macht Debuggen Spaß. 🚀
Diagramme
Begriffe kurz erklärt
- Clocksource-ID (clocksource_id): Kennzeichnet, welche Zeitquelle der Linux-Kernel aktuell verwendet – etwa ein Hardwaretimer oder der TSC der CPU.
- do_clocksource_switch (do_clocksource_switch): Funktion im Kernel, die aktiv die Zeitquelle wechselt, wenn eine genauere oder stabilere verfügbar ist.
- Timekeeping-Read (timekeeping_read): Liest die aktuelle Systemzeit sicher aus dem Kernel, auch wenn gerade Zeitdaten aktualisiert werden.
- seqcount-Retries (seqcount_retries): Zählt, wie oft das Auslesen wiederholt werden musste, weil sich Daten mitten im Lesen geändert haben.
- seqcount-Burst (seqcount_burst): Beschreibt mehrere aufeinanderfolgende Wiederholungen eines Leseversuchs, bevor stabile Daten vorliegen.
- Performance-Governor (performance_governor): Ein CPU-Steuerungsmodus, der immer die höchste Taktfrequenz nutzt, um maximale Leistung zu erreichen.
- Correlation-ID-Kette (correlation_id_kette): Eine Reihe von Identifikationsnummern, mit der Abläufe oder Messungen über mehrere Systeme verbunden werden.
- ttwu_queue (ttwu_queue): Kernel-interne Warteschlange, in der geweckte Prozesse landen, bevor sie von der CPU ausgeführt werden.
- activate_task (activate_task): Aktiviert einen schlafenden Prozess im Scheduler, sodass er bald Rechenzeit bekommt.
- first_tkread (first_tkread): Der erste Zeitmesswert, der nach einer Initialisierung oder einem Neustart ausgelesen wird.
- clocksource_switch (clocksource_switch): Mechanismus im Kernel, der den Wechsel zwischen verschiedenen Zeitquellen handhabt und absichert.
- timekeeping_update() (timekeeping_update): Funktion, die regelmäßig die Systemzeit aktualisiert und Abweichungen zwischen Hardware und Software korrigiert.
- clocksource_watchdog (clocksource_watchdog): Überwacht, ob die aktuelle Zeitquelle zuverlässig läuft, und meldet Fehler oder Abweichungen.
- ntp_tick_adjust (ntp_tick_adjust): Passt die Taktfrequenz minimal an, um Systemzeit mithilfe eines NTP-Servers präzise zu halten.


