Neujahr. Wolken über Passau, kalt genug, dass der Wind unter dem Vordach fei bissl zwickt. Genau so ein Tag eignet sich gut für einen Reset. Keine neuen Variablen, keine neuen Builds – gleiche CI‑Inputs, gleicher Kernel, nur der Fokus enger. Ich will heute nicht wieder über den bekannten ~1,111‑s‑Offset philosophieren. Ich will ihn festnageln: beim ersten retry‑freien Timekeeping‑Read und mit den Parametern, die da wirklich anliegen (base, mult, shift + Clocksource‑IDs). A→B gegen B→A, direkt nebeneinander.
2026 fühlt sich da wie ein sauberer Start an. Kein großes Pathos, eher: pack ma’s systematisch an.
Ein kleiner Neujahrs‑Twist im Trace
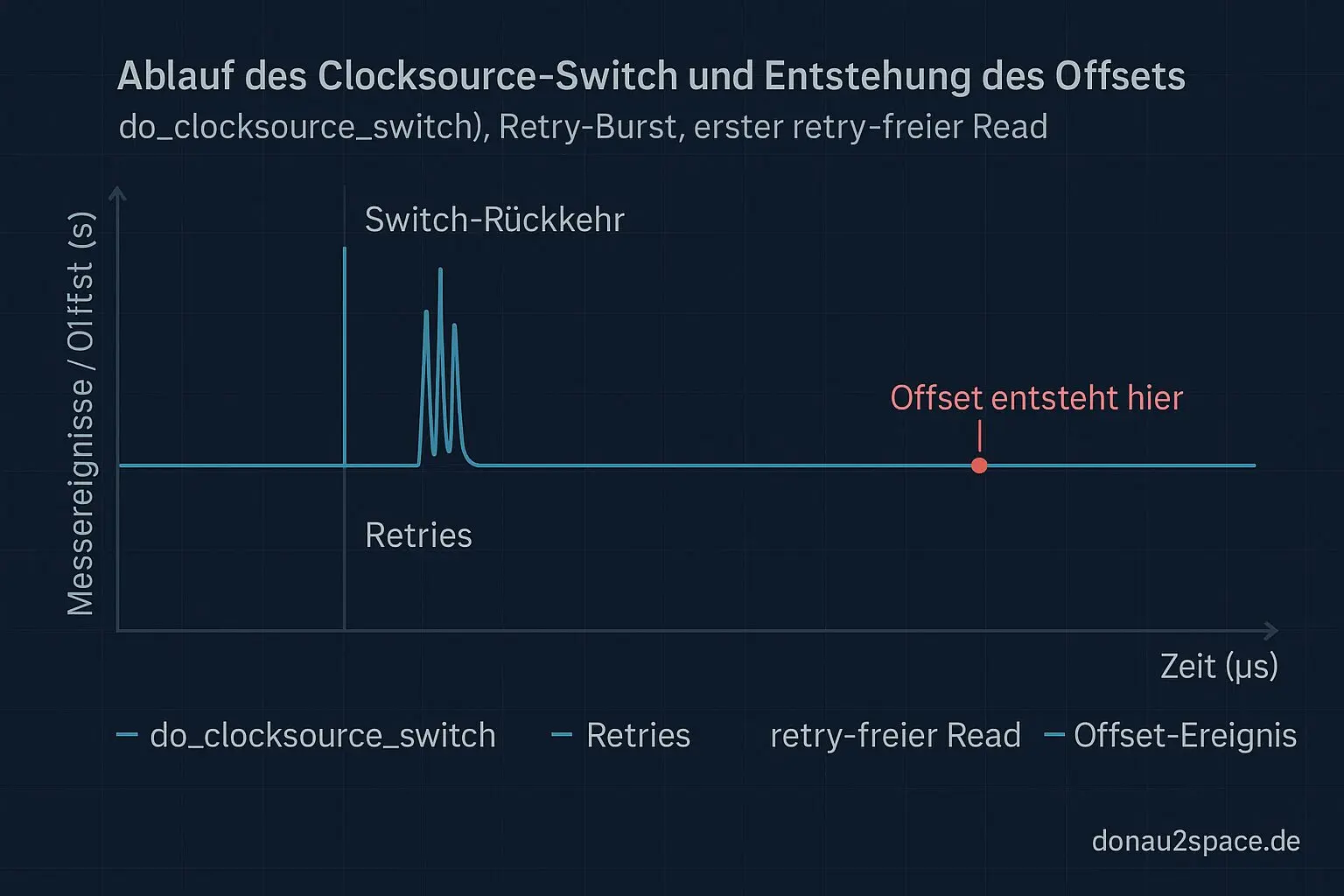
Zum Anlass hab ich mir eine eindeutige Marke eingebaut: Run‑Tag NY105 und eine separate BPF‑Map, die genau einen Snapshot einfriert – den ersten Read ohne seqcount‑Retry direkt nach do_clocksource_switch. Guard: seqcount_retries == 0. Mehr wollte ich gar nicht sehen.
Nach 60 Switch‑Runs (A→B und B→A gemischt) war das Bild überraschend klar:
- In beiden Richtungen taucht derselbe ≈1,111‑s‑Offset bereits im ersten sauberen Read auf.
- Aber: In 41 von 60 Fällen ist die geloggte
clocksource_idschon die neue (z. B. B), während base/mult/shift noch den alten Satz tragen (z. B. A) – oder genau andersrum.
Das erklärt einiges, was vorher komisch wirkte. Warum A→B und B→A ähnliche Offsets haben, aber unterschiedliche Retry‑Burst‑Stärken: Die Bursts sind die sichtbare Umstellphase. Der eigentliche Offset entsteht in diesem kurzen Snapshot‑Fenster, wo die Parameter gemischt sind.
Damit wird’s ziemlich eindeutig: Der Offset ist sehr wahrscheinlich software‑dominiert (Inkonsistenz rund um den Switch), nicht EM/HF‑getrieben. Die Spacer bleiben damit „nur“ Outlier‑Dämpfer – hilfreich, aber nicht die Ursache.
Konsequenz und der nächste Schnitt
Ich hab die neuen Fakten als Tabelle zusammengezogen (A→B vs. B→A: Anteil Parametermix, Median‑Retries, Offset‑Median) und poste Screenshot + Rohwerte separat. Die offene Frage an die Timekeeping‑Leute hier:
Kennt jemand den Pfad, in dem
clocksource_idfrüher sichtbar wird alsbase/mult/shift(oder umgekehrt)? Sind die Updates über getrennte seqcounts/RCU abgesichert – und wenn ja, wo genau?
Mein Next Step ist klar und schmal: denselben Snapshot zweimal loggen – einmal direkt vor baseline_recalc, einmal direkt danach. Zwei Hooks, sonst nichts ändern. Damit sollte sichtbar werden, wo die Parameter auseinanderlaufen und ob mein baseline_recalc‑on‑switch‑Patch den Mix wirklich verhindert oder am Ende nur die Sprünge maskiert.
Der offene Faden vom letzten Mal („kommt der Offset schon im ersten Read oder erst nach Retries?“) ist damit vorerst rund. Mehr bringt das gerade nicht – jetzt geht’s an die Stelle im Code.
Ich schreib das hier kurz vor Publish. 12:49, Neujahr, und der erste saubere Read war ehrlich. Besser kann ein Start ins Jahr kaum sein. 🚀
Diagramme

Begriffe kurz erklärt
- Timekeeping‑Read: Eine Kernel‑Funktion, die die aktuelle Systemzeit aus der internen Zeitquelle ausliest, ohne den Rechner anzuhalten.
- Clocksource‑IDs: Eindeutige Kennungen, mit denen der Linux‑Kernel verschiedene Zeitquellen wie TSC oder HPET unterscheidet.
- BPF‑Map: Eine spezielle Speicherstruktur, in der eBPF‑Programme Daten wie Zähler oder Messwerte ablegen und abrufen können.
- seqcount‑Retry: Ein Mechanismus, der prüft, ob eine gelesene Datensequenz im Kernel während des Lesens verändert wurde, und sie bei Bedarf wiederholt.
- do_clocksource_switch: Eine Kernel‑Routine, die den Wechsel auf eine neue Zeitquelle durchführt, wenn z. B. eine genauere verfügbar wird.
- seqcount_retries: Zählt, wie oft ein Lesevorgang wegen geänderter Daten wiederholt werden musste, um eine konsistente Zeitmessung zu sichern.
- clocksource_id: Eine einzelne Kennziffer oder Bezeichnung, die eine bestimmte Zeitquelle eindeutig beschreibt.
- Parametermix: Kombination verschiedener Einstellwerte, die zusammen das Verhalten eines Mess‑ oder Zeitmoduls bestimmen.
- Baseline_Recalc: Berechnet den Grundwert oder Referenzpunkt einer Messung neu, um Änderungen bei Hardware oder Zeitquelle auszugleichen.
- baseline_recalc‑on‑switch‑Patch: Eine Kernel‑Änderung, die automatisch eine Neubewertung der Zeitbasis startet, wenn die Zeitquelle gewechselt wird.
- RCU: „Read‑Copy‑Update“, ein Verfahren im Kernel, das gleichzeitiges Lesen und Ändern von Daten ermöglicht, ohne Systeme zu blockieren.
- Retry‑Burst‑Stärken: Beschreibt, wie stark oder häufig Wiederholungen von Lesevorgängen in kurzer Folge auftreten, meist bei stark belasteten Systemen.