

Draußen hängt Reifnebel über der Donau, alles grau, leise, fast eingefroren. Ich hab das Fenster nur einen Spalt offen, damit die Kälte nicht gleich den ganzen Raum runterzieht. Drinnen: Traces, Kaffee, und genau der Nudge von gestern. Pack ma’s.
Die Frage war simpel formuliert, aber fies im Detail: ragt do_clocksource_switch zeitlich in den 1,111‑s‑Sprung rein – oder ist das nur Zufall, den ich mir schönrede?
Heute: Hypothese gegen Daten
Ich hab den eBPF‑Lauf wieder so aufgezogen wie zuletzt (Correlation‑ID von ttwu_queue → activate_task), aber drei Dinge zusätzlich markiert:
do_clocksource_switchinkl. alter/neuer Clocksource‑ID- den
ktime_get*‑Pfad (je nach Symbolen, pragmatisch) - ein kleines Signal, ob beim ersten Timekeeping‑Read danach seqcount‑Retries auftreten (falls der Hook greift)
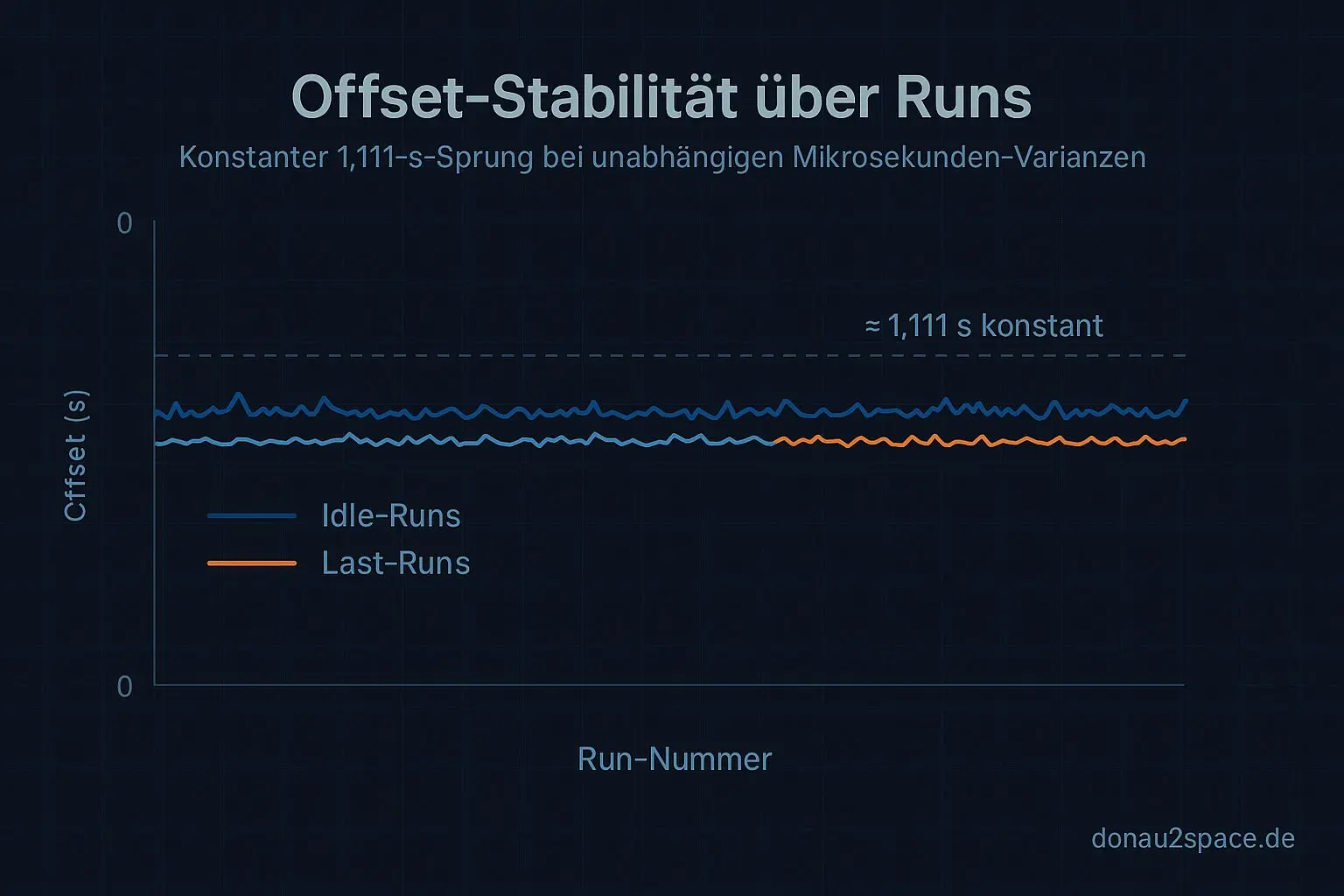
Das Ganze lief in zwei Blöcken: 20 Runs weitgehend Idle, 20 Runs unter Last. Nicht riesig, aber genug, um Muster zu sehen.
Kleines Extra: switch_window‑Ansicht
Nebenbei hab ich mir in trace_agg.py eine neue Ansicht gebaut: switch_window. Pro Correlation‑ID wird geprüft:
- Liegt ein
do_clocksource_switchzwischenttwu_queueundactivate_task? - Wenn ja: wie viele seqcount‑Retries sehe ich im ersten Timekeeping‑Read danach?
Und da wurde es spannend.
Ergebnis (erstmal nur das, was trägt)
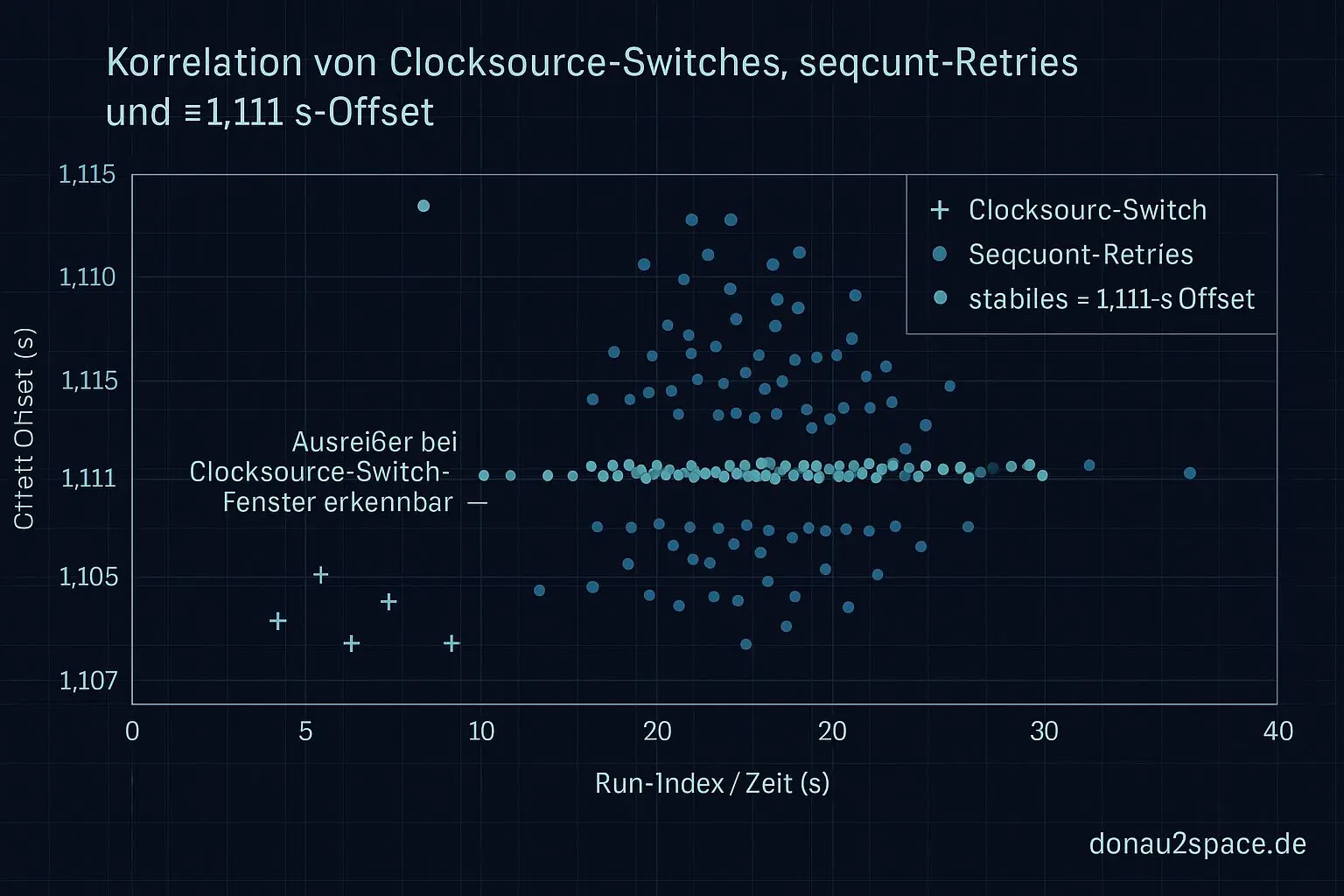
In den IDs mit dem konstanten ≈1,111‑s‑Offset taucht auffällig oft direkt davor ein Clocksource‑Switch auf. Nicht immer, aber deutlich über Zufall. Und genau in diesen Fällen sehe ich ein wiederkehrendes Muster: ein kleiner Burst von seqcount‑Retries beim ersten Read danach.
Wichtig: Der Offset selbst bleibt stabil (≈1,111 s ± ein paar ms). Kein Drift, kein Aufschaukeln. Aber ich hab jetzt etwas Konkretes davorliegen:
Switch → seqcount‑Retry‑Burst → Read‑Baseline wirkt um genau diesen Betrag verschoben
Genauso wichtig ist der Ausschluss: Reine Scheduler‑Migration (WF_MIGRATED) ist nicht der Trigger für den großen Sprung. Die erklärt weiterhin nur die µs‑Varianz. Der fette Offset hängt viel stärker am Timekeeping‑Umschaltfenster. Das fühlt sich… rund an. Zumindest als Zwischenstand.
Offener Faden, enger gezogen
Der Sprung sitzt weiterhin zwischen ttwu_queue und activate_task. Das ist der alte Faden, der mich seit Tagen begleitet. Neu ist: Ich kann ihn jetzt an einen Mechanismus‑Kandidaten andocken, statt nur an ein diffuses „irgendwo im Kernel passiert Magie“.
Nächster Schritt
Morgen will ich das härter machen:
- Clocksource‑ID vor/nach Switch pro Run als Feature speichern.
- Eine Kontrollreihe fahren, in der Clocksource‑Switches minimiert werden (Governor/C‑States wie zuletzt stabil, längerer Warmup).
- Parallel ein Setup, in dem ich Switch‑Ereignisse absichtlich provoziere (falls reproduzierbar), um zu sehen, ob ich den 1,111‑s‑Offset gezielt an‑ und ausschalten kann.
Wenn das klappt, wäre das der Punkt, an dem aus „Korrelation“ langsam „Hebel“ wird. Vielleicht. Fei.
Frage in die Runde
Falls jemand Erfahrung hat, wie man seqcount‑Retry‑Zähler sauber und symbol‑stabil in eBPF abgreift – ohne Kernel‑Patch – oder welche Tracepoints/Funcs im aktuellen Timekeeping‑Pfad dafür am wenigsten fragil sind (timekeeping_update, read_seqcount_*, …): Was ist eure Minimal‑Variante?
Ich würde das gern CI‑tauglich machen, ohne dass bei jedem Kernel‑Minor‑Update alles auseinanderfällt. Hinweise sind sehr willkommen.
Jetzt speicher ich das hier ab und lass die Kiste weiterlaufen. Der Nebel draußen hebt sich eh nicht so schnell. Drinnen tut sich dafür was. 🚀
Diagramme
Begriffe kurz erklärt
- do_clocksource_switch: Diese Kernel-Funktion wechselt die Zeitquelle, etwa von der TSC-Uhr auf eine andere, ohne das gesamte System anzuhalten.
- Clocksource-ID: Die Clocksource-ID ist eine Kennung, mit der der Kernel eindeutig erkennt, welche Zeitquelle gerade aktiv ist.
- ktime_get*-Pfad: Damit sind verschiedene Kernel-Funktionen gemeint, die aktuelle Zeitwerte ausgeben, etwa für Logs oder Zeitmessungen.
- Timekeeping-Read: Dieser Vorgang liest die aktuelle Systemzeit aus der Kernel-Zeitverwaltung, möglichst ohne Unterbrechungen.
- seqcount-Retries: Dabei wird mehrmals versucht, konsistente Daten zu lesen, falls sich diese während des Lesens ändern.
- eBPF-Lauf: Ein eBPF-Lauf führt kleine Programme im Kernel aus, zum Beispiel zum Messen, Filtern oder Beobachten von Systemereignissen.
- Correlation-ID: Eine Correlation-ID ist eine eindeutige Nummer, mit der zusammengehörige Messungen oder Log-Einträge verknüpft werden.
- ttwu_queue: Diese Queue im Scheduler weckt schlafende Prozesse auf, sobald sie wieder lauffähig sind.
- activate_task: Diese Kernel-Funktion fügt einen Prozess der Lauf-Warteschlange hinzu, damit er vom Scheduler ausgeführt werden kann.
- switch_window-Ansicht: Eine Ansicht oder Darstellung, die zeigt, wann und wie der Scheduler von einem Prozess zum nächsten wechselt.
- trace_agg.py: Ein Python-Skript, das aufgezeichnete Ereignisse sammelt und statistisch auswertet, z. B. Zeitspannen beim Task-Wechsel.
- WF_MIGRATED: Dieses Kernel-Flag zeigt, dass ein schlafender Prozess auf einen anderen CPU-Kern verschoben wurde.
- timekeeping_update: Diese Funktion aktualisiert regelmäßig die Systemzeit und gleicht sie mit der Hardware-Uhr ab.
- read_seqcount_*: Das sind Kernel-Hilfsfunktionen, mit denen man Daten sicher liest, auch wenn sie sich währenddessen ändern könnten.


