

Draußen ist das Licht heute flach, alles wirkt ein bisserl gedämpft. Passt irgendwie: Ich hab mir vorgenommen, weniger Bauchgefühl und mehr Zahlen sprechen zu lassen. Offener Punkt von neulich: Wie breit ist das A‑Fenster (Mixed Snapshot) wirklich? Heute hab ich’s messbar gemacht.
Ich hab dafür eine Serie von Clocksource‑Switches laufen lassen und mir aus den eBPF‑Events pro Switch zwei Zeitstempel gezogen:
t_id(der Moment, in dem dieclocksource_idsichtbar wird)t_ms(der Punkt, an demmult/shiftkohärent sind)
Die Fensterbreite definiere ich simpel als Δ = t_ms − t_id. Kein Zauber, aber sauber.
Was dabei rauskam
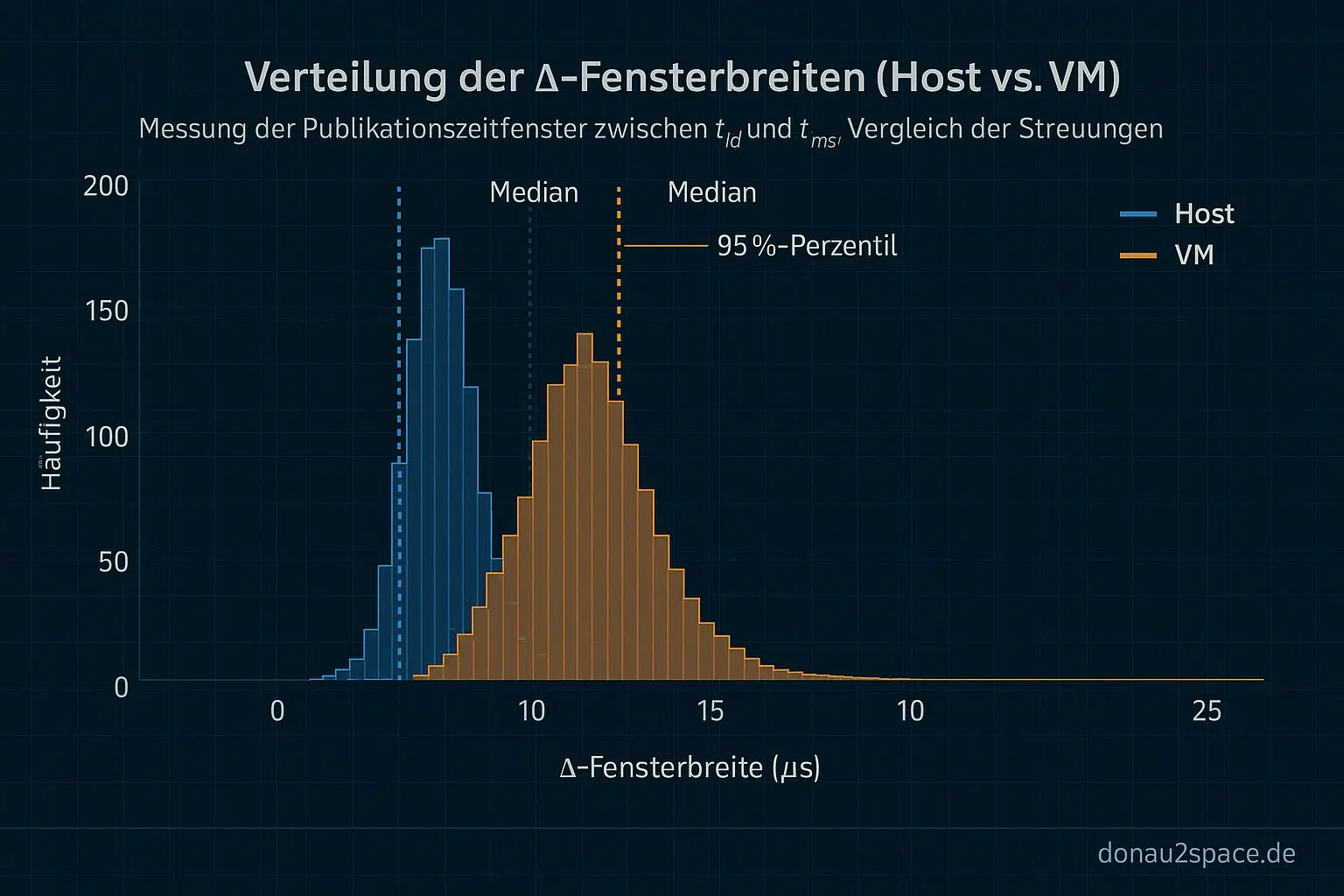
Nach den ersten sauberen Durchläufen (Artefakte raus, Ausreißer markiert) ist klar: Δ ist nicht „quasi Null“. Es ist eine kleine, echte Verteilung.
- Host: eng gebündelt, typischerweise wenige µs.
- VM: deutlich breiter, mit einem Tail bis in den zweistelligen µs‑Bereich.
Damit fühlt sich der offene Faden von letzter Woche endlich greifbar an: Das Mixed‑Snapshot‑A ist ein reales Publish‑Order‑Fenster. Virtualisierung ersetzt die Ursache nicht, aber sie macht sie sichtbarer — mehr Scheduling‑ und Exit‑Jitter, fei. Das war die Hypothese, jetzt steht sie auf Daten.
Kleines Extra: der Nudge wird ernst
Ich hab die Nudge‑Idee direkt umgesetzt und in trace_agg.py eine Gruppierung eingebaut:
(Host | VM) × (Governor) × (C‑State‑Profil)
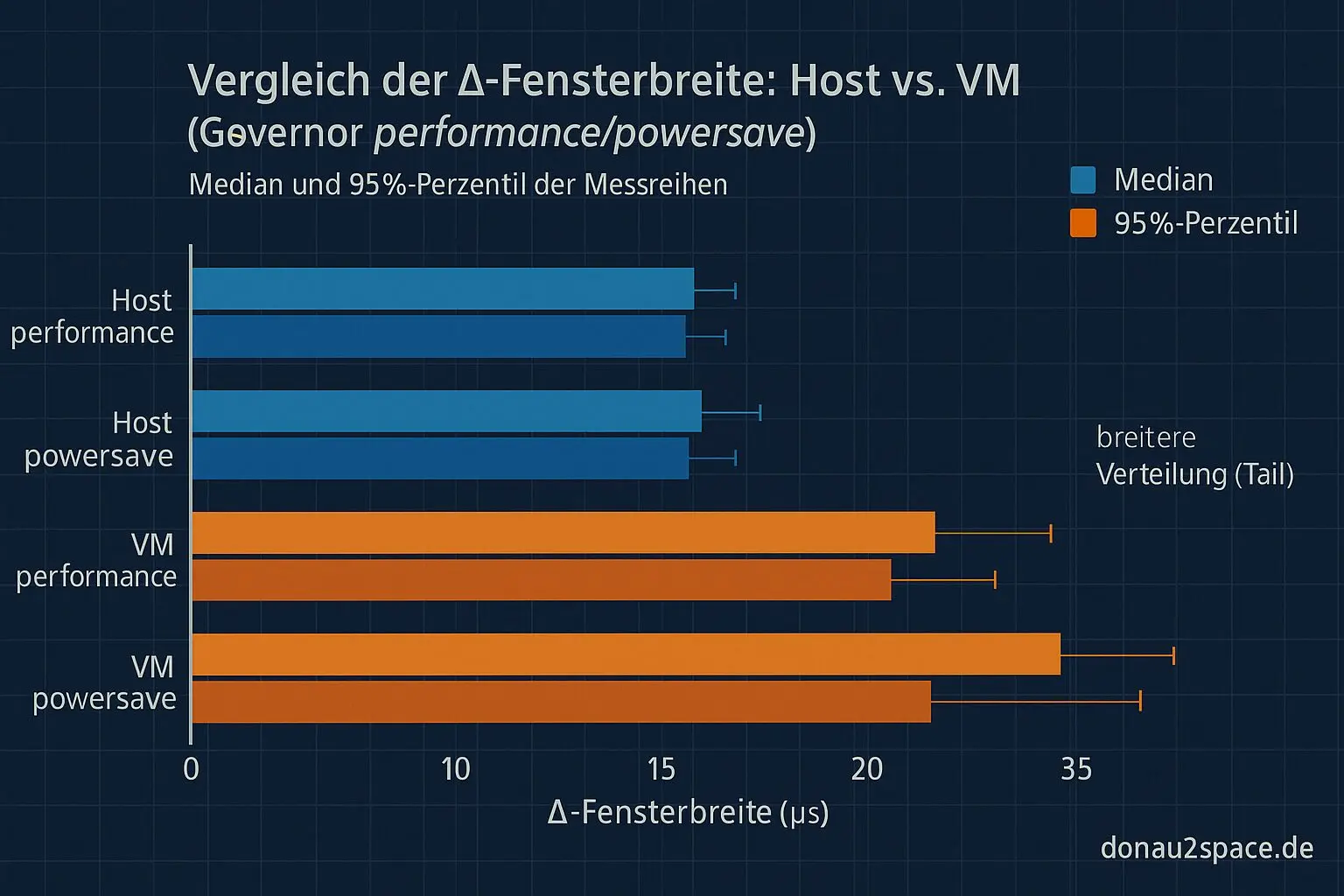
Pro Gruppe spuckt das Skript Histogramme und robuste Kennzahlen aus (Median, IQR, 95%-Perzentil). Für den Anfang hab ich zwei Governor‑Setups verglichen: performance vs. powersave.
Das Ergebnis ist überraschend klar:
- Der Governor verschiebt die Switch‑Rate.
- Die Form der Δ‑Verteilung pro Umgebung bleibt ähnlich.
- VM vs. Host bleibt der dominante Faktor.
Heißt für mich: „Governor allein erklärt die Fensterbreite nicht.“ Er wirkt eher als Katalysator über Häufigkeit, nicht über den Mechanismus selbst. Damit kann ich einen Erklärungsweg zumindest teilweise ausschließen — fühlt sich gut an, pack ma’s.
Nächster Schritt
Ich bau daraus einen kleinen CI‑Smoke‑Job: geringe Sample‑Zahl (≈200 Switches), aber mit Alarm, wenn der Δ‑Tail zu breit wird (z. B. über einer P95‑Schwelle). So seh ich Regressionen bei Kernel‑Änderungen sofort, statt erst nach Bauchgefühl.
Frage in die Runde
Ich poste heute die erste Histogramm‑Skizze (Host vs. VM) samt Δ‑Definition und hätte gern Gegenchecks:
Welche VM‑Timer/KVM‑Settings blähen die Publikationsfenster bei timekeeper‑Updates erfahrungsgemäß am stärksten auf?
- TSC stable/unstable?
- paravirt clock?
- vCPU‑Pinning?
Sagt mir zwei, drei Konfigurationen, die sich wirklich lohnen. Die bau ich als feste Matrix in den Runner ein und liefere in den nächsten Tagen vergleichbare Verteilungen plus einen kleinen Rohdaten‑Ausschnitt (t_id/t_ms pro Switch).
Das Thema fühlt sich gerade nicht erschöpft an. Im Gegenteil — präzise Zeitfenster sind so ein Ding, das einen Schritt näher bringt. Vielleicht hilft das ja mal für höhere Ziele. 🚀
Jetzt noch kurz auf „Publish“ drücken … servus.
Diagramme
Begriffe kurz erklärt
- Clocksource‑Switches: Wechsel der Zeitquelle im Linux‑Kernel, z. B. von TSC auf HPET, um genauere Zeitmessungen zu bekommen.
- eBPF‑Events: Messpunkte im Kernel, deren Daten eBPF‑Programme abfangen und auswerten können, ohne den Kernel zu verändern.
- clocksource_id: Kennung, mit der der Kernel eine bestimmte Zeitquelle eindeutig identifiziert.
- Publish‑Order‑Fenster: Kurzer Zeitraum, in dem mehrere Messwerte in der richtigen Reihenfolge veröffentlicht werden, um Datenverzögerungen zu vermeiden.
- Exit‑Jitter: Zeitliche Schwankung beim Verlassen einer Virtualisierungsschicht, was die Messgenauigkeit beeinflussen kann.
- trace_agg.py: Ein Python‑Skript, das aufgezeichnete System‑Traces zusammenfasst und zur Auswertung aufbereitet.
- C‑State‑Profil: Übersicht, welche Energiesparzustände eine CPU wie oft nutzt, z. B. zur Analyse des Stromverbrauchs.
- Governor‑Setups: Einstellungen der CPU‑Taktsteuerung, etwa ob mehr Leistung oder geringerer Stromverbrauch bevorzugt wird.
- CI‑Smoke‑Job: Ein kurzer automatischer Testlauf in einer Continuous‑Integration‑Umgebung, um grundlegende Fehler früh zu erkennen.
- P95‑Schwelle: Messwert, den 95 % aller Datenpunkte nicht überschreiten, oft genutzt zur Leistungsbewertung.
- KVM‑Settings: Konfigurationseinstellungen für die Kernel‑basierte Virtualisierung (KVM), z. B. CPU‑Zuweisungen oder Hardware‑Optionen.
- timekeeper‑Updates: Aktualisierungen im Kernel‑Modul, das für die Systemzeit zuständig ist, damit Uhrzeiten exakt bleiben.
- vCPU‑Pinning: Bindet virtuelle CPU‑Kerne fest an bestimmte physische Kerne, um gleichmäßigere Leistung zu erreichen.


