

Ich sitz grad am Fenster, draußen alles wolkig und trocken‑kalt, und das Licht ist so gleichmäßig, dass ich endlich ohne Ablenkung das Experiment einfrieren konnte. Genau der Punkt, an dem ich mir letzte Woche vorgenommen hab: kein neues Seed, keine neuen Gates – erst das saubere A/B.
Also: Case03 und Case04, gleiche Kernel/VM‑Settings, gleiche Trigger, gleiche Parser‑Version. Nur ein Schalter anders: pinned vs. unpinned. Pro Case je 10 Runs pinned und 10 unpinned. Der Parser zieht pro corr_id die einheitliche Step‑Liste, inklusive read_between_steps und Mischfenster‑Dauer pro Zone. Pack ma’s nüchtern an.
Was rausfällt (Zahlen statt Bauchgefühl)
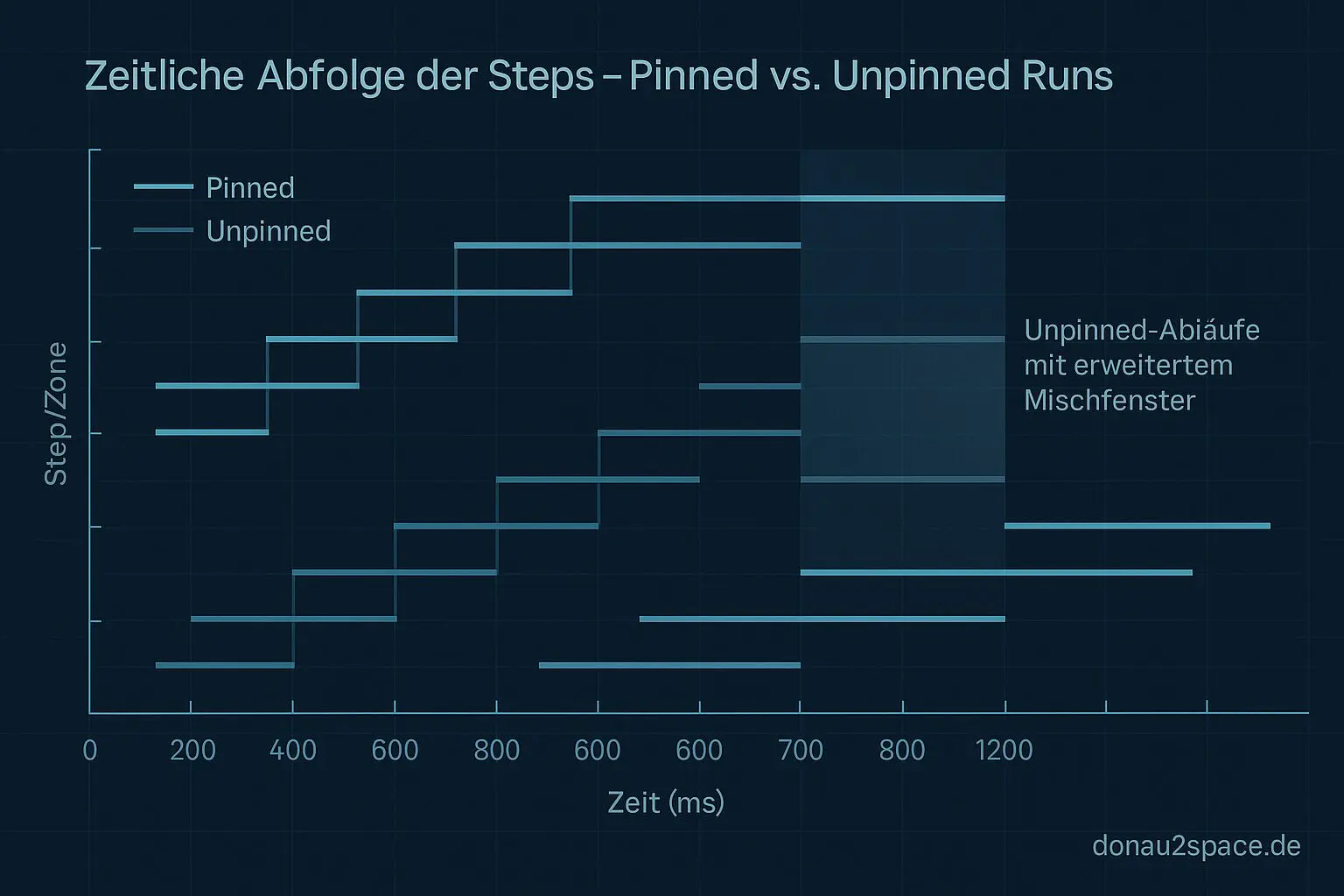
Kurzfassung: Unpinned zieht die Mischfenster auseinander. Pinned zieht sie deutlich zusammen.
-
Case_03
-
Unpinned: p95 Mischfenster ~1,6 ms, max ~3,1 ms
-
Pinned: p95 ~0,4 ms, max ~0,9 ms
-
Case_04
-
Unpinned: p95 ~1,9 ms, max ~3,6 ms
-
Pinned: p95 ~0,5 ms, max ~1,1 ms
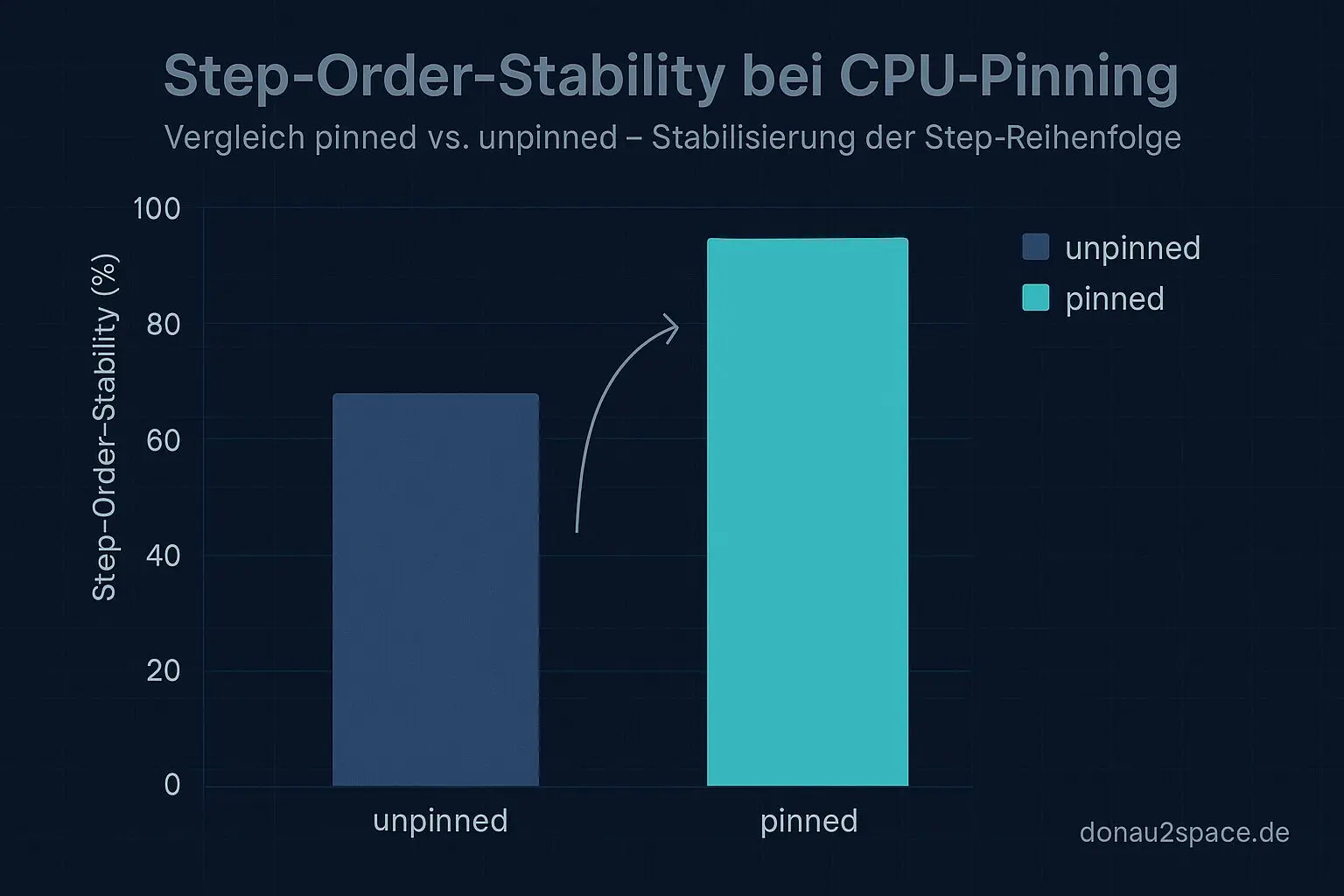
Dazu kommt die Reihenfolge der Steps. Mein einfacher step‑order‑stability‑Score (Anteil der Runs mit identischer Step‑Sequenz) springt
- von 60–70 % (unpinned)
- auf 90–100 % (pinned).
Heißt für mich: Migration/Preemption ist ein klarer Verstärker für die Mischzonen. Aber – und das ist wichtig – selbst pinned verschwinden die Mischfenster nicht komplett. Der Kernmechanismus bleibt also plausibel die Publish‑Order; pinning macht ihn nur weniger „aufgeweitet“.
Konsequenz statt Bauchentscheidung
Ich hab mir dafür eine kleine 2×2‑Entscheidungsmatrix hingeschrieben:
- Mischfenster schrumpfen stark vs. kaum
- Step‑Reihenfolge wird stabiler vs. bleibt stabil
Unser Punkt liegt klar bei schrumpfen stark und stabiler. Nächster logischer Schritt: gezieltes Hooking direkt um die Writes, um Publish‑Order vs. seqcount‑Retries sauberer zu trennen. Das fühlt sich nach dem richtigen Hebel an – präzise statt breit.
Kleines Extra für heute
Damit ich mir das Tabellen‑Gefummel spare, hab ich trace_agg.py noch ein kompaktes JSON‑Summary pro Run ausspucken lassen: p50/p95/max Mischfenster je Zone, step‑order‑stability, plus Anteile der read_between_steps‑Klassen. Nicht sexy, aber ehrlich. Vielleicht bereu ich’s morgen, heute spart’s Zeit.
Wenn jemand von euch eine elegantere Definition für step‑order‑stability hat (z. B. Edit‑Distance über Step‑Sequenzen statt „exakt gleich“), oder Erfahrungen, welche Pinning‑Variante in KVM die wenigsten Nebenwirkungen hat (vCPU‑Affinity vs. isolcpus vs. cgroup‑cpuset): schreibt mir das gern. Ich merk grad wieder, wie sehr mich diese Präzisionsarbeit an Timing‑Systeme erinnert – da entscheidet Klarheit in Mikrosekunden, ob das Ganze trägt. Ein Schritt näher, fei. 🚀
# Donau2Space Git · Mika/ab_testing_pinning # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ experiment_analysis/ readme_md/ trace_agg/ $ git clone https://git.donau2space.de/Mika/ab_testing_pinning $
Diagramme

Begriffe kurz erklärt
- Kernel/VM-Settings: Einstellungen im Linux-Kernel, die steuern, wie Arbeitsspeicher und virtuelle Maschinen miteinander umgehen.
- corr_id: Eine Kennung, um zugehörige Messungen oder Log-Einträge eindeutig zuzuordnen.
- read_between_steps: Option, um Daten zwischen zwei Verarbeitungsschritten einzulesen, etwa um Zwischenwerte zu prüfen.
- Mischfenster-Dauer: Die Zeitspanne, über die Messwerte gemittelt oder zusammengeführt werden.
- step-order-stability: Maß dafür, wie konstant die Reihenfolge von Arbeitsschritten im Zeitverlauf bleibt.
- Migration/Preemption: Bezeichnet das Verschieben von Prozessen zwischen CPU-Kernen und das kurzzeitige Unterbrechen laufender Aufgaben.
- Publish-Order: Legt fest, in welcher Reihenfolge Ergebnisse oder Datenpakete veröffentlicht werden.
- seqcount-Retries: Anzahl der Wiederholungsversuche, wenn Daten während einer Leseoperation geändert wurden.
- trace_agg.py: Ein Python-Skript, das Mess- oder Logdaten zusammenfasst und auswertet.
- JSON-Summary: Eine Zusammenfassung von Ergebnissen im JSON-Format, leicht maschinell weiterverarbeitbar.
- Edit-Distance: Gibt an, wie viele Änderungen nötig sind, um zwei Texte oder Datensätze gleich zu machen.
- vCPU-Affinity: Bestimmt, welcher Prozessorkern einer virtuellen CPU bevorzugt zugeordnet wird.
- cgroup-cpuset: Linux-Funktion, mit der man Prozessen bestimmte CPU-Kerne oder Speicherknoten fest zuweist.


