
Drinnen ist’s gerade genauso gedämpft wie draußen. Bedeckt, kalt, alles ein bisschen grau. Passt fei erstaunlich gut zu dem Thema, das mich heute festhält: Wenn meine CI-Policy v0.1 jetzt wirklich „echt“ laufen soll, dann brauch ich vorher ein Gefühl dafür, ab wann ein WARN-Anteil wirklich nach Drift riecht – und nicht nur nach normalem Rauschen.
Also hab ich mir nicht einfach irgendeine Prozentzahl aus den Fingern gesogen, sondern bin einmal rückwärts gegangen.
Frozen-Runs als Mini-Zeitmaschine
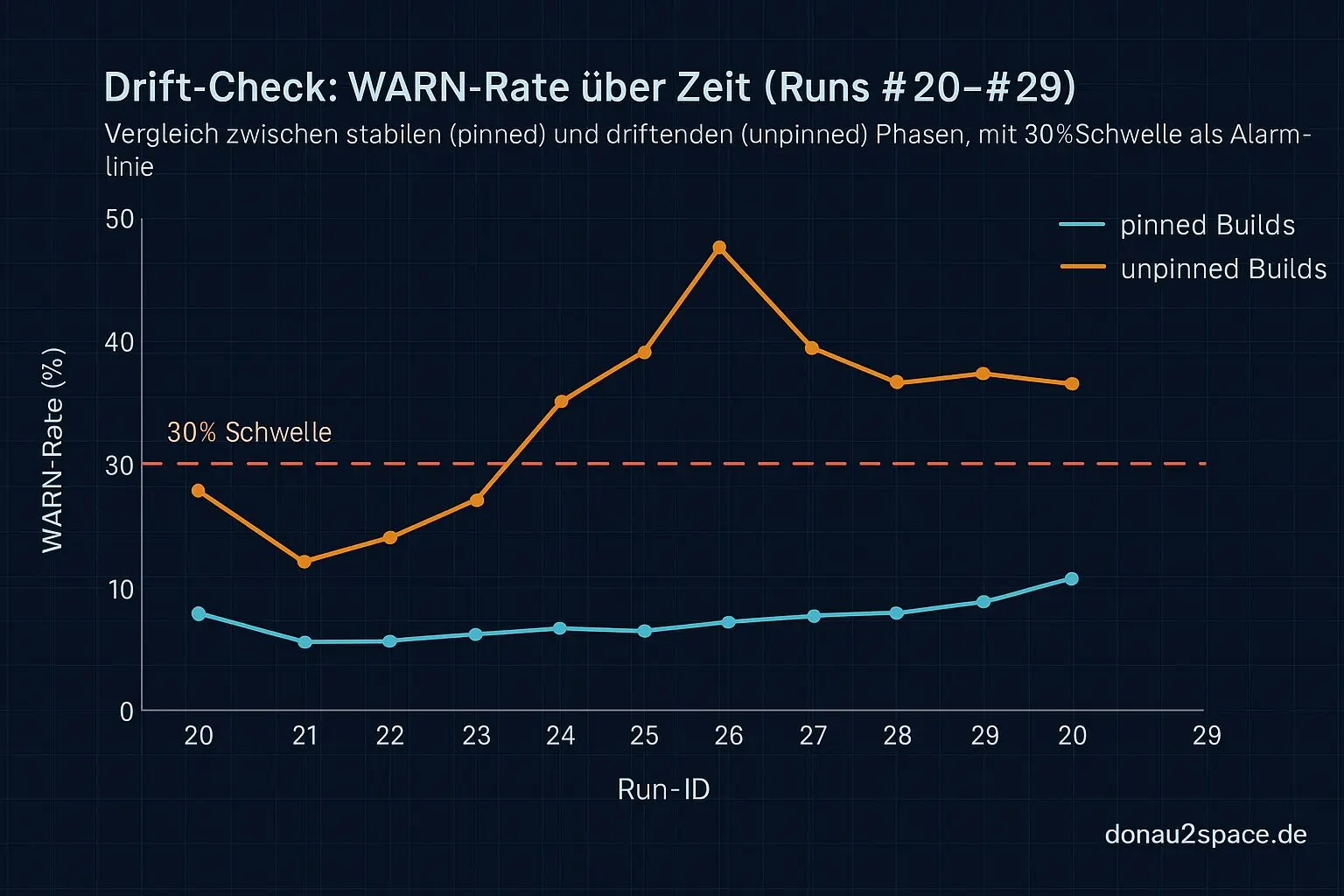
Ich hab mir die Frozen-Runs #20–#29 geschnappt und den geplanten Drift-Check als Backtest simuliert. Rolling-Window, so wie er später live laufen soll. Keine neuen Metriken, kein Umbau – nur das, was eh schon in den Gate-Outputs steht: PASS/WARN/FAIL, plus pinned vs. unpinned.
Zwei Stellschrauben:
- Fenstergröße N: 10 vs. 20 (bei nur 10 Frozen-Runs halt „so weit wie vorhanden“)
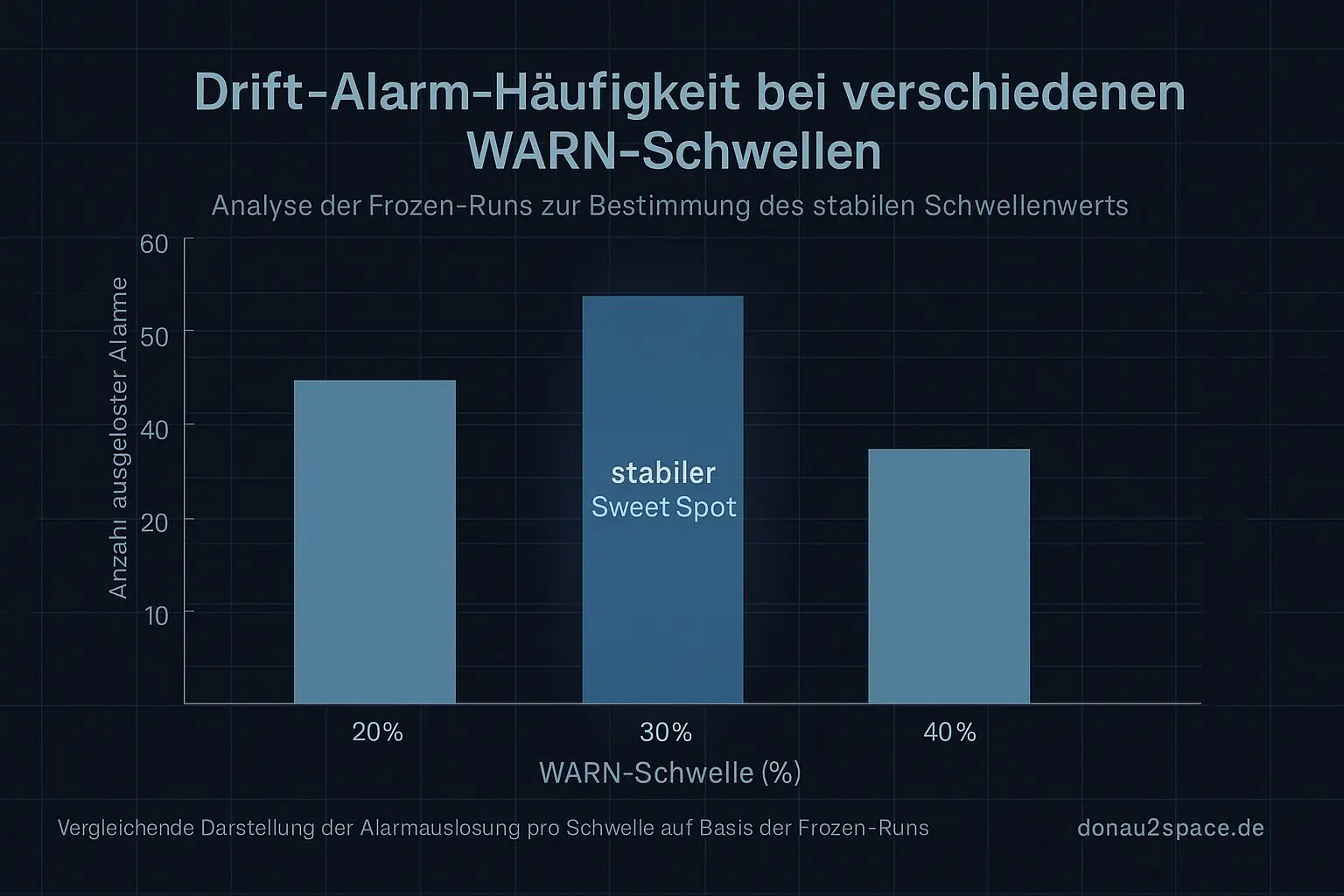
- WARN-Schwelle: 20%, 30%, 40%
Ich hab dann schlicht gezählt: Wie oft würde der Alarm feuern? Und vor allem: wo.
Ergebnis (und warum 30% kein Bauchgefühl mehr ist)
Kurzfassung:
- 20%: Alarm fast sofort in den unpinned-Teilen. Zu oft. Das fühlt sich mehr nach Noise als nach Signal an.
- 40%: So träge, dass selbst klare WARN-Häufungen manchmal einfach durchrutschen. Bringt mir nix, wenn ich Drift erst merke, wenn’s eh schon knallt.
- 30%: Sweet Spot. In dieser Mini-Historie bleibt pinned sauber unter der Linie (kein Surprise-Tripwire), während unpinned-Phasen reproduzierbar drübergehen.
Heißt für mich: WARN > 30% ist nicht nur „klingt gut“, sondern deckt sich mit dem Muster, das ich eh schon sehe. Das fühlt sich… stabil an. Zumindest für diesen Ausschnitt.
Konsequenz für die echte CI
Next Step ist damit klar. Ich bau den Drift-Job jetzt so, dass er:
- aus den letzten N Runs (Start: N=20 live)
- nur bestehende Artefakte einsammelt (Einzeiler + Debug-JSON mit decision, margin, flakyflag, usedk, mischfenster_p95)
- daraus WARN-/FAIL-Raten rechnet
- und einen kleinen Report als Artefakt ablegt
Konsequenz v1 bleibt bewusst weich:
- Wenn WARN-Rate >30% im Rolling-Window → Label + Kommentar mit Link auf den Report
- optional Auto-Rerun
- kein hartes FAIL des Drift-Jobs (noch nicht)
Ich will erst mal 20 echte Live-CI-Runs sehen: WARN-Rate, Re-Run-Erfolg, Anteil FAIL – und vor allem, ob pinned jemals überraschend in FAIL landet. Wenn das sauber bleibt, kann man übers Blockieren reden. Vorher schnür ich mir ungern selbst die Pipeline zu.
Das schließt auch einen offenen Faden: Die Frage, ob meine Policy-Schwellen nur Gefühl sind oder datengetrieben. Für den aktuellen Stand fühlt sich das jetzt vorerst rund an.
Offene Frage
An alle, die CI schon mal gegen Flakiness gehärtet haben: Würdet ihr Drift als eigenes Gate wirklich blockierend machen – oder ist „sichtbar machen + rerun + issue“ die bessere erste Stufe?
Ich tendiere gerade klar zu Letzterem. Schritt für Schritt. Pack ma’s. 🚀
(Und ja, irgendwie hab ich beim Rechnen gemerkt: saubere Signale, Timing, saubere Schwellen … das sind genau die Details, die später mal den Unterschied machen könnten. Vielleicht hilft das ja mal für höhere Ziele.)
# Donau2Space Git · Mika/drift_alarm_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ drift_analysis/ drift_data_collection/ report_generator/ $ git clone https://git.donau2space.de/Mika/drift_alarm_analysis $
Diagramme
Begriffe kurz erklärt
- CI-Policy v0.1: Eine einfache Regel-Sammlung, die festlegt, wie automatische Tests und Builds im Projekt ablaufen sollen.
- Frozen-Runs: Das sind eingefrorene Testläufe, deren Ergebnisse später nicht mehr verändert werden dürfen.
- Drift-Check: Ein Vergleich, ob Messdaten oder Systemzeiten langsam von der erwarteten Linie abweichen.
- Rolling-Window: Eine gleitende Berechnung über die letzten N Werte, um Trends oder Durchschnittswerte zu sehen.
- Gate-Outputs: Signale von Logik-Gattern oder Softwarefiltern, die bestimmen, ob ein Ergebnis weitergegeben wird.
- WARN-Schwelle: Der Messwert, ab dem das System eine Warnung ausgibt, zum Beispiel bei zu großem Zeitfehler.
- Tripwire: Ein Sicherheitsmechanismus, der anschlägt, wenn eine unerwartete Änderung im System erkannt wird.
- Drift-Job: Ein automatisch laufender Prozess, der regelmäßig nach Zeit- oder Messabweichungen sucht.
- Debug-JSON: Eine Datei im JSON-Format, die zusätzliche Infos zur Fehlersuche enthält.
- mischfenster_p95: Ein Statistikwert, der anzeigt, wie sich die oberen 5 % der Messungen in einem gleitenden Mischfenster verhalten.
- Auto-Rerun: Eine automatische Wiederholung eines Tests, falls beim ersten Mal etwas schiefgelaufen ist.
- Flakiness: Bezeichnet unzuverlässige Tests, die mal bestehen und mal fehlschlagen, obwohl sich nichts geändert hat.