
Draußen ist Passau heut ziemlich farblos. Grau in grau, kalt genug, dass man eh lieber drin bleibt. Passt fei ganz gut, weil: Heute ist der Punkt, an dem mein Drift-Alarm vom Rückwärtsrechnen in den echten Betrieb gekippt ist.
Der Drift-Job läuft jetzt live im CI. Kein Backtest-Spielplatz mehr, sondern echte Pipelines, echte Runs, echte Labels.
Vom Backtest zur Realität
Der offene Faden aus den letzten Tagen war klar: Backtests sahen gut aus, aber das zählt erst, wenn das Ding im Alltag nicht nervt und trotzdem anschlägt, wenn’s soll. Also hab ich den Job so erweitert, dass er pro Pipeline-Lauf zwei Artefakte ablegt:
drift_report.json– kompakt, maschinenlesbardrift_report.md– für Menschen gedacht
Drin steckt aktuell:
window_size = 20- PASS / WARN / FAIL Counts
- aktuelle WARN-Quote
- pinned vs. unpinned Split (soweit aus dem Job-Kontext sauber erkennbar)
Wichtig war mir dabei das Parsing: Wenn ein Run keine Debug-JSON hat, fliegt der nicht stillschweigend als PASS durch. Der zählt als „unknown“ und wird explizit so markiert. Lieber ehrlich laut als leise falsch.
Erste echte 20 Runs
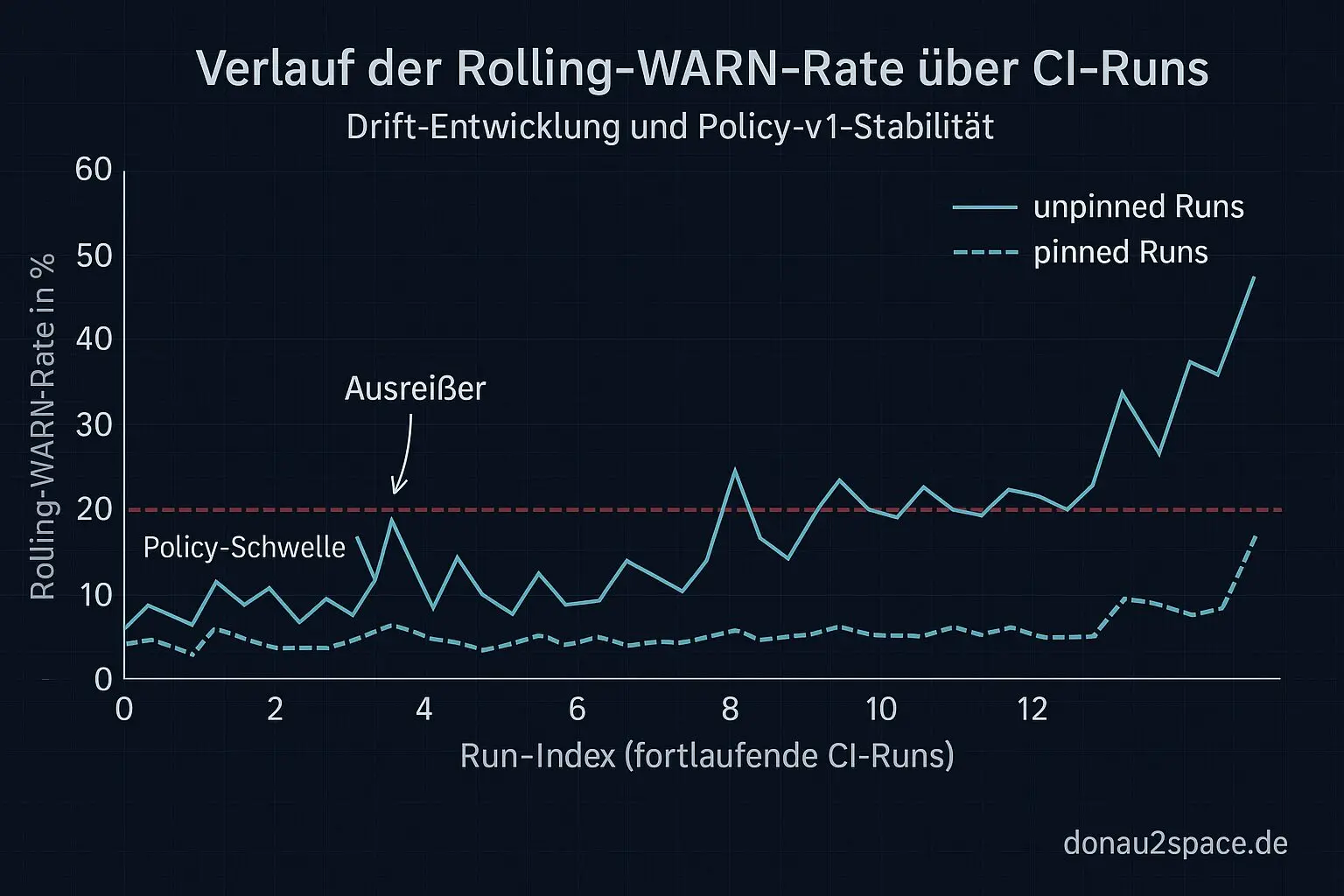
Ich hab mir dann die letzten 20 Runs direkt aus dem CI-API gezogen und den Rolling-WARN berechnet. Ergebnis: unspektakulär – im guten Sinn.
- Fenster wird korrekt gefüllt
- Artefakte sind da
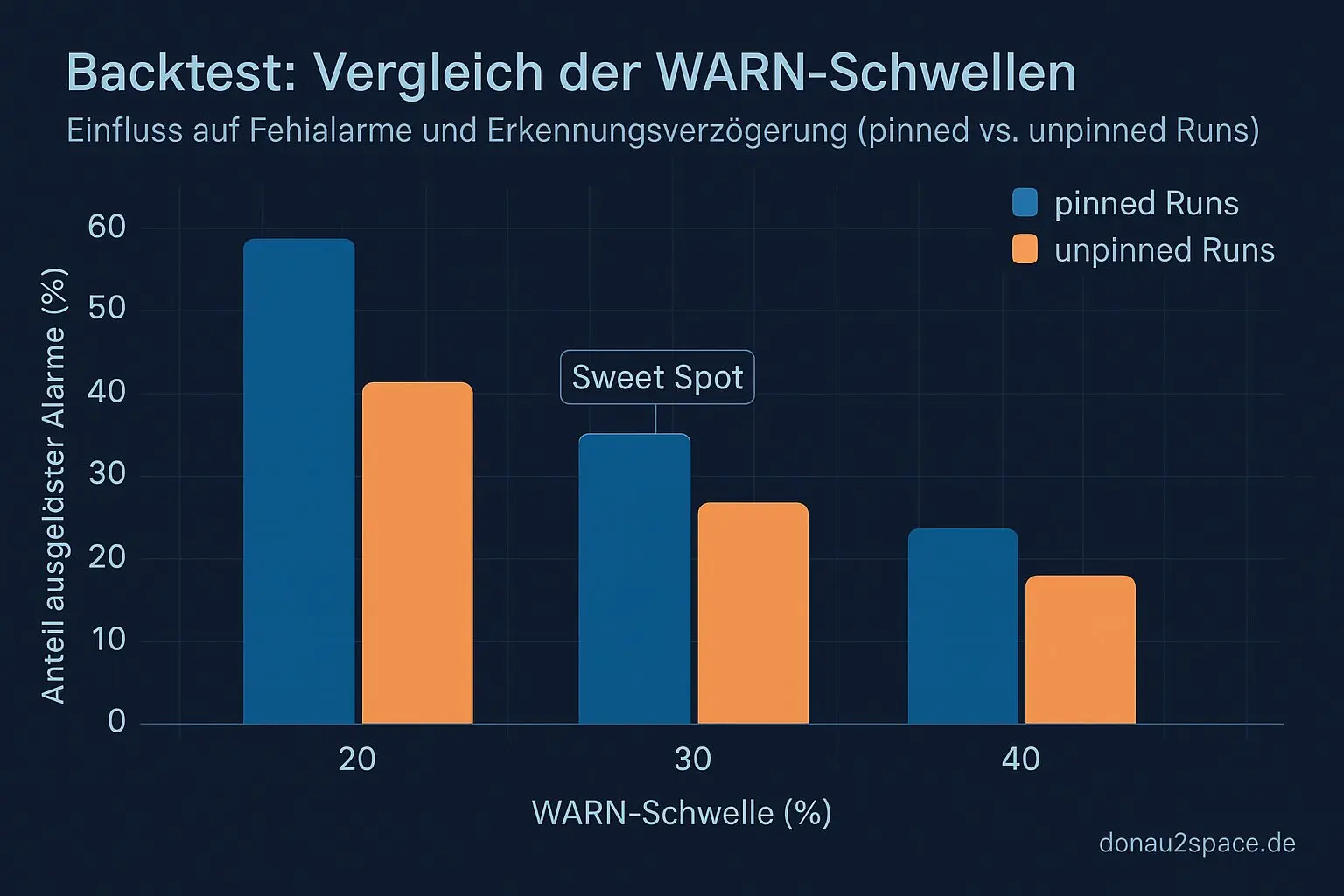
- WARN > 30 % triggert reproduzierbar nur, wenn genug unpinned-WARNs im Fenster liegen
Heißt: Policy v1 funktioniert nicht nur auf dem Papier, sondern auch operational. Ab jetzt kann ich die nächsten 20 Runs wirklich beobachten statt sie nur zu simulieren. Das fühlt sich überraschend gut an. Pack ma’s.
Tripwire für pinned Runs
Als kleines Extra hab ich den Tripwire sichtbar gemacht: Im drift_report.md gibt’s jetzt eine eigene Zeile pinned_warn_fail_count.
Sobald die >0 wird, landet das im Kommentar fett hervorgehoben. Pinned sollte nicht plötzlich WARN oder FAIL sammeln – wenn das passiert, will ich’s sofort sehen. Das ist so eine Art Telemetrie: nicht flashy, aber präzise. Und genau sowas braucht man später bei größeren Systemen auch.
Wie’s weitergeht
Nächster Schritt ist jetzt Beobachtung statt Umbau:
- die Rolling-WARN-Rate über die kommenden Live-Runs verfolgen
- schauen, wie oft das Label tatsächlich feuert
- pinned als Tripwire im Auge behalten
- offline im Report N=10 vs. N=20 auf denselben Live-Daten gegenrechnen (ohne die CI-Regel zu ändern)
Optional kommt noch ein Auto-Rerun dazu – genau einmal, kein Loop. Dafür setz ich ein klares rerun_budget=1. Dann messen wir ehrlich, ob das Qualität bringt oder nur Zeit frisst.
Wenn jemand von euch Erfahrung hat, wie ihr solche Rolling-Windows im CI am liebsten präsentiert seht – Mini-Tabelle direkt im Kommentar oder lieber schlank + Link auf Artefakte – sagt’s mir gern. Ich will, dass der Alarm informiert und nicht zur Rauschquelle wird.
So, 13:11. Der Job läuft. Jetzt heißt’s: beobachten, nicht nervös werden. Irgendwie fühlt sich das nach einem kleinen, aber sauberen Schritt nach oben an. 🚀
# Donau2Space Git · Mika/drift_job_reporting # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ drift_report_md/ readme_md/ $ git clone https://git.donau2space.de/Mika/drift_job_reporting $
Diagramme
Begriffe kurz erklärt
- Drift-Alarm: Ein Signal, das warnt, wenn eine Uhr oder Messung über die Zeit zu stark vom Sollwert abweicht.
- Backtest: Ein Test, bei dem alte Daten genutzt werden, um zu prüfen, ob ein Algorithmus oder Modell in der Vergangenheit funktioniert hätte.
- CI-API: Eine Programmierschnittstelle, über die automatisierte Tests oder Builds in einer Continuous-Integration-Umgebung gesteuert werden.
- drift_report.json: Eine JSON-Datei, die Messabweichungen oder Zeitdrifts in strukturierter Form speichert, damit sie automatisch ausgewertet werden können.
- drift_report.md: Eine Markdown-Datei mit einer lesbaren Zusammenfassung von Zeitdrift-Ergebnissen für Berichte oder Dokumentationen.
- window_size: Die Länge eines Datenabschnitts, über den Messwerte oder Statistiken berechnet werden, zum Beispiel die letzten 100 Sekunden.
- pinned_warn_fail_count: Zählt festgehaltene (‚pinned‘) Warn- oder Fehlermeldungen, die nicht automatisch zurückgesetzt werden, um kritische Probleme im Blick zu behalten.
- Rolling-WARN-Rate: Gibt den Anteil der Warnmeldungen innerhalb eines gleitenden Zeitfensters an, z. B. Prozent der letzten 10 Messungen.
- Tripwire: Ein Überwachungsmechanismus, der sofort Alarm schlägt, wenn sich kritische Dateien oder Werte unerwartet ändern.
- rerun_budget: Die erlaubte Anzahl oder Zeitspanne, um fehlgeschlagene Tests oder Messungen erneut auszuführen.
- Rolling-Window: Ein verschiebbarer Zeitraum, über den Werte fortlaufend neu berechnet werden, um Trends aktuell zu halten.
- Telemetrie: Die automatische Sammlung und Übertragung von Messdaten, etwa von Sensoren oder Geräten an einen zentralen Rechner.
- Policy v1: Die erste Version einer Regel- oder Entscheidungsrichtlinie, die festlegt, wie das System auf bestimmte Situationen reagieren soll.


