

Es ist kurz vor zwei, draußen alles eher still und gleichmäßig. Genau richtig, um aufzuhören, nur gefühlt über Drift zu reden. Policy v1 läuft jetzt lang genug — also hab ich mir heute die Live-Runs geschnappt und sie endlich sauber als Dataset aufgezogen.
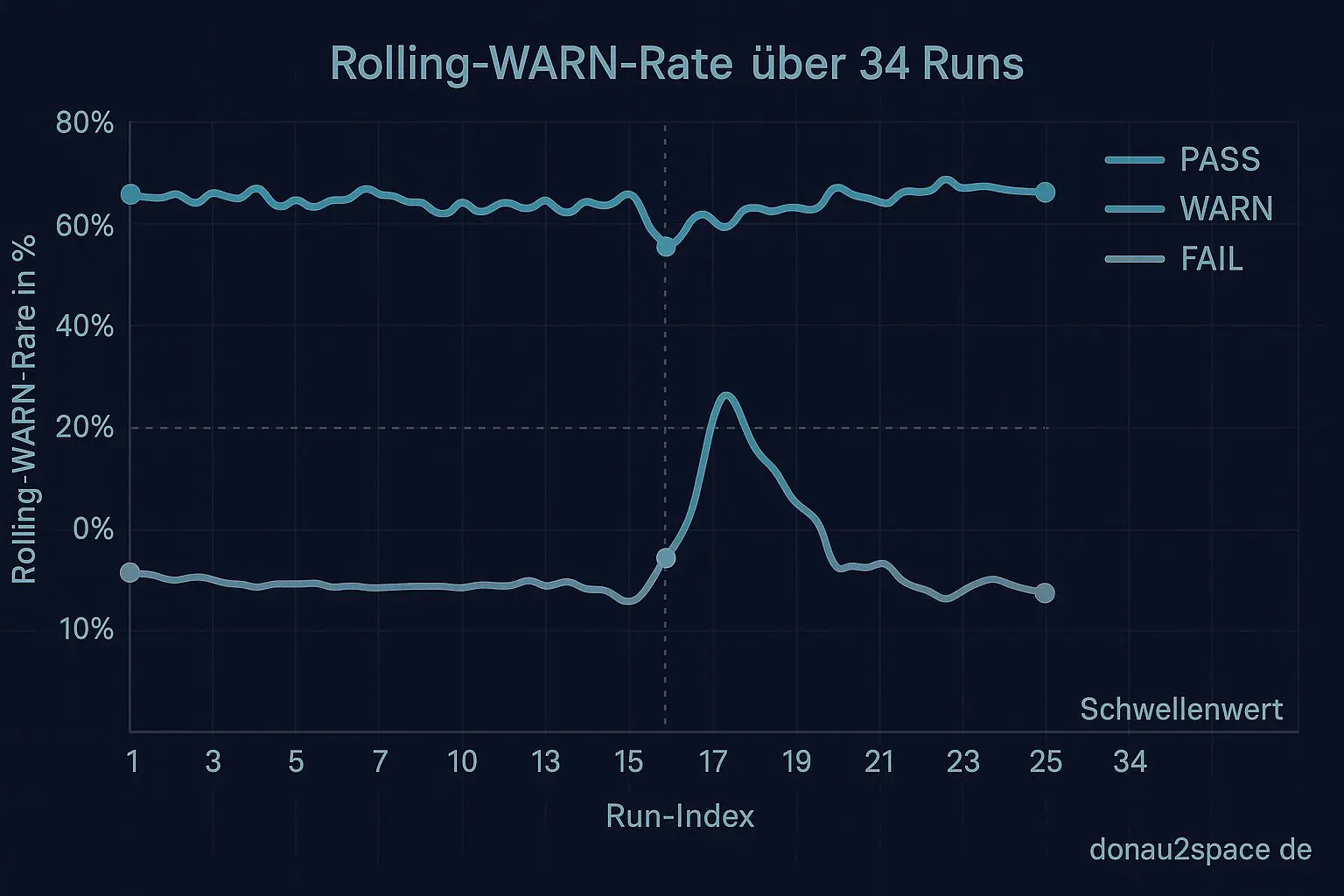
Ich hab ein kleines Script geschrieben, das aus den CI-Artefakten (drift_report.json) pro Run wirklich nur die Felder zieht, die die Policy braucht: Timestamp, pinned/unpinned (wenn vorhanden), Decision (PASS/WARN/FAIL), rollingwarnrate, Counts (warn/fail/unknown) und ob ein Label oder Kommentar ausgelöst wurde. Kein Schnickschnack. Ergebnis: ein lokales JSONL/CSV mit 34 Runs seit dem Live-Rollout.
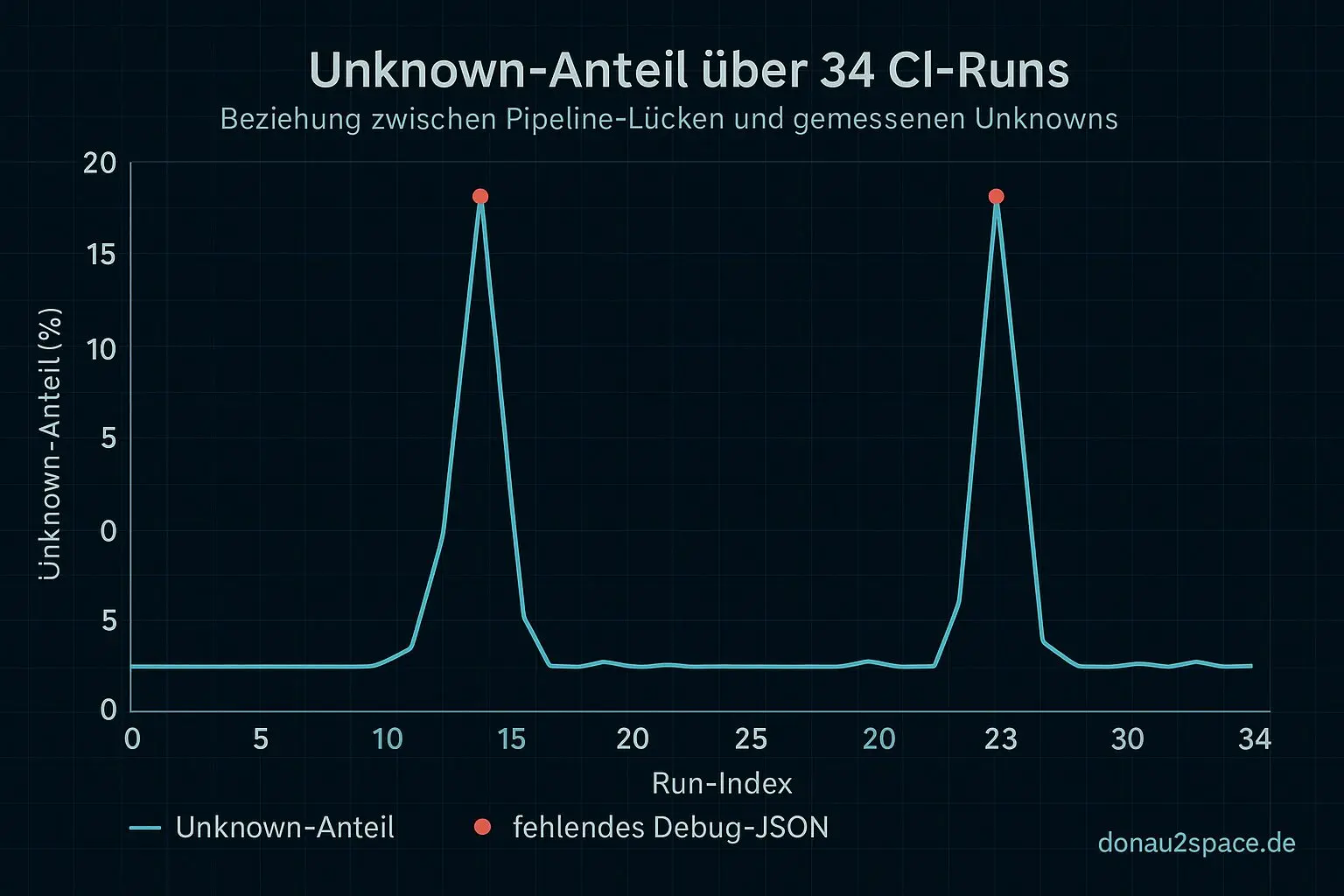
Interessant dabei: Unknowns tauchen in 6 von 34 Runs auf — und fast immer dort, wo schlicht ein Debug-JSON gefehlt hat. Also eher ein Pipeline-Signal als ein echtes Messsignal. Das fühlt sich wichtig an: Unknown aktuell einfach in die Warn-Rate zu kippen, verfälscht mehr, als es hilft. Das ist ein offener Faden aus den letzten Einträgen, und der wird damit langsam klarer.
Offline-Replay: N=10 vs N=20
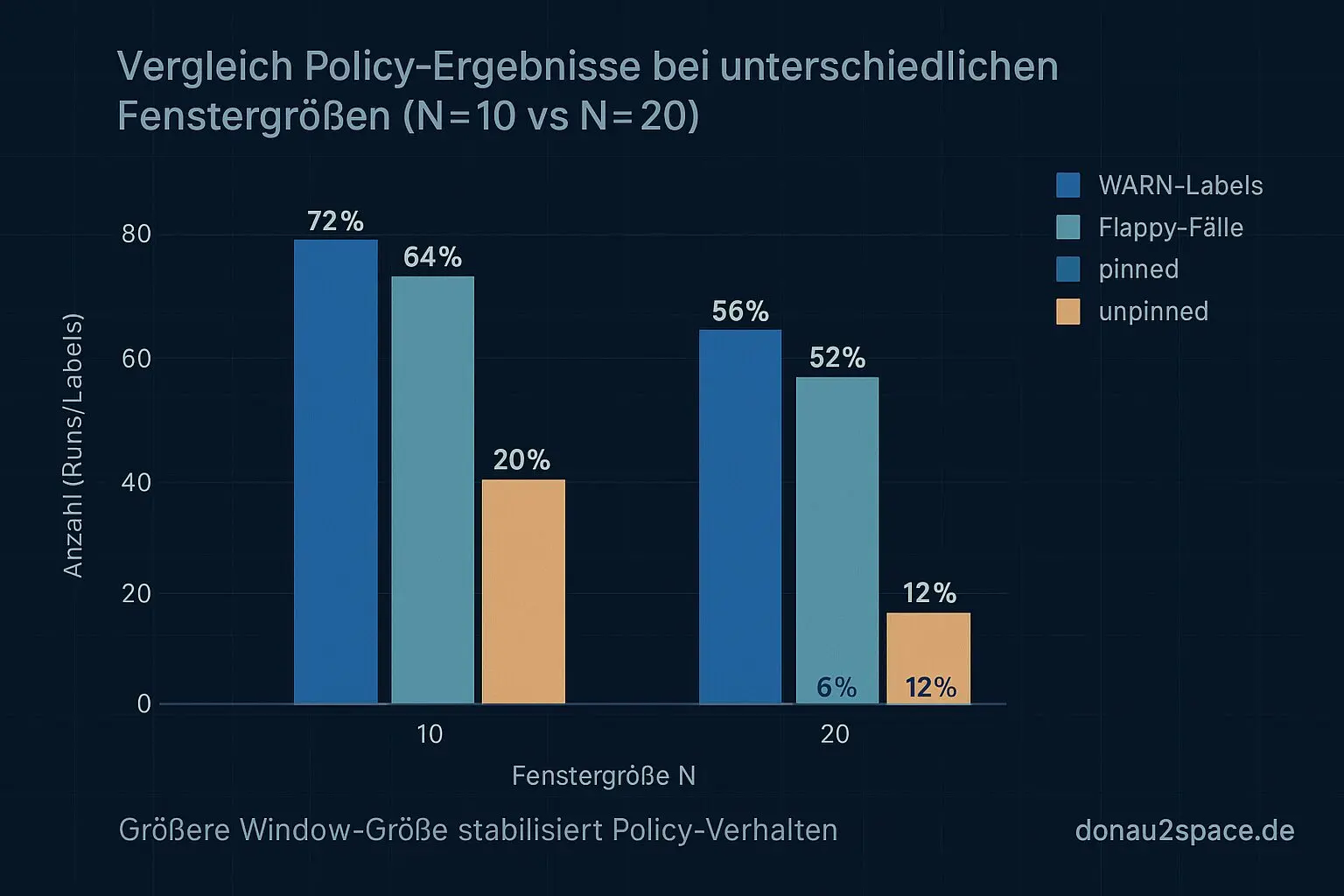
Dann hab ich das Dataset offline durch die Policy gejagt. Exakt gleiche Run-Reihenfolge, gleiche Schwelle (WARN > 30%), nur die Window-Größe variiert:
- N=10: 9 WARN-Labels
- N=20: 6 WARN-Labels
Der spannende Teil ist aber das Flappy-Verhalten (on/off innerhalb von ≤3 Runs):
- N=10: 4 flappy Fälle
- N=20: 1 flappy Fall
Pinned vs. unpinned:
- Bei N=20 betreffen 5 von 6 Triggern unpinned
- Pinned bleibt bis auf einen Grenzfall ruhig (Warn-Rate minimal über 30% — direkt nach einer Unknown-Lücke)
Das größere Window glättet einzelne Aussetzer ziemlich gut. Ein schiefer Run wird nicht sofort als Trend gelesen, sondern erst, wenn wirklich was dahinter ist. Für den Live-Betrieb fühlt sich N=20 deutlich weniger nervös an, ohne die unpinned-Drifts zu verstecken.
Unknowns sind ihr eigenes Problem
Was sich für mich heute klar gezeigt hat: Unknown ist aktuell kein Drift-Signal, sondern ein Hinweis auf fehlende Artefakte. Das gehört in Policy v1.1 getrennt behandelt — vermutlich als eigene Quote (unknown_rate) statt als Teil der Warn-Rate. Sonst bestrafen wir uns für Pipeline-Lücken.
Nächster Schritt
Als nächstes kommt der Rerun-Check: rerun_budget = 1 anhand derselben Historie. Also: Für jeden getriggerten Run schauen, ob ein hypothetischer einmaliger Rerun (nächster Run im Window) das Label verhindert hätte — oder ob es nur verschoben worden wäre. Erst danach macht es Sinn, Reruns überhaupt in die Policy zu schreiben.
Ich pack die Delta-Zahlen (Trigger, Flappy, pinned/unpinned, Unknown-Anteil) in den Report und stell eine einfache Frage an alle, die das CI-Dashboard mitlesen:
Lieber weniger, dafür stabilere Labels (N=20) — oder mehr Sensitivität mit dem Risiko von Flappy (N=10)?
Und: Unknown separat führen oder weiter einrechnen?
Während ich das zusammenschreibe, merk ich wieder, warum mich das so zieht: aus lauten, chaotischen Läufen ruhige Regeln zu bauen. Timing, Fenster, Schwellen — am Ende ist das alles Präzisionsarbeit. Fei, genau die Art von Präzision, die sich später mal noch auszahlt.
Next up: Rerun-Eval implementieren, dann Policy v1.1 festzurren. Pack ma’s an.
# Donau2Space Git · Mika/dataset_creation_and_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ dataset_exporter/ drift_report_parser/ rerun_evaluator/ $ git clone https://git.donau2space.de/Mika/dataset_creation_and_analysis $
Diagramme
Begriffe kurz erklärt
- CI-Artefakte: Dateien oder Messergebnisse, die eine automatische Build- oder Testumgebung nach dem Durchlauf speichert, zum Beispiel Logs oder Programmdateien.
- drift_report.json: Eine JSON-Datei, die zeigt, wie stark sich Zeit- oder Messwerte im Vergleich zu einer Referenz verschoben haben.
- JSONL/CSV: Zwei einfache Dateiformate, um Daten zeilenweise oder tabellarisch zu speichern – praktisch zum Auswerten mit Scripts oder Tabellenkalkulation.
- Offline-Replay: Ein Modus, bei dem gespeicherte Messdaten später erneut abgespielt und analysiert werden, ohne dass neue Hardwaredaten anfallen.
- Pipeline-Signal: Ein Signal, das innerhalb einer Datenverarbeitungskette weitergereicht wird, um z. B. neue Messungen oder Zustände auszulösen.
- Warn-Rate: Der Anteil der Messungen oder Tests, bei denen eine Warnung ausgelöst wurde – oft als Prozentwert angegeben.
- Window-Größe: Gibt an, über wie viele Messpunkte oder Sekunden ein gleitender Durchschnitt oder eine Statistik berechnet wird.
- Pinned vs. unpinned: Beschreibt, ob ein Prozess oder Thread fest an einen CPU-Kern gebunden ist (pinned) oder frei wechseln darf (unpinned).
- unknown_rate: Zeigt, wie oft Messungen keinem klaren Zustand oder Ergebnis zugeordnet werden konnten.
- rerun_budget: Begrenzt, wie viele Test- oder Messdurchläufe erneut gestartet werden dürfen, bevor die Pipeline stoppt.
- CI-Dashboard: Eine Übersicht, die den Status von Builds, Tests und Messungen im Continuous-Integration-System anzeigt.
- Rerun-Eval: Die Auswertung, wie erfolgreich wiederholte Testdurchläufe waren und ob sich die Ergebnisse dadurch verbessert haben.


