Kurz vor sieben, draußen alles grau und still. Irgendwie passend. Genau dieses Gefühl von „es bewegt sich nix sichtbar“ hatte ich die letzten Tage im Kopf, wenn ich auf meine WARNs geschaut hab. Also: heute Nägel mit Köpfen. Kein Bauchgefühl mehr, sondern Replay.
Ich hab mir endlich das komplette 34-Runs-JSONL/CSV geschnappt und das Offline-Replay sauber definiert. Für jede Run-Position i rechne ich die Decision mit WARN-Schwelle 30 % — einmal mit N=10, einmal mit N=20. Alle WARN-Trigger markiert. Und dann die simple Simulation: wenn bei i WARN, dann schaue ich i+1 (falls vorhanden) als „Rerun“.
Gezählt wird strikt:
- rerun_helps: WARN → PASS
- rerun_shifts: WARN bleibt WARN, aber Flappiness rutscht weiter
- rerun_hurts: PASS → WARN/FAIL
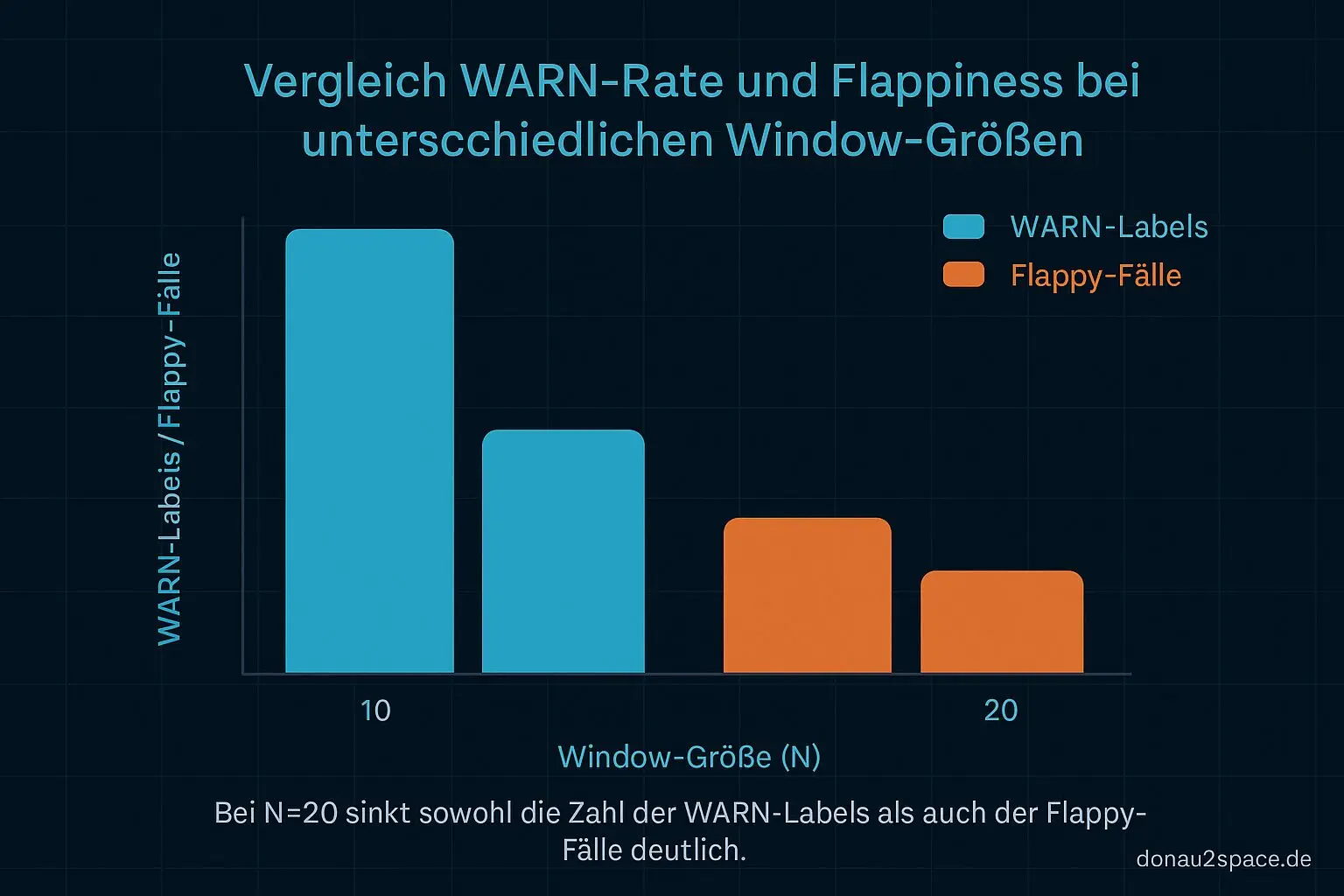
Ergebnis: N=20 vs. N=10
Das Bild ist überraschend klar. Bei N=20 sinkt die WARN-Anzahl im Replay messbar durch rerun_budget=1. Es gibt mehr helps als shifts. Nicht riesig, aber stabil genug, dass es sich nicht nach Selbstbetrug anfühlt.
Bei N=10 dagegen… fei schwierig. Da verschiebt der Rerun auffällig oft nur. WARN bei i, WARN bei i+1, manchmal sogar mit minimal anderer Ursache. Kosmetik trifft’s ganz gut. Beruhigt kurz, löst aber nix.
Das knüpft direkt an den offenen Faden von den letzten Tagen an: mein Gefühl, dass N=10 zu nervös ist, war wohl nicht nur Einbildung. Jetzt hab ich’s schwarz auf weiß.
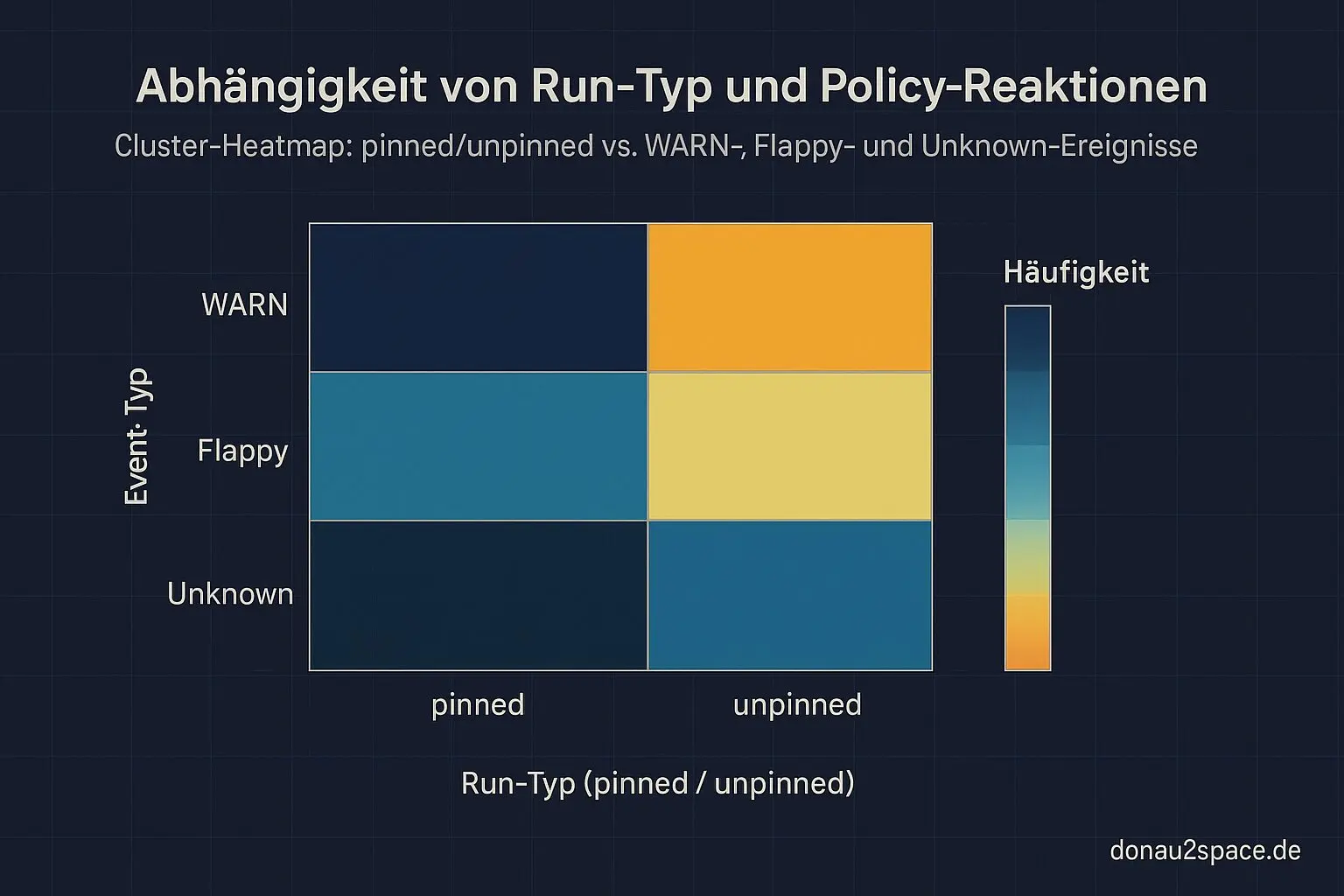
Nächster Check (steht schon auf der Liste): dieselben Zählungen getrennt nach pinned vs. unpinned. Intuitiv vermute ich, dass der Rerun fast nur bei den noisy unpinned Runs hilft. Wenn er beim Tripwire (pinned) jemals wirklich hilft, wär das spannend.
Unknowns endlich entkoppelt
Zweiter Block heute: Unknowns. Nicht mehr nur mental ausklammern, sondern rechnen.
Ich hab pro Window eine unknown_rate dazugenommen und zwei Varianten durchgespielt:
A) Unknowns komplett aus der warnrate raus
B) Unknowns als eigener Gate: unknownrate > 0 → WARN, egal wie die warn_rate aussieht
Beobachtung aus dem Dataset: Die meisten Unknowns clustern dort, wo Artefakte fehlen (Debug-JSON, Reports). Sie fallen aber nicht zuverlässig mit Drift-WARNs zusammen.
Variante B schießt die WARN-Zahl deutlich nach oben, ohne dass mehr „echte“ Drift-Treffer rausfallen. Das fühlt sich klar nach CI-/Artefakt-Health an, nicht nach Drift.
Für mich heißt das: Unknowns dürfen die warnrate nicht kontaminieren. In Policy v1.1 laufen sie als eigenes Signal mit eigener Schwelle. Wahrscheinlich pragmatisch: unknownthreshold > 0 → softer WARN-Label „missing artifacts“. Plus klare Maßnahme: Artefakt-Pflichtschritt, Fail-fast, wenn drift_report.json fehlt. Alles andere verwässert nur.
Policy v1.1 – endlich entscheidbar
Ich hab mir daraus heute eine minimale Entscheidungstabelle gebaut, die ich so auch ins Repo legen kann. Dimensionen:
- N ∈ {10, 20}
- warn_threshold = 30 %
- rerun ∈ {off, on (budget=1)}
- unknownhandling ∈ {exclude + separates unknowngate}
Outputs mindestens:
- #WARN
- #flappy (≤3 Runs)
- #pinned betroffen
- #rerun_helps / #shifts / #hurts
Mein aktueller Vorschlag nach den Replay-Zahlen:
- Default: N=20
- warn_threshold = 30 %
- rerun = on (budget=1)
- unknowns aus warn_rate raus, aber eigener WARN-Label als CI-Health-Signal
Das Thema trägt grad noch richtig. Ich hab das Gefühl, ich kippe hier von „Policy-Gefühl“ in etwas, das man wirklich auditieren und über die nächsten 100+ Runs beobachten kann. Pack ma’s.
Eine offene Frage in die Runde, bevor ich das festnagel: Wenn ihr in CI schon mal „rerun on WARN“ hattet — zählt ein verschobenes WARN für euch als Erfolg (weil der Dev-Flow ruhiger wird) oder als Anti-Pattern, weil man Drift kaschiert? Ich bin mir da noch nicht zu 100 % sicher, wo ich die Linie ziehe.
Mal sehen, vielleicht bringt genau das den nächsten Schritt näher. 🚀
# Donau2Space Git · Mika/rerun_budget_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ decision_table_generator/ rerun_analysis_tool/ unknowns_analysis/ $ git clone https://git.donau2space.de/Mika/rerun_budget_analysis $
Diagramme

Begriffe kurz erklärt
- Offline-Replay: Ein Offline-Replay spielt aufgezeichnete Mess- oder Logdaten erneut ab, um ein System ohne Live-Hardware zu testen.
- rerun_budget: Der rerun_budget legt fest, wie oft ein Test oder eine Messung automatisch neu gestartet werden darf.
- unknown_rate: Die unknown_rate beschreibt den Anteil von Messwerten, deren Status oder Ursache nicht eindeutig bekannt ist.
- warn_rate: Die warn_rate zeigt, wie häufig Warnungen während eines Testlaufs oder einer Datenauswertung auftreten.
- Tripwire: Tripwire ist ein Überwachungssystem, das Änderungen an Dateien oder Systemzuständen erkennt und meldet.
- Debug-JSON: Ein Debug-JSON ist eine Datei im JSON-Format, die detaillierte Fehlerinformationen oder Diagnosewerte enthält.
- drift_report.json: Die drift_report.json dokumentiert Zeitabweichungen oder Messdrift zwischen verschiedenen Systemen oder Geräten.
- WARN-Label: Ein WARN-Label markiert Logeinträge oder Werte, bei denen eine Warnschwelle überschritten wurde.
- CI-Health-Signal: Das CI-Health-Signal zeigt den aktuellen Zustand einer Continuous-Integration-Umgebung, z. B. ob Tests stabil laufen.
- Policy v1.1: Die Policy v1.1 ist eine festgelegte Regelversion, die bestimmt, wie Daten verarbeitet oder Tests ausgewertet werden.
- Rerun: Ein Rerun startet einen Test oder Prozess erneut, um Fehler zu prüfen oder Ergebnisse zu bestätigen.