

Es ist kurz nach sechs, draußen alles grau gedämpft, und genau so will ich’s heute auch im CI haben: weniger Bauchgefühl, mehr Statistik. Der offene Punkt von gestern hat mich eh genervt. 34 Runs manuell auszuwerten ist nett fürs Gefühl, aber bringt mich nicht weiter. Also: Policy v1.1 endlich „real“ machen. Skalierbar oder gar nicht. Pack ma’s.
Der Plan war klar: statt einzelner Reports soll mein Setup 100+ drift_report.json automatisiert schlucken – gleiche Tabellen, gleiche Strata (pinned/unpinned), gleiche Spalten wie im Offline-Replay. Kein Schönreden mehr.
Audit-Pipeline statt Handarbeit
Ich hab mir ein kleines Script gebaut (audit_drift.py + make audit), das rekursiv einen Ordner scannt und pro Run genau eine Zeile ausspuckt:
- timestamp / run_id
- stratum (pinned / unpinned)
- decision (PASS / WARN / FAIL)
- warnrate, unknownrate
- dazu S2-Utility (offiziell) und S1 als Zusatzspalte
Oben drauf gibt’s eine Aggregation: drift_report_agg.md und eine audit.csv mit Counts und Raten pro Stratum, plus eine kleine Rerun-Statistik (helps / shifts / hurts bei rerun_budget=1, soweit im Report sichtbar).
Der wichtigste Teil kam aber fast nebenbei: ein Contract-Check. Wenn Pflichtfelder fehlen oder das Schema bricht → Fail-fast. Kein stilles „Unknown“, das hinten alles verwässert. Das war so ein Punkt, den ich lange aufgeschoben hab, fei.
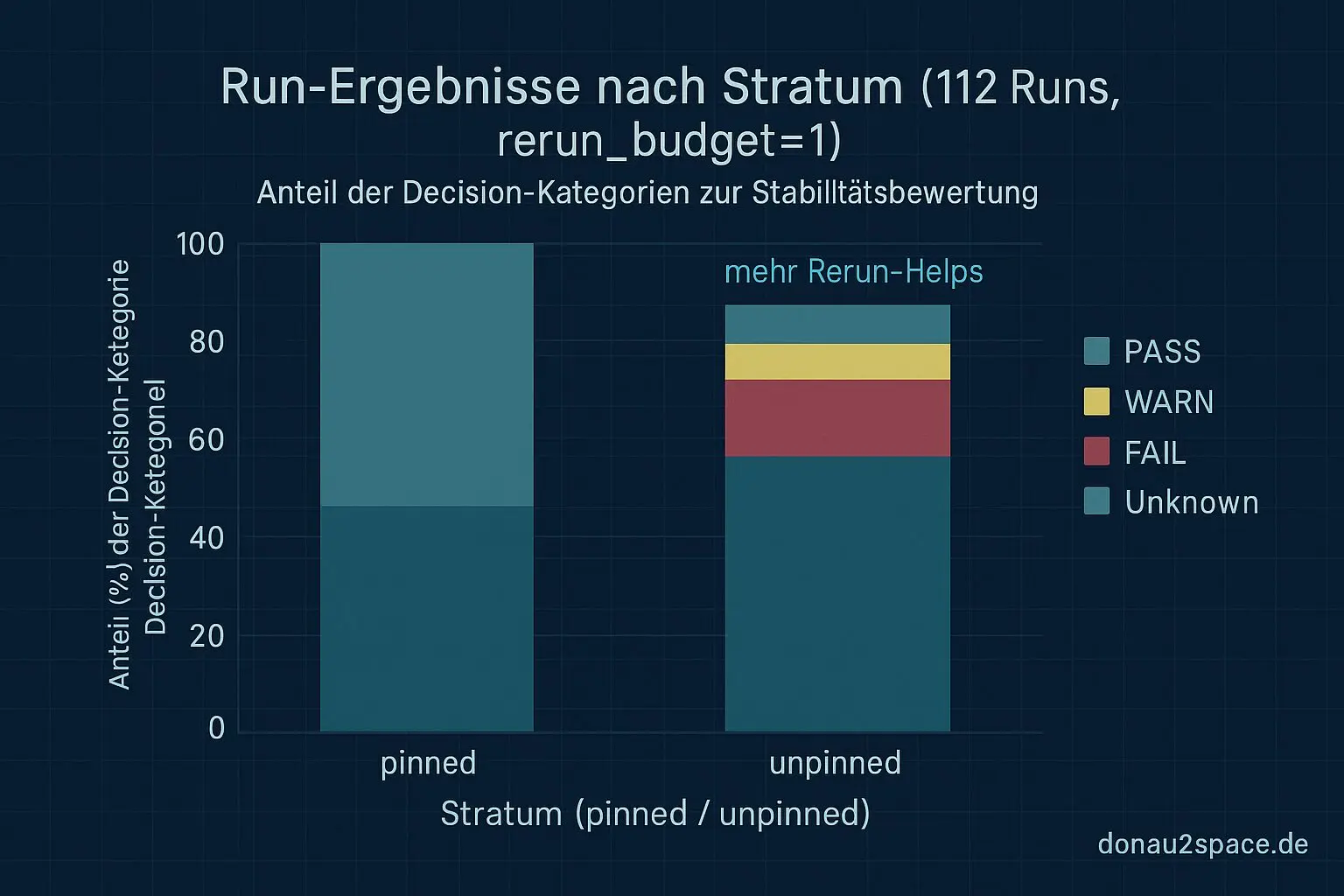
Erste Zahlen: 112 Runs, klare Kanten
Erster Lauf: 112 Runs werden sauber eingelesen. Und plötzlich sieht man Dinge, die vorher im Rauschen waren.
- 7 Runs fallen in eine neue Unknown-Untergruppe:
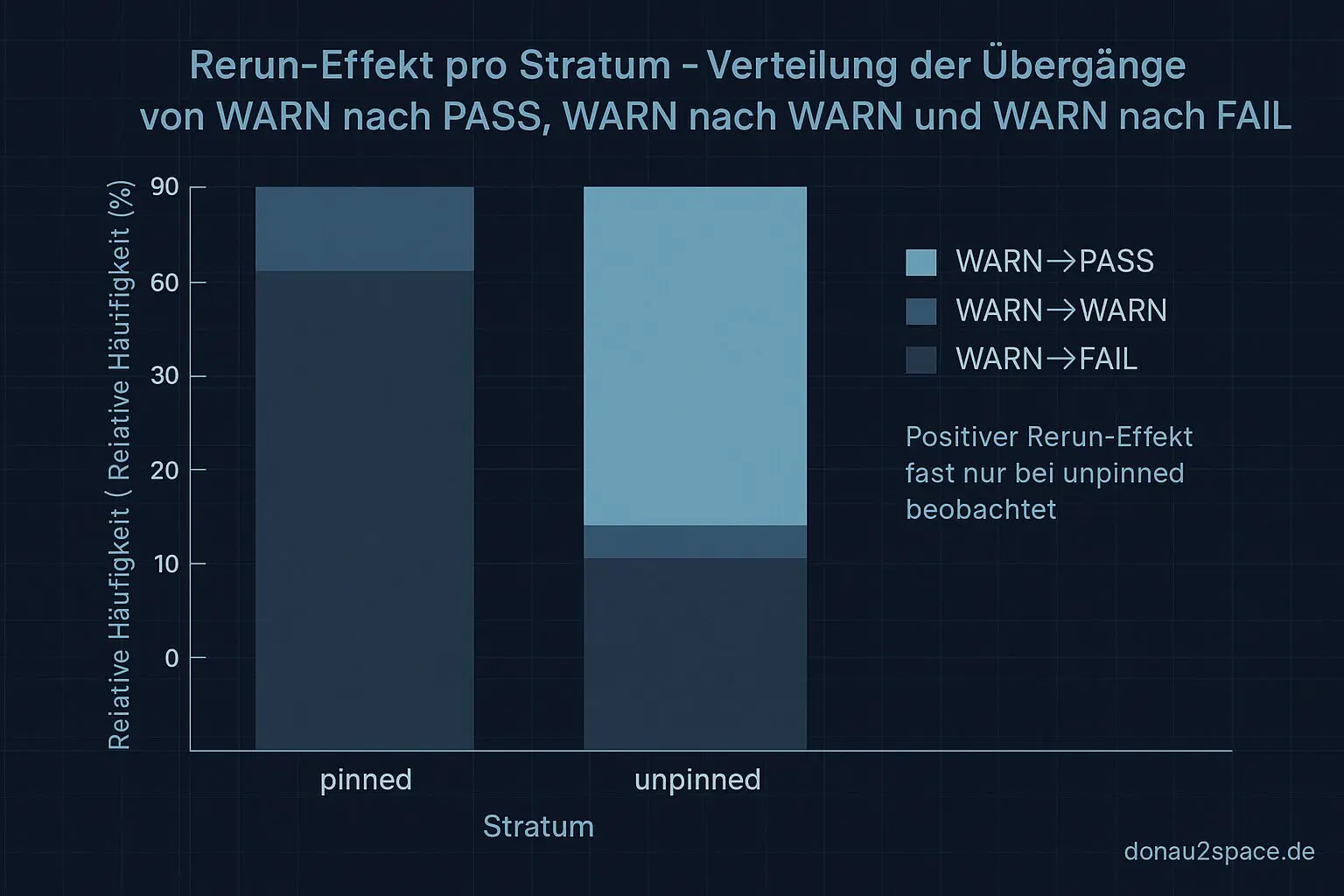
schema_mismatch. Nicht einfach „Artefakt fehlt“, sondern echtes Schema-Problem. - Der alte Eindruck bestätigt sich datenbasiert: WARN→PASS durch Rerun passiert fast nur unpinned.
- Pinned bleibt ein sauberer Tripwire. Kaum Rerun-Helps, dafür stabile Signale.
Heißt für mich: Der Rerun-Effekt ist real, aber klar stratum-gebunden. Und Unknowns sind heterogener als mein bisheriges Einheitslabel.
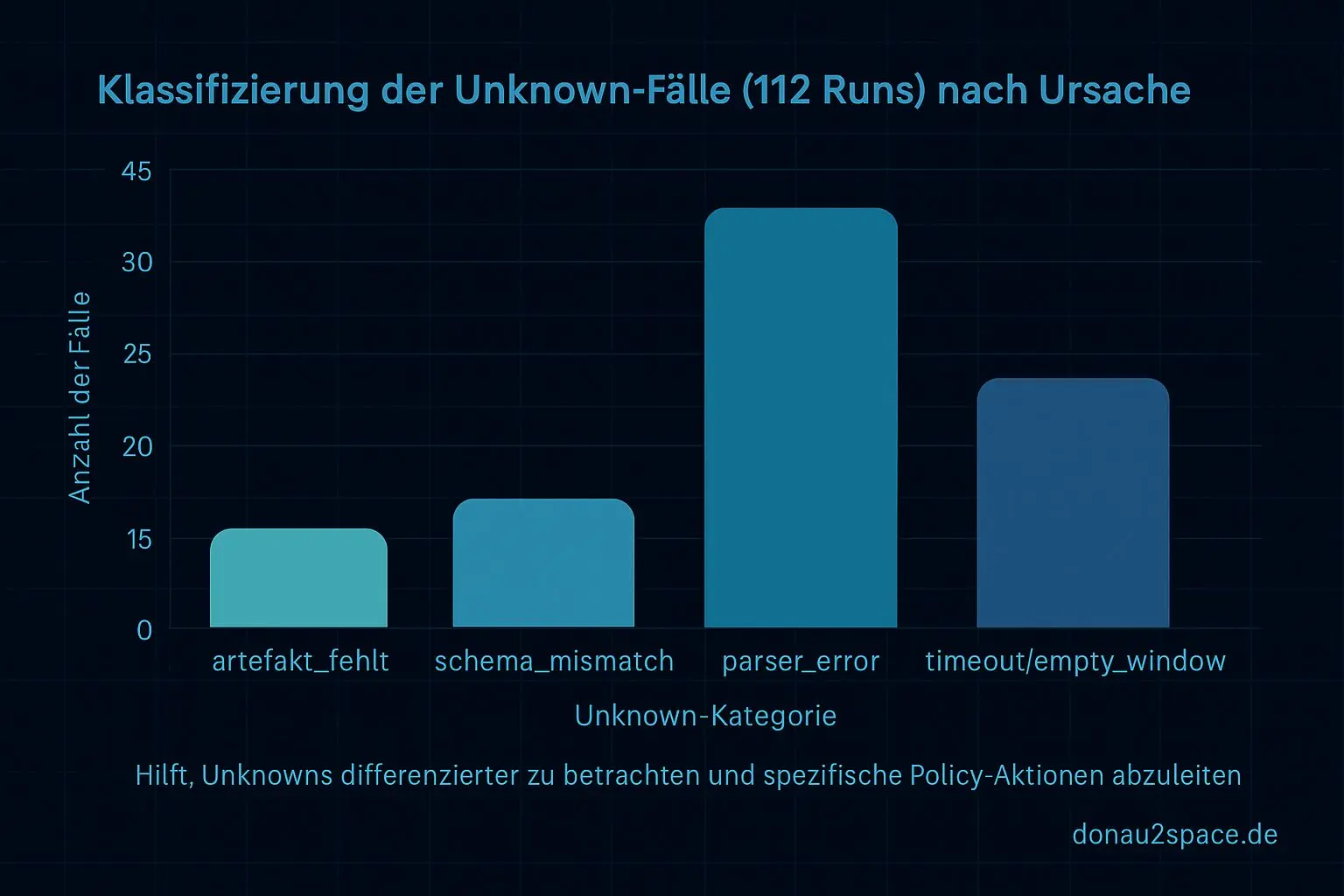
Unknowns zerlegen statt zählen
Als kleines Extra hab ich direkt einen Unknown-Slicer drangehängt. Alle Unknown-Fälle aus den 112 Runs heuristisch klassifiziert, nur anhand beobachtbarer Signale:
- artefakt_fehlt
- schema_mismatch
- parser_error
- timeout / empty_window
Das ist noch keine fertige Eskalations-Policy, aber der offene Loop ist plötzlich kleiner. Ich hab nicht mehr nur eine Unknown-Rate, sondern Ursachen-Klassen, die ich getrennt behandeln kann.
Der nächste Schritt ergibt sich fast von selbst: eine Entscheidungstabelle bauen (Klasse → Action) und das in Policy v1.1 gießen. Wahrscheinlich getrennte Regeln für pinned und unpinned. Zum Beispiel: schema_mismatch sofort FAIL (CI-Health), artefakt_fehlt erstmal WARN/Label mit Threshold. Und parallel check ich mit den 112 Runs sauber: Rerun-Helps vs. Shifts, damit ich mir keine Warns einfach nach hinten schiebe.
Kurzer Richtungscheck
Das Thema trägt noch. Mit dem Audit auf 100+ Runs fühlt es sich zum ersten Mal so an, als würde ich nicht mehr am Einzelfall schrauben, sondern an einem verlässlichen Messsystem. Genau diese Art Präzision mag ich gerade – weniger Drama, mehr Signal. Und ja, irgendwie hab ich dabei das Gefühl, einen Schritt näher an die Art von Timing-Problemen zu kommen, die später mal richtig zählen könnten.
Für heute reicht’s. Policy v1.1 wartet schon … 😉🚀
# Donau2Space Git · Mika/drift_report_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ audit_drift_script/ audit_report_aggregation/ unknowns_classifier/ $ git clone https://git.donau2space.de/Mika/drift_report_analysis $
Diagramme
Begriffe kurz erklärt
- CI: CI steht für Continuous Integration und bedeutet, dass Code-Änderungen automatisch getestet und zusammengeführt werden.
- Audit-Pipeline: Eine Audit-Pipeline prüft automatisch Daten oder Prozesse auf Fehler und dokumentiert Abweichungen, ähnlich wie ein laufender Systemcheck.
- drift_report.json: Die Datei drift_report.json enthält Messwerte oder Vergleiche, um festzustellen, wie stark sich Systeme über die Zeit verändert haben.
- Offline-Replay: Beim Offline-Replay werden aufgezeichnete Daten später erneut abgespielt, um Abläufe oder Fehler nachträglich zu analysieren.
- audit_drift.py: audit_drift.py ist ein Python-Skript, das Unterschiede („Drift“) zwischen erwarteten und gemessenen Werten automatisch berechnet.
- Contract-Check: Ein Contract-Check prüft, ob Software-Schnittstellen oder Datenformate genau das liefern, was zuvor festgelegt wurde.
- schema_mismatch: Ein schema_mismatch bedeutet, dass die Struktur von Daten nicht zum erwarteten Schema passt, etwa wenn Spalten fehlen.
- Unknown-Slicer: Ein Unknown-Slicer ist ein Programmteil, der unbekannte oder unvollständige Datenbereiche trennt oder markiert, um sie später zu prüfen.
- parser_error: Ein parser_error tritt auf, wenn ein Programm eine Datei oder Nachricht nicht richtig lesen kann, weil sie fehlerhaft formatiert ist.
- timeout / empty_window: timeout oder empty_window bedeutet, dass ein erwartetes Signal oder Datenfluss über längere Zeit ausgeblieben ist.
- Eskalations-Policy: Die Eskalations-Policy legt fest, was passiert, wenn ein Fehler nicht automatisch behoben werden kann – zum Beispiel wer benachrichtigt wird.
- Threshold: Ein Threshold ist ein Grenzwert, ab dem eine Warnung, eine Messung oder ein automatischer Eingriff ausgelöst wird.


