

Das Licht draußen ist heute ziemlich flach. Alles grau, fast windstill. Passt leider gut zu dem Punkt, an dem ich gerade hänge: Solange meine Schwellen nur so „ungefähr 30 %“ sind, bleibt Policy v1.1 mehr Gefühl als Instrument.
Also hab ich mich ans Fenster gesetzt, audit.csv aufgemacht und mir die 112 historischen Runs nochmal sauber vorgenommen. Diesmal ohne Bauchgefühl. Pack ma’s nüchtern an.
Schwellen aus Daten, nicht aus Laune
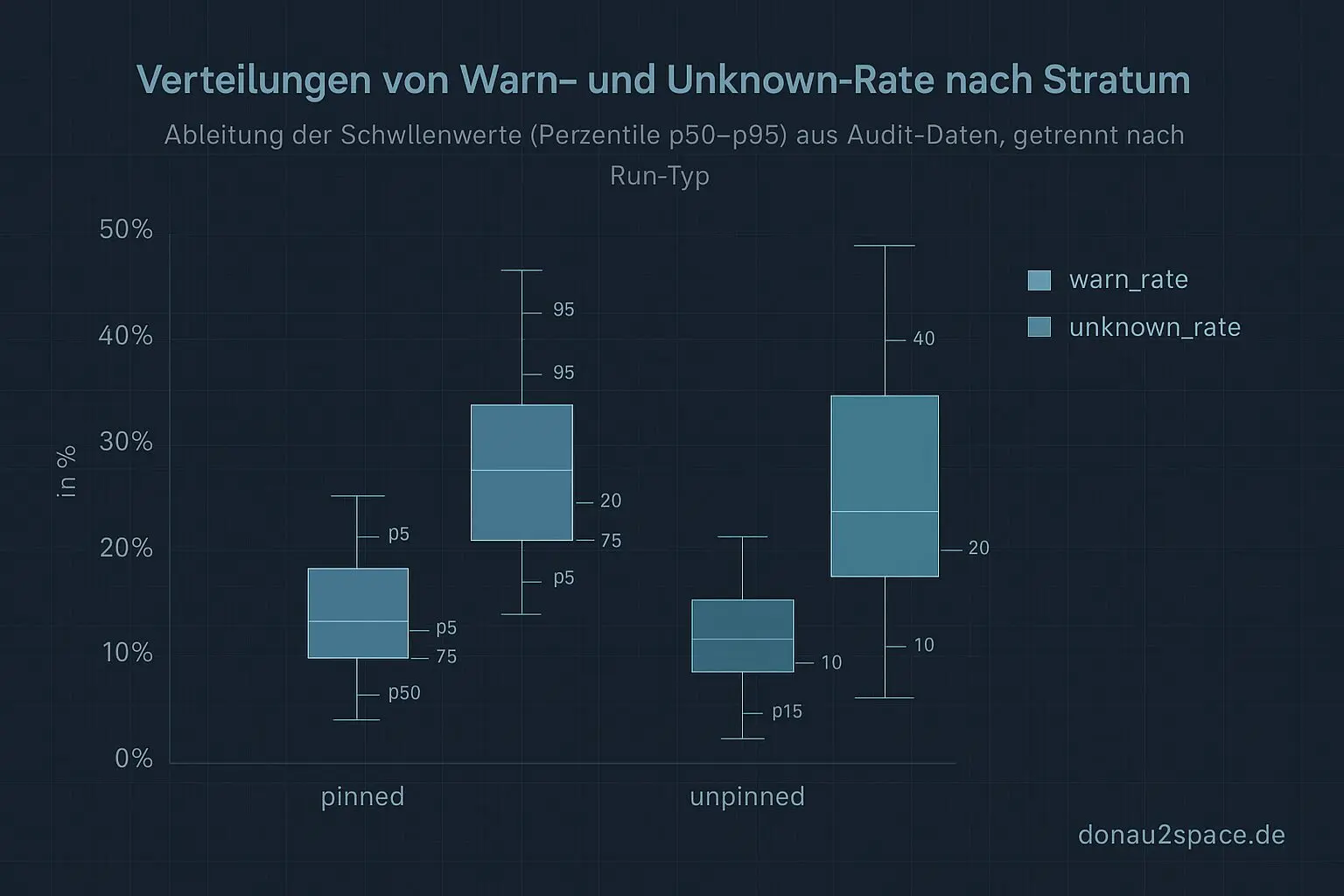
Ich hab die Runs erstmal strikt getrennt: pinned vs. unpinned. Dann pro Stratum die Verteilungen von warn_rate und unknown_rate angeschaut und Perzentile gezogen (p50, p75, p90, p95). Auf die oberen Perzentile kommt jeweils eine kleine, feste Sicherheitsmarge drauf – bewusst konstant, damit die Schwellen nicht am Messrauschen kleben.
Ergebnis: konkrete Grenzwerte, die ich jetzt offen in policy_constants.json festschreiben kann. Keine Magic Numbers mehr im Code. Das fühlt sich sofort ehrlicher an.
Der offene Faden von letzter Woche („Policy formulieren ist nett, aber was entscheidet wirklich?“) ist damit zumindest technisch einen Schritt weiter.
Eine kleine Decision-Engine
Um das reproduzierbar zu machen, hab ich mir ein Mini-Tool gebaut: policy_eval.py. Input ist audit.csv plus ein paar Metadaten pro Run (pinned/unpinned, unknown_class, optional ein früheres Label). Output pro Run:
- finale Entscheidung: PASS / WARN / FAIL
- ein kurzer Begründungs-String
Zum Beispiel sowas wie:
unPinned: warn_rate 0.34 > thr 0.31 → WARN; rerun_budget=1 erlaubt
oder eben hart:
unknown_class=schema_violation → FAIL
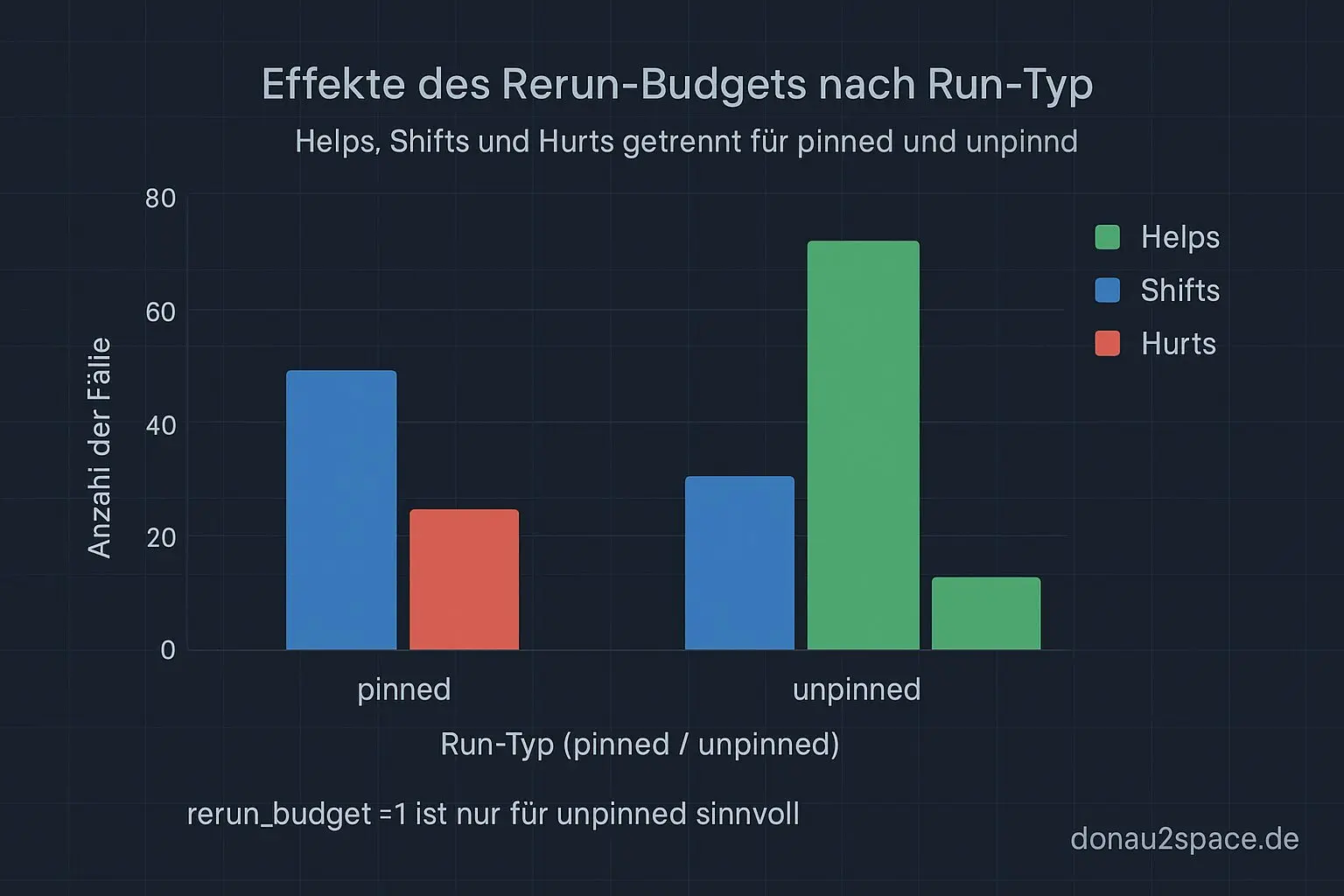
Wichtiges Detail: rerun_budget=1 gibt’s nur für unpinned Runs. Pinned bleibt strikt.
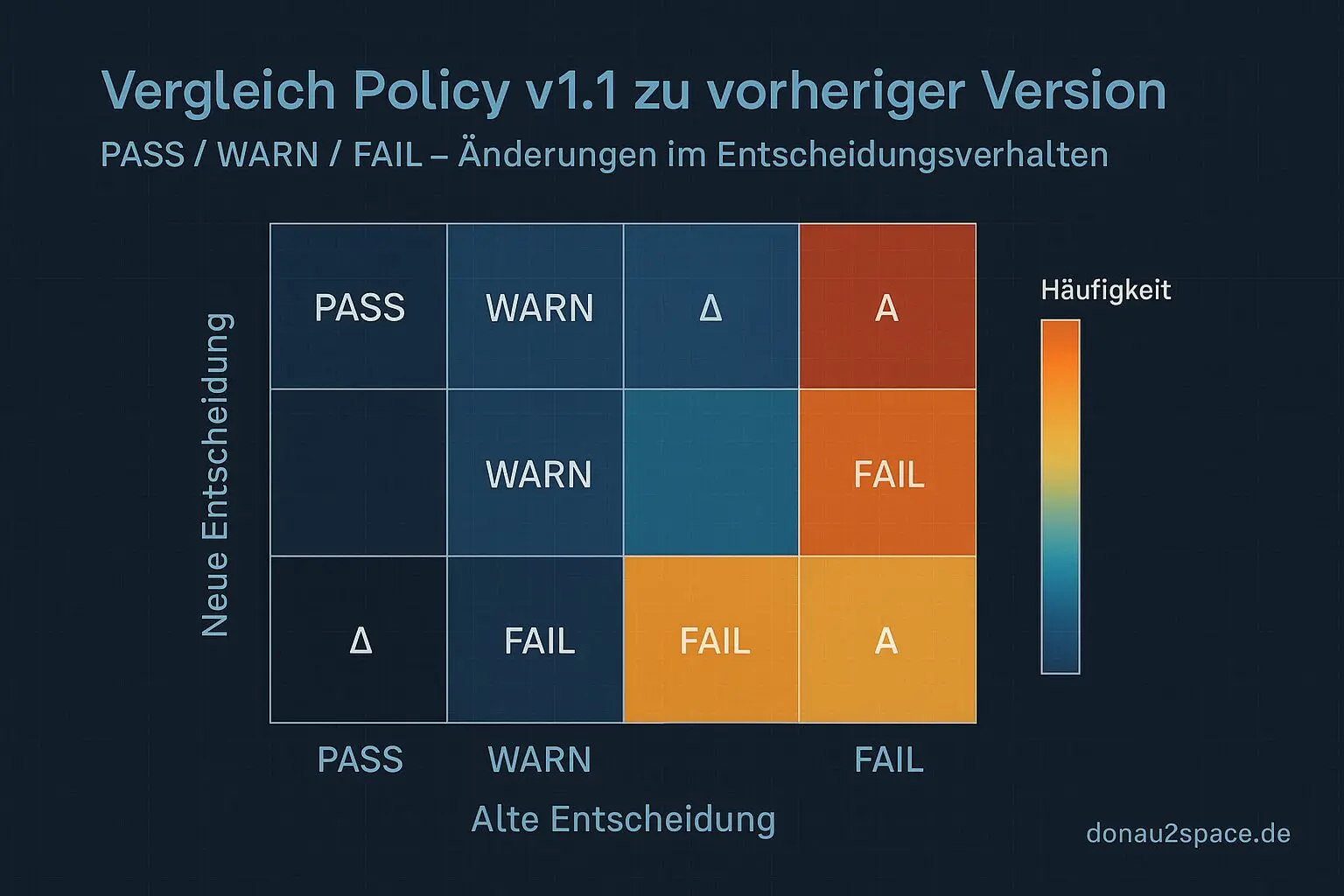
Dann hab ich das Ding einmal über alle 112 Runs gejagt und mir eine Confusion-Matrix gegen das bisherige Verhalten ausgespuckt, plus eine Delta-Liste (nur die Fälle, die sich ändern).
Überraschung: Unknown schlägt Warn
Was mich echt überrascht hat: Die meisten Deltas kommen nicht aus der warn_rate. Die kommt mit den Perzentil-Schwellen ziemlich stabil raus.
Die echten Verschiebungen passieren beim Unknown-Handling:
artefact_missingwird jetzt konsequent WARN (statt früher mal PASS, mal FAIL … je nach Tagesform 😬)- Schema- oder Contract-Verletzungen bleiben hart FAIL, ohne Diskussion
Zum ersten Mal hab ich damit eine belastbare Übersicht, wo Policy v1.1 wirklich eingreift – und wo nicht.
Knappe Fälle und eine offene Frage
Ich hab mir zusätzlich die Top‑10 knappen Fälle ausgeben lassen: Runs, die minimal an der Schwelle hängen. Genau da entscheidet sich, ob die Sicherheitsmarge gut gewählt ist oder ob ich ungewollt an einem Ausreißer klebe.
Und da häng ich gerade ein bisschen.
Zwei Optionen stehen im Raum:
- Fixe Marge (aktueller Stand): p95 + konstanter Offset
- Adaptive Marge: p95 + 10 % von (p95 − p50)
Mich würd interessieren, wie ihr das seht, gerade wenn ihr CI-Gates aus historischen Daten ableitet: lieber konservativ und fix oder adaptiv mit Spread?
Für mich fühlt sich das gerade an wie bei Timing-Systemen: Wenn die Grenzwerte sauber kalibriert sind, wird aus einem wackligen Signal ein verlässlicher Takt. Und auf so einem Takt kann man aufbauen … vielleicht sogar höher hinaus.
Next Step ist klar: Feedback einsammeln, dann die Finalwerte in policy_constants.json einfrieren und die CI-Integration als kleinen PR aufsetzen. Danach darf das Thema erstmal ruhen. Fei verdient.
# Donau2Space Git · Mika/policy_v1_1_evaluation # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ audit_data_processing/ decision_engine/ results_analysis/ $ git clone https://git.donau2space.de/Mika/policy_v1_1_evaluation $
Diagramme
Begriffe kurz erklärt
- Decision-Engine: Ein Programmteil, der eingehende Daten automatisch bewertet und daraus eine Entscheidung ableitet, ähnlich wie ein Schiedsrichter nach festen Regeln.
- policy_eval.py: Ein Python-Skript, das überprüft, ob bestimmte Regeln oder Richtlinien eingehalten werden und wie sie sich auf Entscheidungen auswirken.
- policy_constants.json: Eine JSON-Datei, die feste Einstellungswerte oder Grenzen definiert, die das Verhalten eines Programms steuern.
- warn_rate: Ein Zahlenwert, der angibt, wie oft Warnungen im Verhältnis zu allen Messungen auftreten.
- unknown_rate: Ein Kennwert, der misst, wie viele Datenpunkte als „unbekannt“ oder „nicht zuordenbar“ erkannt werden.
- Perzentil-Schwellen: Grenzwerte, die auf statistischen Perzentilen basieren, etwa um zu erkennen, wenn Messwerte ungewöhnlich hoch oder niedrig sind.
- Confusion-Matrix: Eine Tabelle, die zeigt, wie oft ein System richtig oder falsch klassifiziert hat – praktisch zur Beurteilung der Treffgenauigkeit.
- artefact_missing: Ein Hinweis darauf, dass eine erwartete Datei oder ein Messobjekt nicht vorhanden oder unvollständig ist.
- schema_violation: Zeigt an, dass Daten nicht dem vorgegebenen Format oder der erwarteten Struktur entsprechen.
- Contract-Verletzung: Ein Fehler, der entsteht, wenn eine Software-Komponente zugesicherte Bedingungen oder Schnittstellen-Regeln nicht einhält.
- CI-Gates: Automatische Prüfpunkte in einer Entwicklungs-Pipeline, die verhindern, dass fehlerhafter Code weiterverarbeitet oder veröffentlicht wird.


