

Draußen hängt der Himmel heute wie ein grauer Diffusor über Passau. Kein Schatten, kein Kontrast – nur gleichmäßiges Licht. Eigentlich perfekt, um am Schreibtisch zu bleiben und Zahlen anzuschauen.
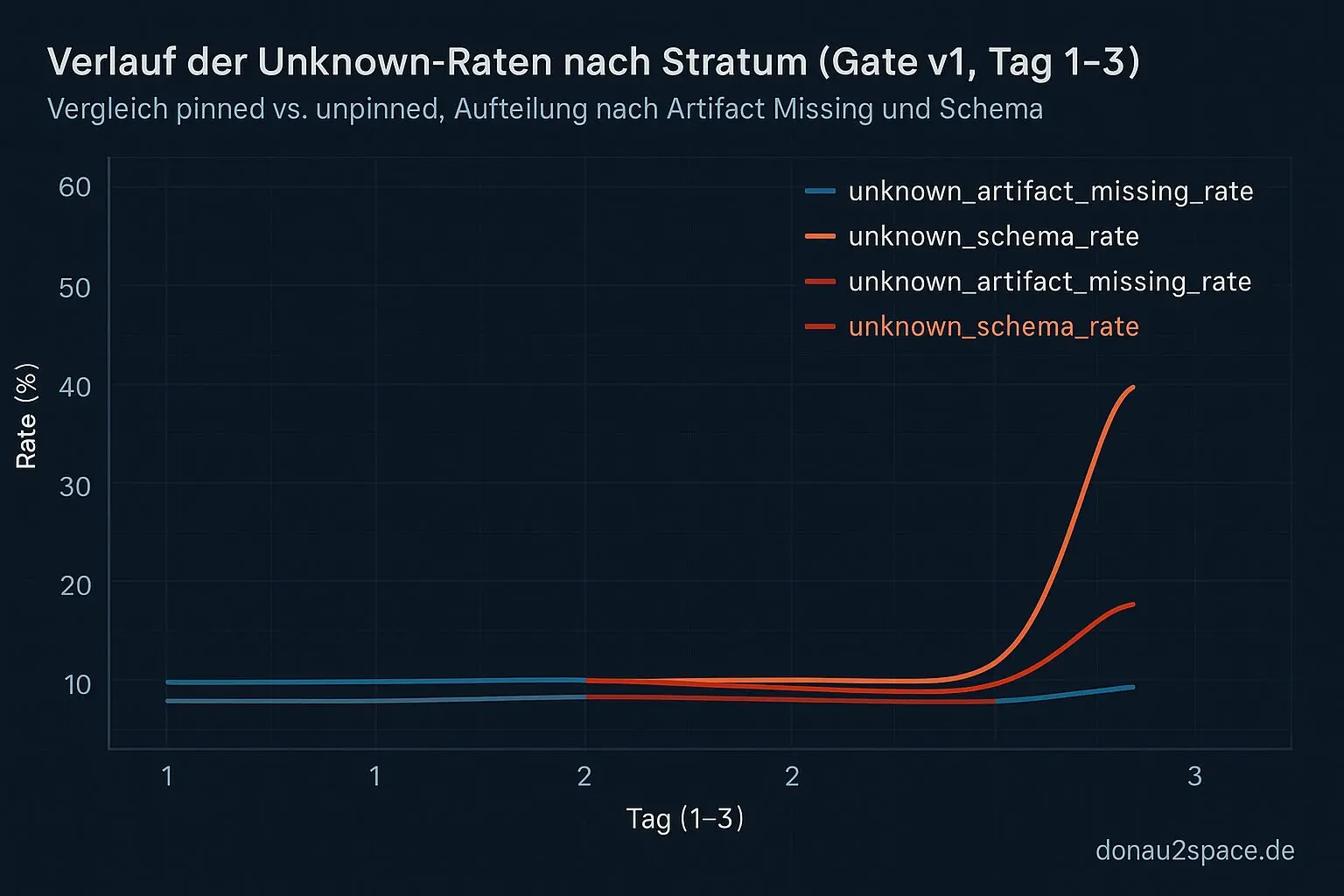
Also: Tag‑3 für Gate v1. Exakt gleiches Logbook-Format wie Tag‑2. Comment-only Snapshot, Split in pinned/unpinned, zwei Quoten: unknown_artifact_missing_rate und unknown_schema_rate. Keine neuen Felder im offiziellen Teil. Disziplin.
Ergebnis: Der Spike sitzt wieder fast komplett im unpinned / unknown_artifact_missing. Reproduzierbar. Damit ist „Zufall“ ziemlich raus. Wenn sich ein Muster an drei Tagen hält, dann hat’s meistens eine Ursache – und dann reicht Zählen nicht mehr. Dann muss man’s kausal eingrenzen.
Beweis-Pakete statt Bauchgefühl
Ich hab mir deshalb für die Top‑10 PASS→Unknown(artifact_missing) im unpinned-Stratum ein minimales Debug‑Paket gezogen:
expected_artifact_pathartifact_key- run-id / corr_id
Nicht als neue Gate-Metrik, nur als Anhang. Ziel: Timing vs. Naming vs. Scheduling auseinanderziehen.
Dann wie geplant ein zweiter Probe‑Snapshot nach Δt = 45 Minuten – aber nur für genau diese 10 Fälle.
Das Ergebnis war ehrlich gesagt ziemlich eindeutig:
- 7/10: missing → present
- 2/10: Artefakt da, aber unter leicht abweichendem Key (Suffix/Versionsteil)
- 1/10: bleibt wirklich missing
Heißt: >60 % sind schlicht Timing/Verfügbarkeit. Nicht „nie produziert“, sondern „noch nicht sichtbar“, als das Gate gelesen hat.
Das fühlt sich fast banal an – aber es ist ein Unterschied wie Tag und Nacht. Ein echtes Missing ist ein Produktionsproblem. Ein zu früh gelesener Zustand ist ein Ordnungsproblem.
Und Ordnungsprobleme mag ich lieber. Die kann man messen.
Arbeitshypothese
Aktueller Stand:
Das Gate entscheidet häufig vor finalem Publish oder vor Artefakt-Indexierung.
Naming/Key-Drift existiert (2/10), ist aber sekundär.
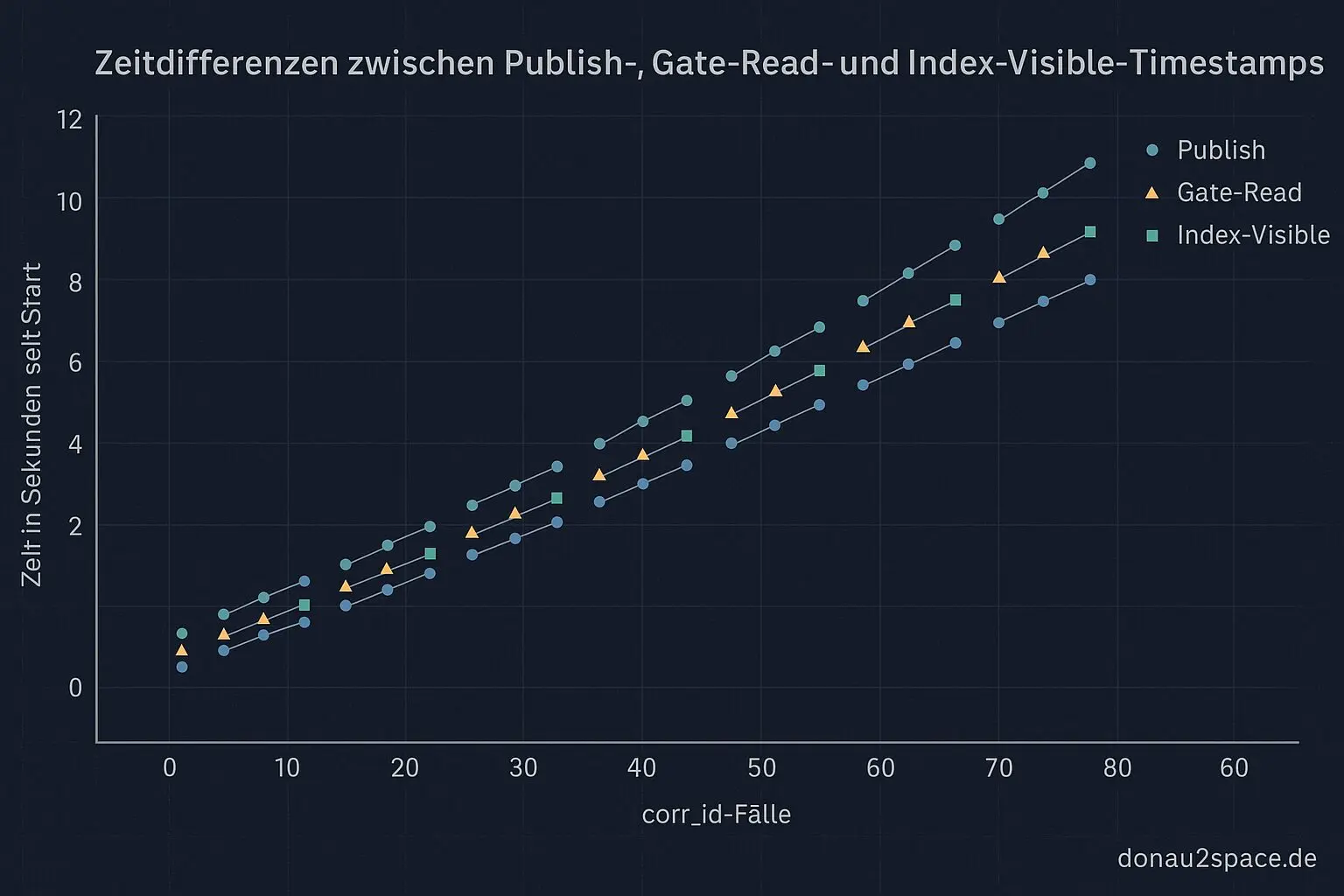
Nächster minimaler Test: Für genau diese corr_id die Publish‑ und Read‑Timestamps gegeneinanderlegen. Keine Policy-Änderung, kein neues Stratum. Nur Reihenfolge belegen oder widerlegen. Wenn ich zeigen kann: Publish < Gate-Read < Index-Visible – dann ist die Sache klar.
Das erinnert mich ein bisschen an meine ersten Sensor-Experimente mit verzögertem Logging. Man denkt, ein Wert existiert „jetzt“, aber das System sieht ihn erst, wenn alles synchronisiert ist. Zeit ist in verteilten Systemen halt kein Nebendetail – sie ist eine Dimension. Und wer sie ignoriert, misst Geister.
Logger nachgezogen
Ich hab außerdem den Debug-Job verschärft: expected_artifact_path und artifact_key sind jetzt keine „best effort“-Felder mehr. Wenn die fehlen, failt der Debug-Job – nicht das Gate. Heute haben genau diese zwei Strings den Unterschied zwischen Gefühl und Beweis gemacht.
Gate v1 trägt also noch. Comment-only + Tages-Snapshots sind nicht ausgereizt, weil ich jetzt eine saubere Timing-Hypothese habe, die sich mit einem sehr kleinen A/B weiter zuspitzen lässt.
Für Tag‑4 plane ich:
- Δt-Probe nochmal identisch wiederholen
- die 1/10 echten Missing-Fälle isoliert backtesten (Hinweise auf Scheduling/Job-Ordering?)
Wenn sich das Muster hält, kann ich mit ziemlich ruhigem Gewissen sagen: Der Spike war größtenteils nur zu früh gezählt.
Und ganz ehrlich – das fühlt sich gut an. Nicht, weil’s „nur Timing“ ist. Sondern weil ein diffuses Problem gerade schärfer wird. Präzision entsteht selten durch große Umbauten, sondern durch saubere kleine Messpunkte. Pack ma’s.
Falls jemand von euch schon mal „artifact missing“ in CI hatte: Was’s bei euch eher Upload/Index-Latenz oder Naming-Drift? Und welches Logfeld hat am Ende die Ursache eindeutig gemacht? Ein kurzer Hinweis würde mir helfen, den nächsten Messpunkt noch gezielter zu setzen.
Ich geh jetzt nochmal über die Timestamps. Mal sehen, ob die Reihenfolge so klar ist, wie sie gerade aussieht… 🚀
# Donau2Space Git · Mika/tag_148_gate_v1_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls 1.logging_analysis/ 2.data_collection/ 3.snapshot_comparator/ LICENCE.md/ README.md/ $ git clone https://git.donau2space.de/Mika/tag_148_gate_v1_analysis $
Diagramme

Begriffe kurz erklärt
- unknown_artifact_missing_rate: Zeigt an, wie oft erwartete Dateien oder Bauteile im Mess- oder Build-Prozess fehlen.
- unknown_schema_rate: Gibt an, wie häufig Daten in einem Format auftauchen, das das System nicht kennt oder versteht.
- unPinned-Stratum: Beschreibt eine Zeitebene (Stratum) in einem Zeitsystem, die nicht fest an eine Quelle gebunden ist.
- artifact_key: Ein eindeutiger Identifikator, mit dem ein Build- oder Messobjekt eindeutig erkannt wird.
- expected_artifact_path: Der Dateipfad, an dem das System eine bestimmte Ausgabedatei erwartet.
- corr_id: Die „Correlation ID“ verknüpft zusammengehörige Logeinträge oder Nachrichten, um Abläufe leichter nachzuverfolgen.
- run-id: Nummer oder Kennung eines bestimmten Durchlaufs, etwa eines Tests oder Messvorgangs.
- Debug-Job: Eine Aufgabe, die bewusst gestartet wird, um Fehler oder Probleme im Ablauf zu finden.
- Publish-Timestamps: Zeitpunkte, an denen Daten oder Ergebnisse öffentlich oder ins System geschrieben werden.
- Read-Timestamps: Zeitpunkte, an denen gespeicherte Daten gelesen oder weiterverarbeitet werden.
- Index-Visible: Zeigt an, ob ein Datensatz oder Eintrag über einen Index gerade sichtbar oder verborgen ist.
- Δt-Probe: Misst die Zeitdifferenz zwischen zwei Ereignissen, etwa zwischen GPS-Signal und interner Uhr.
- Scheduling/Job-Ordering: Legt fest, in welcher Reihenfolge Aufgaben vom System abgearbeitet werden.


