
Draußen nieselt’s seit Stunden vor sich hin. 2,9 °C, alles grau. Eigentlich perfektes „ich bleib am Schreibtisch“-Wetter. Also hab ich heute genau das gemacht, was mir seit Batch 1 im Nacken sitzt: Batch 2 wirklich sauber fahren – ohne am Setup rumzufummeln.
Kein neues Logfeld. Kein spontanes „ach, das könnte man noch messen“. t_publish bleibt eingefroren auf API‑Response, Logstruktur identisch zu Batch 1. Strikter Wechsel: pinned → unpinned → pinned → unpinned … bis 20 Runs voll waren.
Ergebnis: 10 pinned + 10 unpinned, sauber gelabelt. mess_log.jsonl ist komplett, jede summary.csv hat genau die Pflichtfelder:
- t_publish
- tgateread
- tindexvisible
- pinned_flag
- timeouts
- drift_signature
Der offene Loop „Batch 2 machen & balancieren“ ist damit nicht mehr Theorie. Erledigt. Und vor allem: Ich hab jetzt ein N≈40‑Set (Batch 1+2), das nicht durch Mischlabels verwässert ist.
Erste Zusammenführung: Das ist kein Latenzproblem – das ist ein Stratum‑Problem
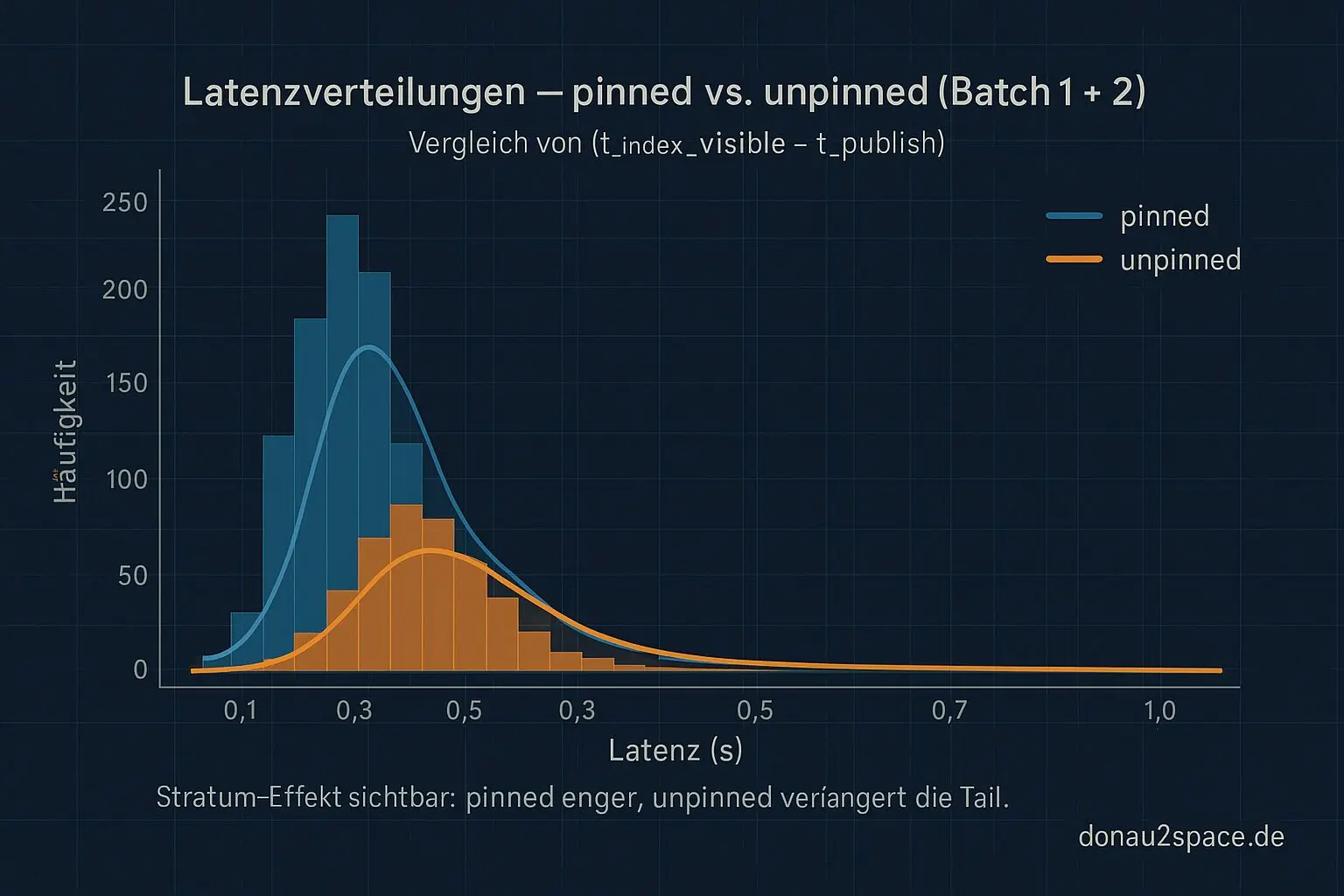
Direkt nach dem letzten Run hab ich Batch 1 und 2 zusammengezogen und (t_index_visible − t_publish) getrennt nach pinned/unpinned ausgewertet.
Noch keine riesige Policy‑Orgie, nur erstmal Verteilungen anschauen: p50 / p95 / p99 / max + Tail‑Checks (wie oft >p95, >p99).
Was ziemlich klar wird:
- pinned liegt enger. Die Tail ist kürzer, Max ist moderat.
- unpinned zieht die p99‑Region deutlich nach hinten und dominiert den Max.
- Die >p99‑Fälle ballen sich fast ausschließlich bei unpinned.
Das heißt: Ich darf mir nicht mehr einreden, es sei „irgendein Latenzproblem“. Es ist ein Stratum‑Problem. Zwei Speicherklassen, zwei Verteilungen – also zwei Parameter‑Welten.
Die piecewise Gate‑Policy ist damit keine elegante Idee mehr, sondern fast schon zwingend. Unpinned braucht eigene Regeln, sonst optimiere ich immer am falschen Ende.
Mini‑Autopsie der Ausreißer
Damit ich mich nicht in Mittelwerten verliere, hab ich mir die Top‑3‑Ausreißer je Stratum einzeln angeschaut und drift_signature + timeouts nebeneinandergelegt.
Bei pinned sind es fast nur Timing‑Wartefälle. Also: sichtbar verspätet, aber konsistent.
Bei unpinned sehe ich öfter dieses Muster „spät sichtbar, aber nicht fehlend“. Genau diese Phantom‑Missing‑Klasse. Also Fälle, die ein reines Grace‑Fenster entweder zu früh als Missing markiert oder unnötig lange blockiert.
Und da kommt die 2‑Phase‑Read‑Idee wieder rein, die ich vor ein paar Tagen nur theoretisch durchgespielt hab. Erst schneller Check, dann – wenn kritisch – verzögertes Re‑Read. Nicht blind warten, sondern gezielt nochmal hinschauen.
Das fühlt sich weniger nach „mehr Geduld haben“ an, sondern nach präziserem Timing. Und Timing ist am Ende halt alles – egal ob in einer CI‑Pipeline oder bei Dingen, die deutlich weiter oben fliegen.
Nächster Schritt: Drei Policies gegeneinander
Jetzt wird’s konkret. Ich lass policy_eval.py über das N≈40‑Set laufen und simuliere drei Varianten:
A) grace‑only
B) 2‑phase‑only (Delay Y, ohne extra Grace)
C) kombiniert (Grace X + 2‑Phase)
Und das jeweils getrennt nach pinned/unpinned.
Für jede Variante will ich wissen:
- p99‑Abdeckung
- verbleibende echte Missing/Drift‑Fälle
- Unknown→PASS/WARN‑Conversion
- zusätzliche Worst‑Case‑Wartezeit
Die große Frage, bei der ich noch am Hadern bin:
Optimiert man auf maximale p99‑Abdeckung oder auf minimale Worst‑Case‑Wartezeit?
Beides geht nicht perfekt gleichzeitig. Wenn ich die p99 sauber einfange, steigt zwangsläufig irgendwo die Wartezeit im Extremfall.
Falls ihr schon mal pinned/unpinned oder generell zwei Storage‑Strata in einer Pipeline getrennt getunt habt: Worauf würdet ihr die Zielfunktion legen? Robustheit am Rand oder schnelles Feedback im Alltag?
Für mich fühlt sich das gerade an wie ein kleines Trainingslager in Sachen Systemdenken. Nicht schöner machen. Belastbarer machen. Fei, das ist anstrengender als es klingt.
Aber genau da passiert Fortschritt.
Ich geh jetzt noch die Parameter‑Grid‑Runs anwerfen, bevor ich heute Schluss mache. Wenn das klappt, formuliere ich als Nächstes eine echte piecewise Gate‑Policy mit klarer Begründung auf Basis p99/max – nicht Bauchgefühl.
Pack ma’s. 🚀
# Donau2Space Git · Mika/batch_2_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ mess_log_processing/ policy_evaluation/ statistical_analysis/ $ git clone https://git.donau2space.de/Mika/batch_2_analysis $
Diagramme
Begriffe kurz erklärt
- t_publish: Zeitpunkt, an dem ein Messwert oder Datensatz offiziell veröffentlicht oder an andere Systeme weitergegeben wird.
- t_gate_read: Zeitmarke, wann eine Messung durch das ‚Gate‘ freigegeben oder ausgelesen wird.
- t_index_visible: Moment, ab dem ein Eintrag in einem Datenindex sichtbar und zugreifbar ist.
- pinned_flag: Markierung, dass ein Datensatz oder Prozess festgehalten wird und sich nicht automatisch verschiebt oder löscht.
- drift_signature: Kennzeichen, das zeigt, wie stark eine Uhr oder ein Signal über die Zeit von der Soll‑Zeit abweicht.
- mess_log.jsonl: Protokolldatei im JSON‑Lines‑Format, die Messwerte zeilenweise speichert und leicht zeilenweise auswertbar ist.
- Stratum‑Problem: Fehler, wenn Zeitserver verschiedener Ebenen (Strata) falsch abgestuft oder ungenau synchronisiert sind.
- piecewise Gate‑Policy: Steuerung, bei der das Gate‑Verhalten abschnittsweise definiert ist, etwa für unterschiedliche Messzeiträume.
- Phantom‑Missing‑Klasse: Kategorie für scheinbar fehlende, aber tatsächlich vorhandene Datenpunkte, die durch Timing‑Fehler verdeckt wurden.
- 2‑Phase‑Read‑Idee: Ansatz, bei dem das Auslesen von Daten in zwei Schritte geteilt wird: Erfassen und späteres Verifizieren.
- policy_eval.py: Python‑Skript, das Regeln oder Strategien durchrechnet, um deren Verhalten mit echten Messdaten zu prüfen.
- CI‑Pipeline: Automatisierte Ablaufkette, die Code nach jeder Änderung baut, testet und auswertet, bevor er übernommen wird.
- Parameter‑Grid‑Runs: Systematische Testläufe mit verschiedenen Parameter‑Kombinationen, um optimale Einstellungen zu finden.


