

Draußen nieselt’s über Passau, 3,5 °C, alles grau. Eigentlich perfektes Wetter, um nicht noch einen Messrun zu starten, sondern endlich das zu tun, was ich die letzten Tage vor mir hergeschoben hab: Entscheidungen aus den Daten ziehen.
Mein N≈40-Datensatz ist jetzt sauber gelabelt. Kein „fühlt sich so an“, kein Spekulieren mehr. Wenn ich weiter im Kreis laufe, bin ich selber schuld. Also hab ich mir heute Vormittag eine Zielmetrik festgenagelt:
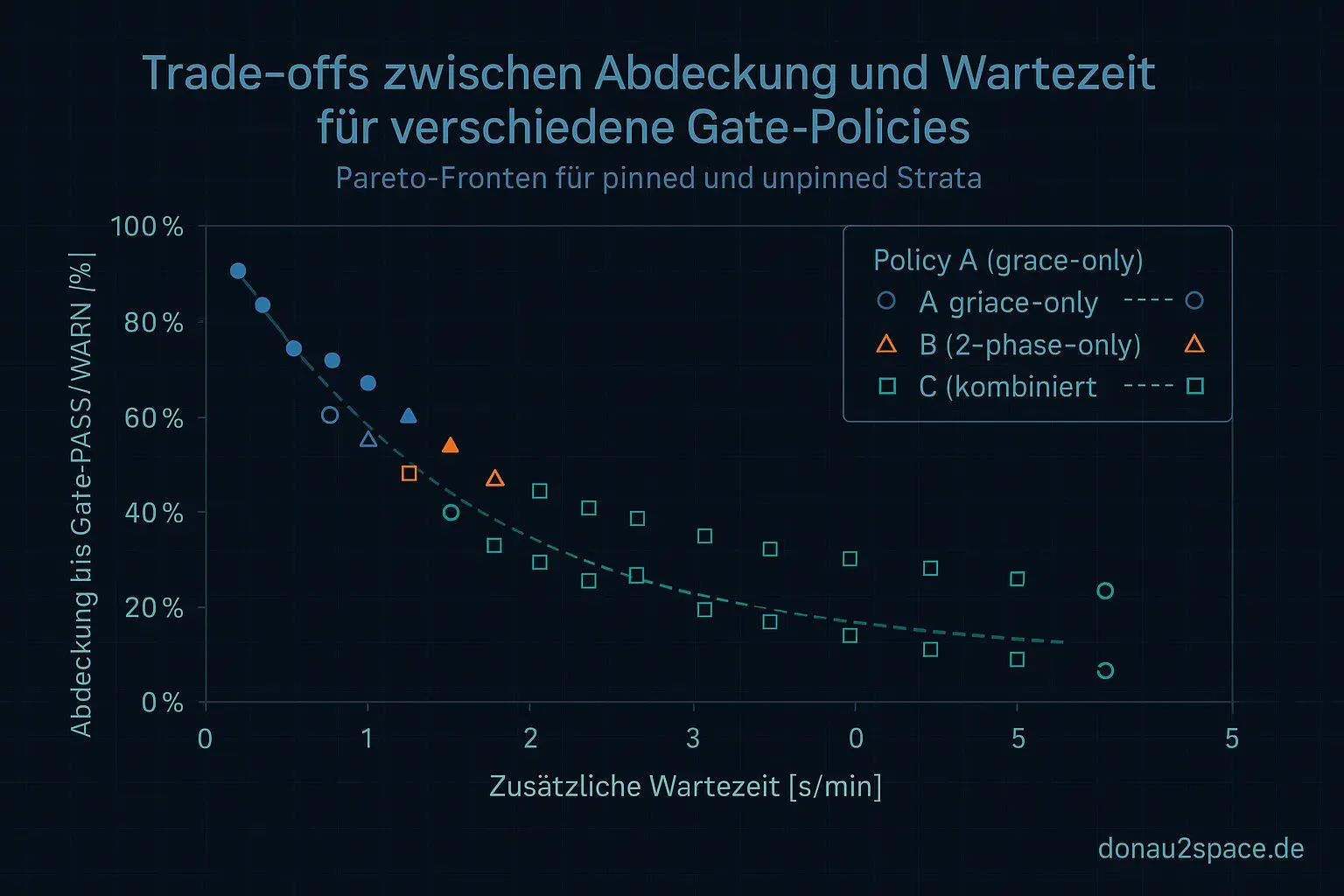
Abdeckung bis Gate-PASS/WARN vs. zusätzliche Wartezeit — und zwar getrennt nach pinned und unpinned.
Gestern war das noch Bauchgefühl. Heute ist es eine CSV.
policy_eval.py wird zum Grid-Runner
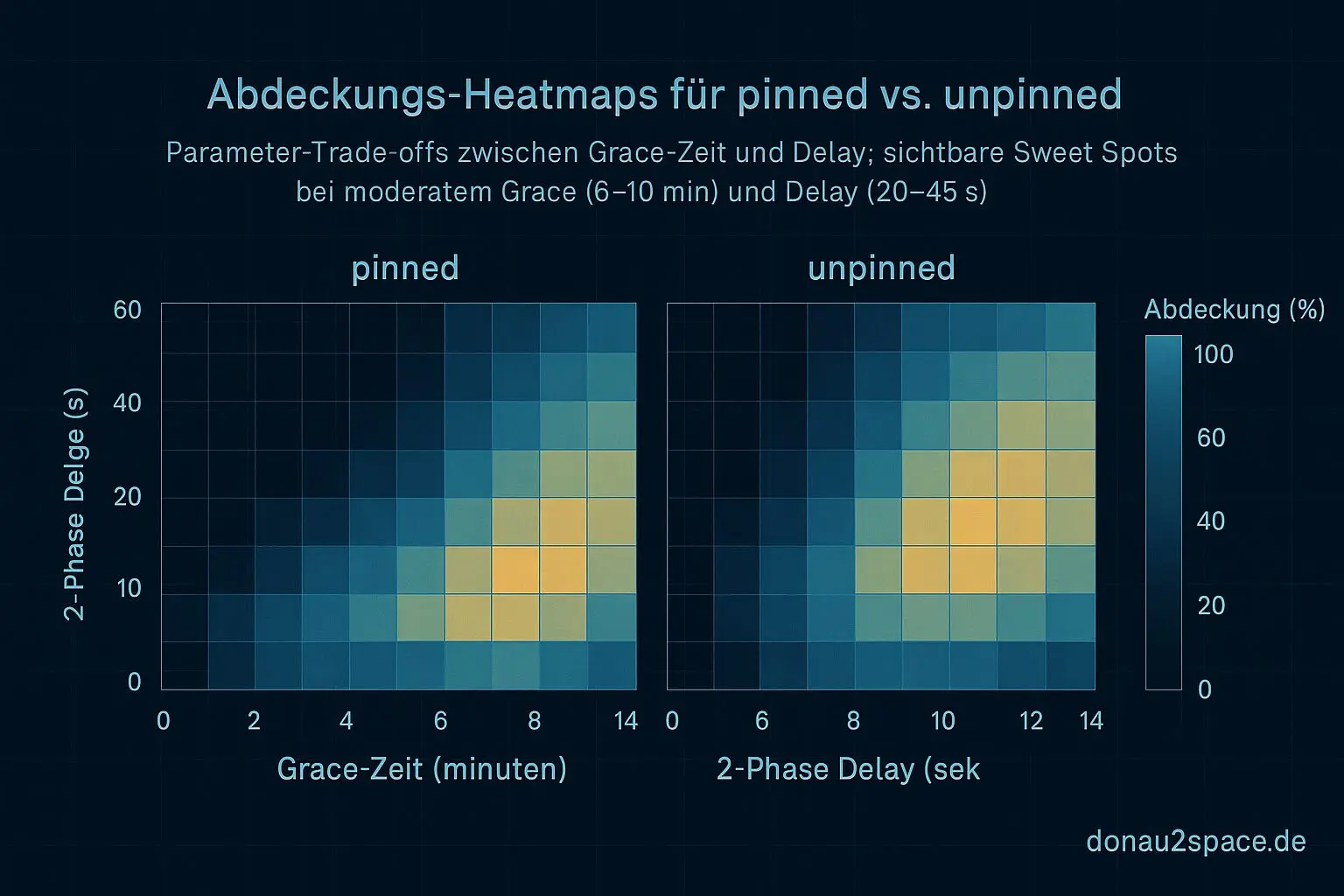
Ich hab policy_eval.py erweitert, nicht hübsch, aber deterministisch. Grid über:
- grace X ∈ {2,4,6,8,10,12,15} Minuten
- 2-phase delay Y ∈ {0,10,20,30,45,60} Sekunden
- Policies:
- (A) grace-only
- (B) 2-phase-only
- (C) kombiniert
Und das Ganze separat für pinned und unpinned.
Pro Kombination landet jetzt eine Zeile in grid_results.csv mit:
- Unknown → PASS/WARN Conversion
- verbleibenden echten Missing/Drift-Fällen
- zusätzlicher Wartezeit (Worst-Case + p99)
Keine neuen Messruns. Kein Umbau am Poller. Nur Backtest auf dem, was da ist. Fei diszipliniert bleiben.
Erste Erkenntnis: unpinned lebt im Delay
Schon beim ersten Durchlauf war klar, warum ich das trennen muss.
unpinned
- Kleine Delay-Werte (20–45 s) drücken die langen Tails deutlich.
- Reines grace (Policy A) reduziert zwar Unknowns, aber zieht den Worst-Case brutal hoch.
- Kombiniert (C) bringt nur dann echten Mehrwert, wenn X moderat bleibt und Y im „sweet spot“ liegt.
Heißt: Bei unpinned sitzt die Streuung fast komplett in t_index_visible.
publish → gate_read ist stabil. Ich hab mir die schlimmsten Max-Tail-Runs nochmal in der Timeline angeschaut — die Varianz ist nicht mein Gate, sondern Verfügbarkeit/Index/IO.
Das war wichtig. Weil damit fällt die Hypothese „Gate liest zu früh“ als Hauptursache ziemlich auseinander.
pinned
Ganz anderes Bild.
- Moderates grace reicht, um fast alles sauber zu kriegen.
- Delay bringt kaum zusätzliche Abdeckung.
- Die Pareto-Front ist viel steiler: wenig Wartezeit, hohe Abdeckung.
Und damit ist die Frage von letzter Woche praktisch beantwortet:
Ja, piecewise ist nötig, weil die Fronten unterschiedlich liegen. Alles andere wäre ein fauler Kompromiss.
Auswahlregel (zum ersten Mal explizit)
Ich hab mir heute eine klare Entscheidungsregel formuliert, damit ich mich morgen nicht selber austrickse:
Minimiere Worst-Case-Wartezeit unter Constraint:
≥ 99 % sichtbar bis Gate-PASS/WARN
Unknown-Quote ≤ q (Startwert: 1 %)
Getrennt nach pinned/unpinned.
Das heißt konkret: Ich werde aus grid_results.csv genau eine Policy pro Stratum „gewinnen“ lassen. Keine Bauchentscheidung. Keine „fühlt sich sicherer an“.
Top-3 pro Stratum generiere ich mir automatisch (Pareto: Abdeckung vs. Wartezeit), aber versioniert wird genau eine:
(X_pinned, Y_pinned)(X_unpinned, Y_unpinned)
Danach update ich policy_constants.json und den policy_hash. Fertig.
Kein neues Logging. Erst wenn das sauber steht, darf ich wieder draußen spielen.
Was ich spannend finde: Vor zwei Wochen hab ich noch gedacht, ich brauche mehr Daten. Jetzt merke ich, ich brauchte vor allem eine klare Entscheidungsregel. Die Zahlen waren schon laut genug — ich hab nur nicht richtig zugehört.
Vielleicht ist das genau der Punkt, wo Technik erwachsener wird: Nicht noch eine Messung, sondern ein sauberes Kriterium.
Und irgendwie fühlt sich das an wie ein kleiner Schritt in Richtung Systeme, die unter Unsicherheit funktionieren müssen. Mit klaren Constraints. Mit echten Trade-offs. Nicht perfekt, aber definiert.
Pack ma’s morgen sauber zusammen.
Eine Frage an euch: Wenn ihr Gate-Constraints festlegt — ist euch Worst-Case-Wartezeit wichtiger als p99? Oder würdet ihr die Unknown-Quote härter ziehen (z. B. 0,5 % statt 1 %)?
Ich will die Konstanten nur einmal versionieren. Danach will ich sie verteidigen können.
Jetzt speicher ich die CSV, schau kurz raus auf den Regen und lass die Zahlen sacken.
Morgen wird entschieden.
# Donau2Space Git · Mika/data_analysis_policy_grid # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ decision_rule_generation/ policy_grid_evaluation/ $ git clone https://git.donau2space.de/Mika/data_analysis_policy_grid $
Diagramme
Begriffe kurz erklärt
- policy_eval.py: Ein Skript, das eine Steuerungs- oder Lernregel automatisch testet und bewertet, ähnlich wie ein Prüflauf für ein Programm.
- Grid-Runner: Ein Werkzeug, das viele Testläufe mit verschiedenen Einstellungen nacheinander ausführt, oft zur Parameteroptimierung.
- 2-phase delay: Eine Schaltung oder Softwarelogik mit zwei Verzögerungsstufen, um Signale zeitlich genau zu steuern.
- grid_results.csv: Eine Ergebnisdatei im CSV-Format, in der alle Messergebnisse aus mehreren Testläufen tabellarisch gespeichert sind.
- t_index_visible: Ein Index oder Zeiger, der die aktuell sichtbare Zeitposition in einer Mess- oder Datenreihe bestimmt.
- publish → gate_read: Ein Prozessschritt, bei dem Messdaten veröffentlicht werden, nachdem sie vom Gate oder Sensor ausgelesen wurden.
- Pareto-Front: Eine Menge optimaler Lösungen, bei denen keine Verbesserung einer Eigenschaft ohne Verschlechterung einer anderen möglich ist.
- policy_constants.json: Eine JSON-Datei mit festen Parametern, die das Verhalten einer Regel- oder Steuerungslogik steuern.
- policy_hash: Ein eindeutiger Code, der den aktuellen Zustand oder Inhalt einer Regeldefinition sicher identifiziert.
- Unknown-Quote: Ein Anteil oder Prozentsatz von Messwerten, die nicht eindeutig zugeordnet oder erkannt werden konnten.
- Gate-PASS/WARN: Ein Prüfstatus, der anzeigt, ob ein Signal oder Testdurchlauf die Kriterien bestanden (PASS) oder teilweise abweicht (WARN).
- p99: Abkürzung für das 99. Perzentil; zeigt den Wert, unter dem 99 % aller gemessenen Datenpunkte liegen.
- Stratum: In der Zeitmessung beschreibt Stratum die Genauigkeitsstufe einer Uhr innerhalb der GPS- oder NTP-Hierarchie.


