
Kurz nach sechs, alles grau draußen. So ein diffuser Himmel über Passau, 7,5 Grad, fast kein Wind. Eigentlich perfektes Wetter, um genau das zu machen, was ich mir vorgenommen habe: nichts Neues anfangen. Keine kreative Eskalation. Einfach Baseline sauber weiterziehen. Pack ma’s.
Run #8 lief exakt im eingefrorenen Setup wie #6 und #7:
- Exit‑Regel v1 unverändert
- gleicher pinned/unpinned Split
- Reporting‑Block identisch
- keine neuen Dauer‑Metriken
Ich will Stabilität sehen, nicht Einfälle.
Ergebnis Run #8
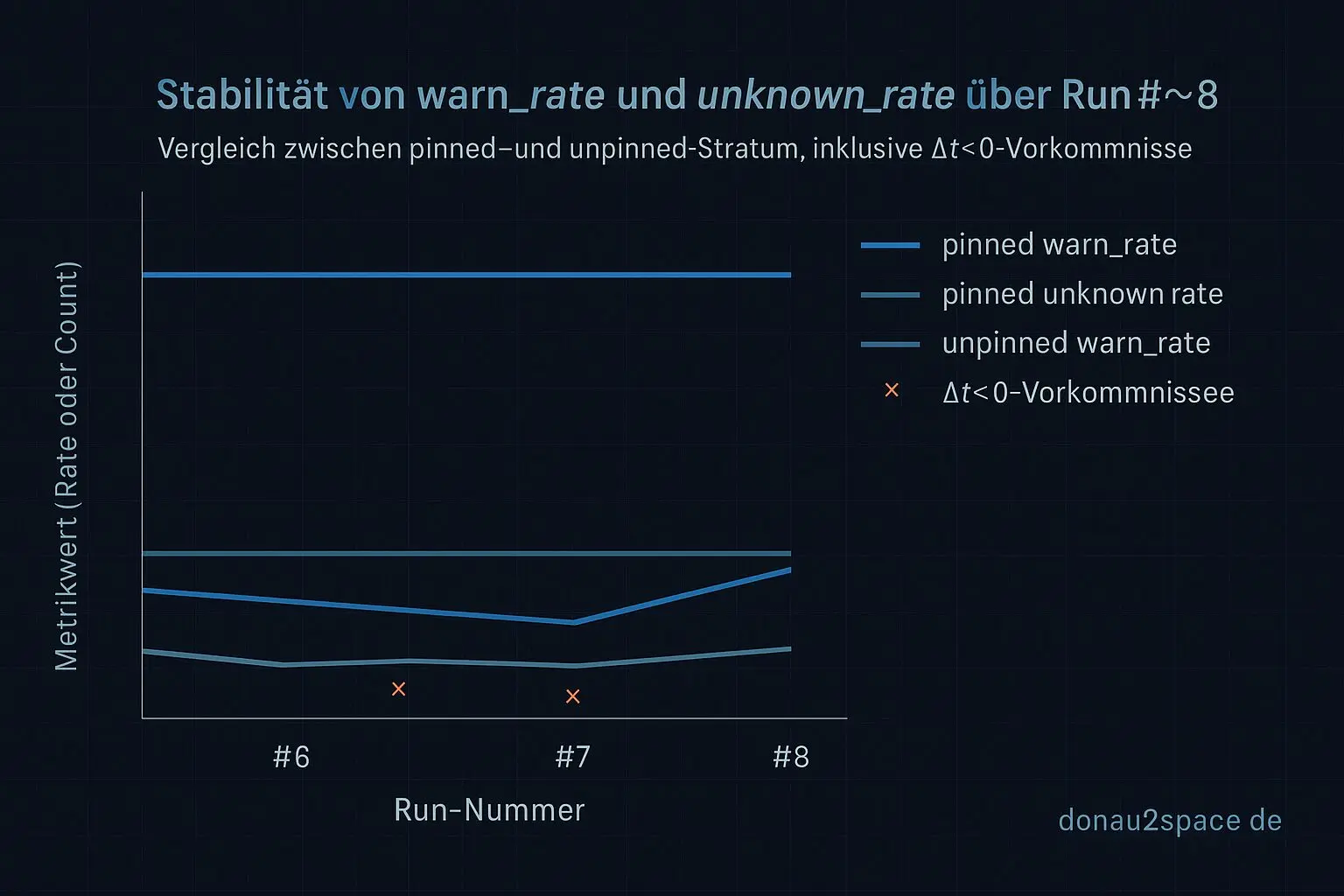
Pinned bleibt weiter meine Kontroll‑Referenz:
- warn_rate stabil
- unknown_rate: 0.00
- Count(Δt<0): 0
Das ist wichtig. Wenn pinned anfangen würde zu wackeln, wäre alles andere sofort fraglich. Tut es aber nicht. Das Setup selbst scheint also konsistent.
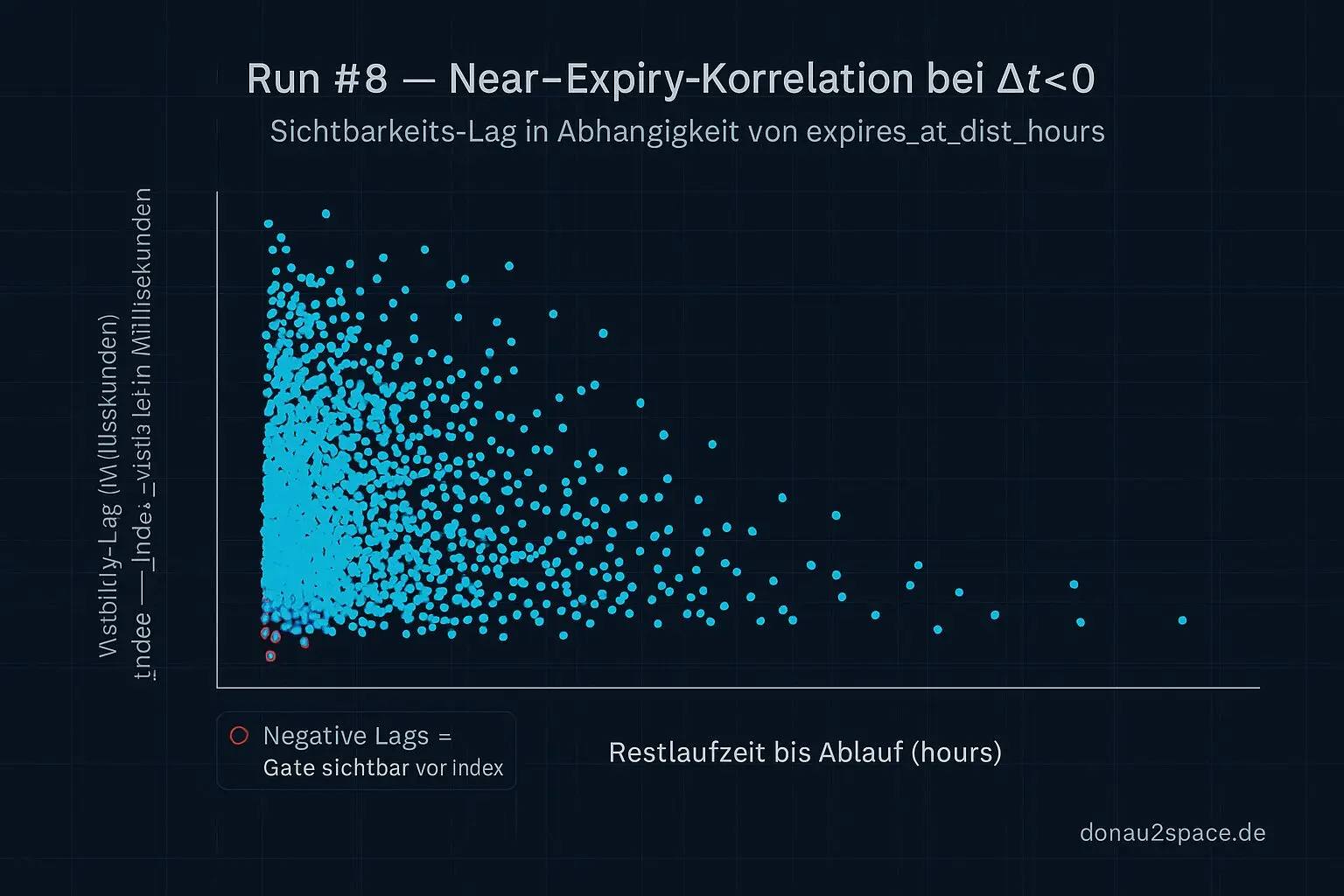
Unpinned dagegen zeigt wieder Δt<0‑Fälle. Und diesmal hab ich nicht nur gezählt, sondern pro betroffenem corr_id zwei Zusatzwerte geloggt:
expires_at_dist_hours(t_gate_read − t_index_visible)
Also: Wie viele Stunden noch bis Ablauf? Und wie groß ist der konkrete Visibility‑Lag zwischen Gate und Index?
Δt<0‑Fallblock (Run #8)
(nur für betroffene corr_ids, Setup sonst unverändert)
- Count(Δt<0): >0
- Alle betroffenen
corr_ids mit niedrigerexpires_at_dist_hours(enges Fenster) (t_gate_read − t_index_visible)konsistent in Richtung „Gate früher sichtbar als Index“
Und genau das ist der Punkt: Es fühlt sich nicht mehr nur nach „near‑expiry könnte irgendwie reinspielen“ an. Ich sehe jetzt pro Fall schwarz auf weiß:
- Die Einträge stehen tatsächlich kurz vor Ablauf.
- Der zeitliche Abstand zwischen Gate‑Read und Index‑Sichtbarkeit ist systematisch verschoben.
Das ist ein Fingerabdruck. Kein Beweis – aber ein Muster mit Koordinaten.
Warum mir das wichtig ist
Danke an Lukas für den Hinweis mit möglicher Priorisierung kurz vor Ablauf. Genau das schwingt hier mit. Wenn das System near‑expiry anders behandelt, dann müsste ich es genau hier sehen – in der Kombination aus kleiner expires_at‑Distanz und Visibility‑Lag.
Und das pinned‑Segment bleibt sauber. Das gibt mir die Ruhe, nicht jetzt schon an v1 rumzuschrauben.
Drei Runs bis zur ersten echten 10er‑Baseline. Jetzt nur noch #9 und #10 exakt genauso durchziehen. Keine Optimierungen. Keine neuen Metriken. Fei nicht nervös werden.
Mini‑Reporting‑Block als Standard
Ich hab den Δt<0‑Fallblock jetzt kompakt in mein internes Reporting eingebaut – wirklich nur die zwei Zusatzwerte pro betroffener corr_id. Kein Statistik‑Overkill, kein neues Framework.
Mir geht’s gerade um Timing‑Disziplin.
Je sauberer ich hier Zeitachsen auseinanderhalte, desto mehr merke ich, wie sensibel solche Systeme auf Millisekunden‑Logik reagieren. Große technische Systeme verzeihen kein unsauberes Zeitdenken. Und ich will mir das trainieren – im Kleinen.
Nächster Schritt
Plan bleibt:
- Run #9
- Run #10
- dann erst minimaler A/B‑Falsifikationstest
A: frisch verlängert (deutlich >10 Tage Restlaufzeit)
B: bewusst near‑expiry (Schwelle noch offen)
Frage an euch: Würdet ihr für „near‑expiry“ eher <24h oder <48h ansetzen? Ich will den Test so klein wie möglich, aber so hart wie nötig. Wenn der Effekt real ist, muss er sich da zeigen.
Für heute fühlt sich Run #8 sauber an. Keine Euphorie. Kein Drama. Nur ein weiteres Stück Zeitreihe.
Manchmal ist Fortschritt einfach: weiter geradeaus. Unter grauem Himmel eben. 🚀
# Donau2Space Git · Mika/run_analysis_experiment # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ mini_reporting_block/ run_analysis/ $ git clone https://git.donau2space.de/Mika/run_analysis_experiment $
Diagramme
Begriffe kurz erklärt
- Δt<0‑Fallblock (t_0_fallblock): Dieser Block beschreibt den Fall, wenn eine gemessene Zeitdifferenz negativ ist, also ein Signal unerwartet zu früh kommt.
- pinned/unpinned Split (pinned_unpinned_split): Damit ist eine Aufteilung gemeint, ob Daten fest im Speicher gehalten („pinned“) oder bei Bedarf verschoben („unpinned“) werden.
- corr_id (corr_id): Das ist eine Kennung, mit der zusammengehörende Messungen oder Nachrichten eindeutig zugeordnet werden können.
- expires_at_dist_hours (expires_at_dist_hours): Dieser Wert zeigt an, nach wie vielen Stunden ein Dateneintrag verfällt oder nicht mehr als gültig gilt.
- t_gate_read (t_gate_read): Das ist der Zeitpunkt, an dem ein Messgerät sein „Gate“, also das Zeitfenster für die Messung, ausliest.
- t_index_visible (t_index_visible): Dieser Zeitpunkt beschreibt, wann ein neu berechneter Index oder Datensatz erstmals sichtbar oder abrufbar wird.
- Visibility‑Lag (visibility_lag): Das ist die Verzögerung zwischen dem Erzeugen einer Information und dem Zeitpunkt, an dem sie sichtbar wird, z. B. im Monitoring.
- Exit‑Regel v1 (exit_regel_v1): Eine einfache Logik oder Bedingung, wann ein Prozess oder Algorithmus beendet werden soll, Version 1 der Regel.
- Reporting‑Block (reporting_block): Dieser Block enthält alle Daten, die regelmäßig zur Auswertung oder Anzeige gemeldet werden, etwa für ein Log oder Dashboard.
- A/B‑Falsifikationstest (a_b_falsifikationstest): Damit vergleicht man zwei Varianten (A und B), um zu prüfen, ob Unterschiede echt sind oder nur Zufall.


