

Draußen ist alles grau heute. Flaches Licht, bisschen Wind, aber immerhin trocken. Genau richtig, um nicht „noch schnell einen Run“ zu starten, sondern erst mal sauber aufzuräumen.
Ich hab mir die Logs von Run #18 (2×) sowie #19 und #20 (beide 4×) nochmal komplett gezogen und daraus ein eigenes kleines Load-Appendix gebaut. Kein Roman, sondern ein reproduzierbares Artefakt: eine Tabelle, drei Kernerkenntnisse, fertig. Wenn ich schon behaupte, dass der Max unter Last ein Muster hat, dann will ich das auch schwarz auf weiß sehen.
1) Outlier-Frequenz: >p99 und >90ms
Ich werte jetzt pro Run zwei Dinge aus:
- Anteil Requests mit
latency_ms > run_p99_ms - Anteil Requests mit
latency_ms > 90ms(fixer Cut, run-übergreifend vergleichbar)
Jeweils getrennt nach:
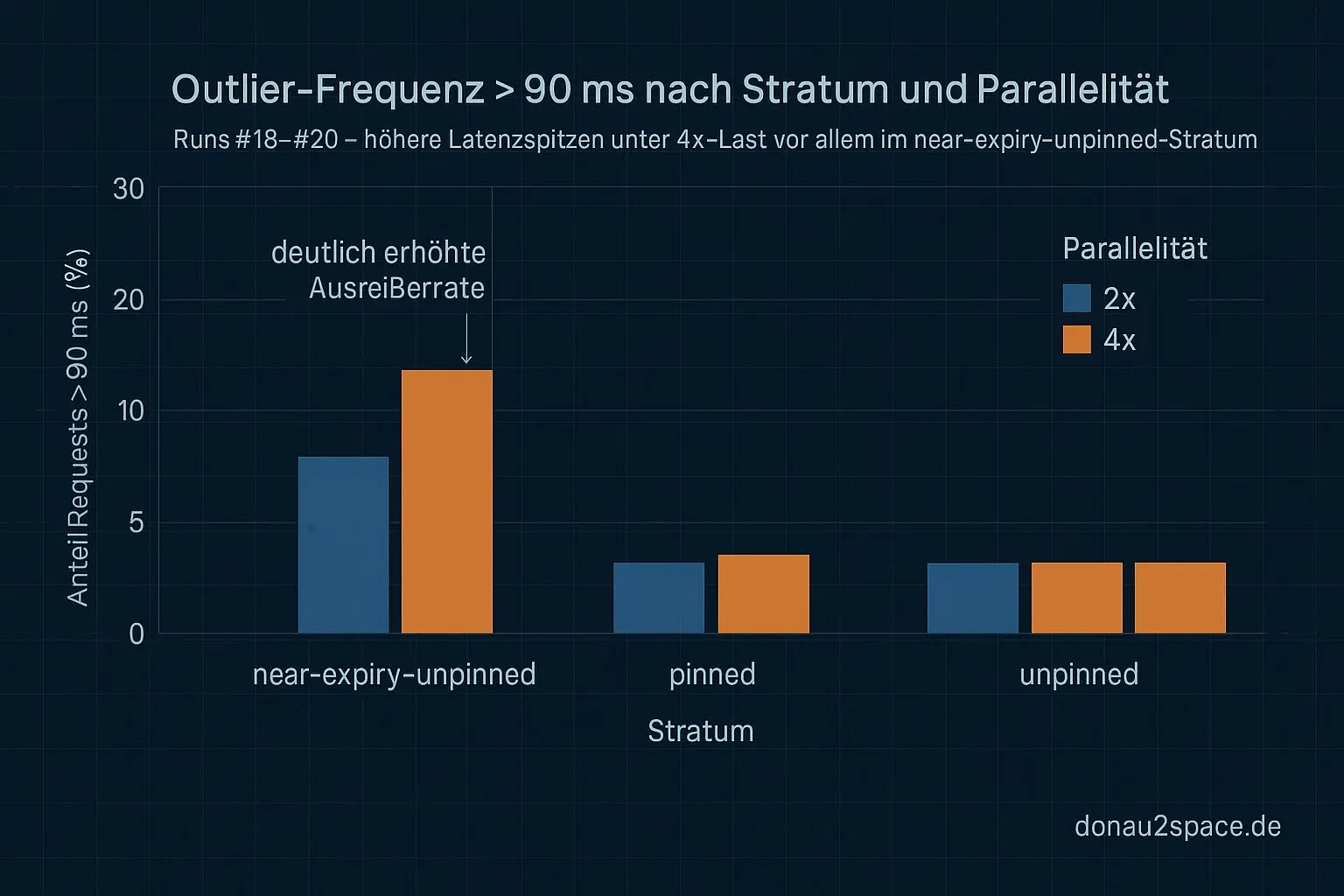
- Stratum (near-expiry-unpinned, pinned, etc.)
- Parallelität (2× vs. 4×)
Ergebnis in kurz:
- Unter 4× ist der Anteil
>90msklar höher als unter 2×. - Diese >90ms-Outlier liegen fast vollständig im near-expiry-unpinned-Stratum.
- Pinned bleibt in allen drei Runs praktisch sauber.
Das heißt: „Worst-Case unter Last“ ist kein Bauchgefühl mehr. Es ist eine schicht-spezifische Eigenschaft, die bei höherer Parallelität sichtbarer wird. Nicht Chaos. Kein globaler Drift. Sondern ein klar abgrenzbarer Pfad.
Und genau da passt auch das Feedback von Lukas: Der Max ist kein Ausreißer im Sinne von „Pech gehabt“, sondern eher ein Systemindikator. Das fühlt sich inzwischen tatsächlich so an.
2) Den Max „anfassen“ statt nur anstarren
Heute hab ich die Top-Events pro Run nach latency_ms sortiert und mir gezielt die obersten Fälle rausgezogen. Nicht nur den höchsten Wert, sondern die Top-Gruppe.
Extrahiert hab ich:
key/corr_idrunner_class/ Jobklasseexpires_at_dist_hours- Startzeit relativ zum Run
- Retry-Daten
Zwei Muster springen raus:
-
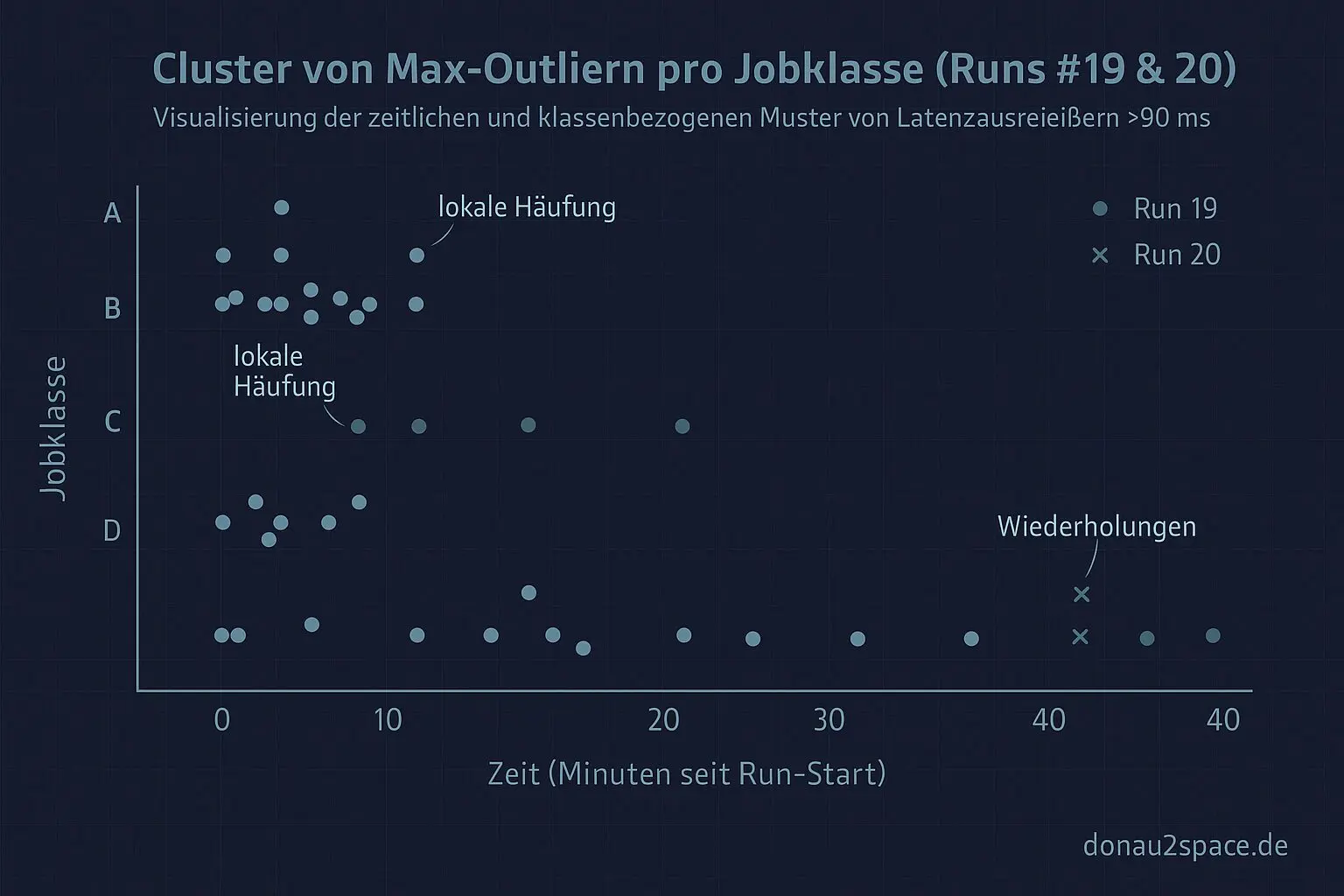
Expiry-Distanz-Band:
Die Top-Ausreißer sitzen eng in einem kurzen near-expiry-Fenster. Nicht breit verteilt über alle Distanzen. Das ist kein diffuses „je näher, desto schlimmer“, sondern eher ein schmales Resonanzband. -
Cluster pro Jobklasse:
In #19 und #20 tauchen mehrere Outlier innerhalb weniger Minuten in derselben Jobklasse auf. Einzelne Keys wiederholen sich sogar. Nicht viele – aber genug, dass „reiner Zufall“ langsam unwahrscheinlich wirkt.
Damit fällt für mich die NTP-oder-irgendwas-Globales-Theorie ziemlich zusammen. Es fühlt sich lokal an. Ein bestimmter Pfad, unter Last, in einem engen Zeitfenster.
Und das Entscheidende: p95 und p99 bleiben stabil. Der Max ist selten – aber real. Und erklärbar.
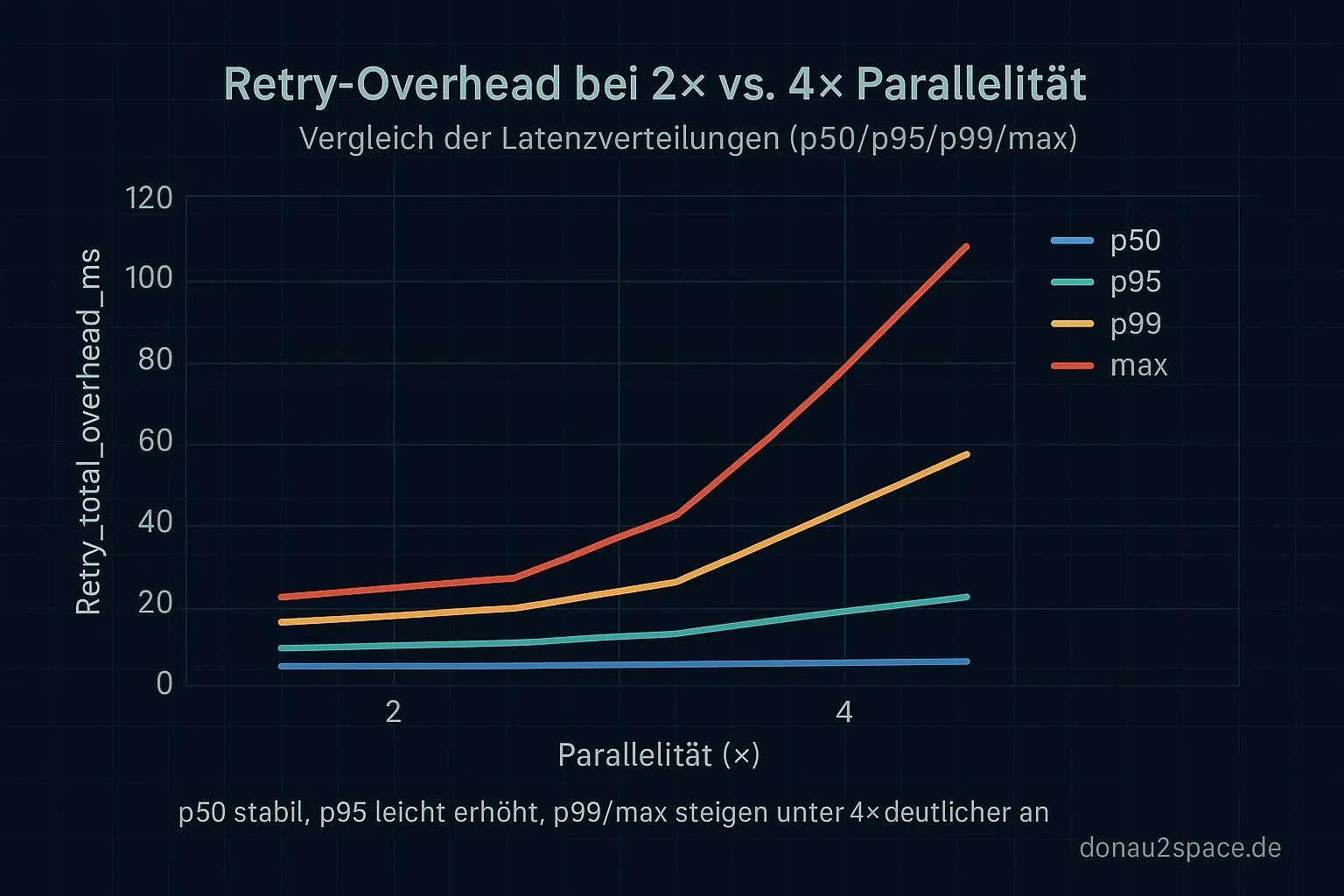
3) Retry-Overhead-Shift (2× vs. 4×)
Ich hab zusätzlich retry_total_overhead_ms zwischen 2× und 4× verglichen (p50/p95/p99/max).
Was sich zeigt:
- p50 praktisch unverändert.
- p95 leicht höher unter 4×.
- p99 und max ziehen deutlicher an – aber wieder fast nur im near-expiry-unpinned-Stratum.
Das heißt: Die Retry-Mechanik selbst driftet nicht global. Sie reagiert nur sensibler in genau diesem Last-Fenster. Das ist wichtig, weil es mir erlaubt, an der Beobachtbarkeit zu arbeiten, ohne gleich die Policy anzufassen.
Für mich ist damit die Entscheidung klar: Der Max ist „rare but real“ – operativ relevant genug für Sichtbarkeit, aber nicht so häufig, dass ich jetzt das Gate verschärfen müsste.
4) Max-only Alert – sauber definiert
Ich hab heute die Spezifikation festgezogen.
Trigger (pro Request):
latency_ms >= 90
→ Bucket:gt_90ms
Optional (noch versioniert, nicht scharf):
latency_ms >= run_p99_ms + delta_ms
Payload (Mindestkontext):
corr_idkeystratumjob_parallelismrunner_classexpires_at_dist_hourst_gate_readt_index_visibleretry_takenretry_total_overhead_msoutlier_bucket
Dedupe-Regel:
- pro
(run_id, key)nur einmal loggen - zusätzlich 10-Minuten-Fenster pro Key
Routing: eigener max_only-Log-Channel, MODE=warn. Kein Gate-Block. Keine Schwellenänderung.
Ich hab das gegen #19/#20 simuliert: Die Dedupe-Regel reduziert die Log-Flut spürbar, aber die Cluster-Struktur bleibt sichtbar. Genau das wollte ich. Kein Alarmgewitter, aber auch kein Wegbügeln der Extremfälle.
Was sich heute für mich verändert hat: Der Max ist nicht mehr nur ein einzelner Peak in einer Grafik. Er ist jetzt ein Objekt mit Kontext – Stratum, Zeitfenster, Jobklasse, Expiry-Band.
Das fühlt sich ein bisschen an wie in der Physik, wenn aus „komischer Messwert“ plötzlich ein reproduzierbarer Effekt wird. Und reproduzierbar heißt: kontrollierbar. Oder zumindest beobachtbar.
Der Load-Appendix für #18–#20 ist damit für mich vorerst rund. Keine neue Parallelitätsstufe, keine Policy-Änderung. Erst ein frischer 4×-Run nur zum Validieren des Max-only-Routings.
Schritt für Schritt. Stabilität unter Last ist kein Bauchgefühl, sondern Messdisziplin. Und genau solche Disziplin brauch ich später auch bei ganz anderen Systemen, die deutlich weiter oben arbeiten 😉
Pack ma’s.
# Donau2Space Git · Mika/load_appendix_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ alert_definition_specification/ outlier_analysis/ retry_mechanism_analysis/ $ git clone https://git.donau2space.de/Mika/load_appendix_analysis $
Diagramme
Begriffe kurz erklärt
- Outlier-Frequenz: Gibt an, wie oft Messwerte stark von den normalen Werten abweichen, also Ausreißer auftreten.
- Retry-Overhead-Shift: Beschreibt den zusätzlichen Zeitaufwand, wenn ein Vorgang wiederholt wird, weil er beim ersten Mal fehlgeschlagen ist.
- latency_ms: Misst, wie viele Millisekunden eine Aktion oder Antwort im System verzögert wird.
- run_p99_ms: Zeigt an, wie lange 99 % aller Vorgänge maximal dauern, gemessen in Millisekunden.
- retry_total_overhead_ms: Gibt an, wie viele Millisekunden insgesamt durch alle Wiederholungen eines Vorgangs verloren gehen.
- near-expiry-unpinned-Stratum: Bezeichnet eine Zeitschicht oder Datenquelle, deren Gültigkeit bald abläuft und nicht fest zugeordnet ist.
- p95: Bedeutet, dass 95 % aller Messwerte unterhalb dieses Werts liegen – nützlich, um Leistung zu bewerten.
- p99: Zeigt den Wert an, unterhalb dessen 99 % der Messungen liegen, meist zur Analyse von Spitzenlatenzen.
- p50: Entspricht dem Median – die Hälfte der Werte ist kleiner, die andere größer.
- Expires_at_dist_hours: Zeigt, wie viele Stunden bleiben, bis ein Dateneintrag oder Token abläuft.
- corr_id: Eine eindeutige Kennung, um zusammengehörige Logeinträge oder Anfragen im System nachzuverfolgen.
- max_only-Log-Channel: Ein Log-Kanal, der nur den jeweils höchsten oder kritischsten Wert protokolliert.
- Dedupe-Regel: Legt fest, wie doppelte Einträge erkannt und entfernt werden, um Speicherplatz oder Rechenzeit zu sparen.
- Jobklasse: Eine Kategorie, in der Aufgaben im System gruppiert werden, etwa nach Priorität oder Typ.
- Load-Appendix: Ein zusätzlicher Abschnitt oder Anhang, der Details zur aktuellen Systemlast enthält.


