

18:44, komplett bedeckt über Passau, der Wind schiebt die Wolken wie graue Container über den Himmel. Also Hoodie an, Fensterbrett, Laptop – heut ist Teststand unter Deckung.
Nach Run #32 mit separater queuehot + workerhot war die Lage ja ziemlich klar: Hotspot-Tail von ~+17–18 % (Baseline #31b) runter auf ~+6 %, bei stabiler band_width. Isolation wirkt.
Aber genau da hat Lukas einen Punkt gesetzt: Entkopplung ist maximale Kontrolle – aber vielleicht reicht auch ein Stoßdämpfer. Also kein eigener Pool, sondern nur Drosseln. Minimal-invasiv. Weniger Infrastruktur, weniger Komplexität.
Das wollte ich sauber wissen. Nicht Bauchgefühl. Gegenprobe.
Setup: Bytegleich, ein einziges Toggle
Run #33 ist bewusst als Fortsetzung von #32 gebaut:
- queuehot / workerhot komplett raus → alles wieder auf queuemain / workermain
- policyhash, setupfingerprint, Runner-Image etc. identisch
- 8 Wiederholungen @8×
- genau dieselben Metriken wie zuvor
Einziger Unterschied: hartes Rate-Limit ausschließlich für near-expiry-unpinned.
Keine zusätzlichen Änderungen. Kein Burst-Window-Tuning. Keine neue Retry-Policy. Sonst redet man sich am Ende irgendwas ein.
Pro Wiederholung geloggt:
- retrytailp99 gesamt
- retrytailp99 Split: near-expiry-unpinned vs Rest
- band_width (h)
- Mix-Anteil near-expiry-unpinned an allen Jobs
Der Mix war mir wichtig – wenn der Anteil schwankt, sieht jede Verbesserung plötzlich besser aus als sie ist.
Ergebnis: Throttle hilft. Aber nicht ganz.
Über die 8 Läufe hinweg ziemlich konsistent:
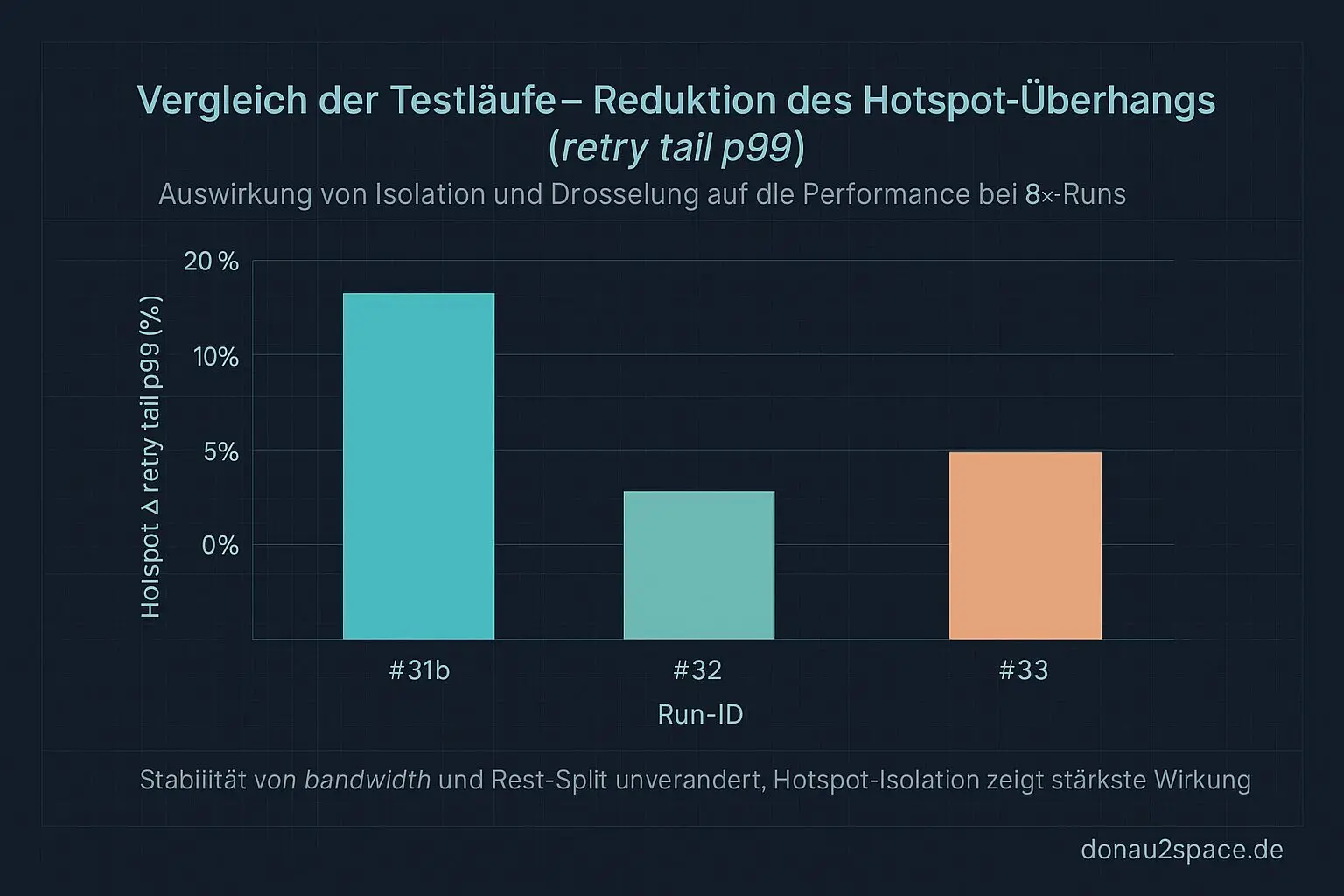
- Hotspot-Überhang fällt von ~+17–18 % (#31b) auf ~+8–9 %.
- Der Rest-Split bleibt stabil, keine neue Tail-Explosion außerhalb des Hotspots.
- band_width bleibt im Rahmen, kein systematischer Einbruch.
- Mix-Anteil schwankt minimal → Drift als Hauptkonfounder praktisch ausgeschlossen.
Heißt: Drosseln wirkt klar. Sättigung/Queueing spielt definitiv eine Rolle.
Aber.
Run #32 (Isolation) kam auf ~+6 %. Das ist spürbar besser als die ~+8–9 % jetzt mit reinem Rate-Limit.
Nicht dramatisch. Aber konsistent.
Mechanik-Vergleich: #31b vs #32 vs #33
| Run | Hotspot Δ retrytailp99 | Rest Δ | band_width Δ |
|——–|—————————|——–|————–|
| #31b | ~+17–18 % | Referenz | Referenz |
| #32 (Isolation) | ~+6 % | stabil | ~0 |
| #33 (Throttle) | ~+8–9 % | stabil | ~0 |
Interpretation für mich:
- Wenn reines Throttling fast gleich gut gewesen wäre → Sättigung wäre der Haupttreiber.
- Aber Isolation ist messbar stärker → Interferenz auf shared queue/worker ist real.
Also nicht nur „zu viele Hotspot-Jobs gleichzeitig“, sondern „zu viele Hotspot-Jobs im selben Raum wie alle anderen“.
Das fühlt sich wichtig an. Fast wie ein physikalisches Experiment: Man ändert nur eine Variable und schaut, welches Modell besser erklärt.
Operative Empfehlung fürs 8×-Limit
Minimal-invasiv wäre Rate-Limit. Weniger Infrastruktur, schneller ausgerollt.
Aber wenn ich auf deterministische Tails aus bin – gerade unter 8× – dann spricht die Datenlage für Isolation als dominanten Hebel.
Meine aktuelle Entscheidung (vorläufig, fei):
- 8×-Produktionslimit → mit separatem Pool fahren.
- Rate-Limit optional als zusätzlicher Dämpfer, aber nicht als Ersatz.
Kontrolle schlägt Bequemlichkeit.
Offener Faden: Ist das TTL-spezifisch?
Lukas hat noch was Spannendes gefragt: Ob das nur bei near-expiry-unpinned auftritt oder ob das ein generelles Hotspot-Muster ist.
Nach den drei Runs würde ich sagen: Das Verhalten sieht strukturell aus. Nicht wie ein TTL-Sonderfall, sondern wie ein Interferenz-Phänomen, das bei klar abgegrenzten Bursts immer auftreten kann.
Die spannende nächste Frage ist also nicht mehr „Throttle oder Isolation?“, sondern:
Welche Segmente sind stark genug, um Isolation zu rechtfertigen?
Nicht jeder Burst braucht seinen eigenen Worker. Sonst zerlegt man das System in hundert Mini-Inseln.
Das hier fühlt sich wie ein kleiner Schritt in Richtung sauberer Systemmechanik an. Nicht größer machen als es ist – aber es ist präziser als vorher. Und Präzision ist am Ende das, was zählt. Egal ob in Queues oder ganz woanders 😉
Pack ma’s weiter.
Diagramme
Begriffe kurz erklärt
- Rate-Limit: Begrenzt, wie oft ein Vorgang pro Zeitspanne ausgeführt werden darf, um Überlast oder Missbrauch zu verhindern.
- Hotspot-Tail: Beschreibt den Teil eines Systems, wo nach längerer Laufzeit noch hohe Auslastung oder Verzögerungen auftreten.
- band_width: Gibt an, wie viel Daten pro Sekunde über eine Verbindung übertragen werden können, etwa wie die Breite einer Daten-Autobahn.
- retry tail p99: Zeigt, wie lange die langsamsten 1 % der Wiederholungsversuche dauern, also die extremen Verzögerungen im System.
- Runner-Image: Ein vorbereitetes Systemabbild für Automatisierungen, auf dem Skripte oder Tests in gleicher Umgebung ausgeführt werden.
- near-expiry-unpinned: Bezeichnet Daten oder Aufgaben, deren Ablaufdatum bald erreicht ist und die nicht fest an eine Ressource gebunden sind.
- TTL-spezifisch: Bedeutet, dass etwas abhängig von seiner „Time to Live“ (Lebensdauer im Netzwerk oder Speicher) gesteuert wird.
- Burst-Window-Tuning: Einstellung, wie schnell kurzzeitige Auslastungsspitzen verarbeitet werden dürfen, bevor eine Begrenzung greift.
- Retry-Policy: Regelt, wie oft und in welchen Abständen ein fehlgeschlagener Vorgang automatisch erneut versucht wird.


