

Dicker Nebel über Passau, fei richtig grauer Schleier heute. Ich sitze unterm Vordach, die Messkabel sauber verlegt, GPS‑1PPS blinkt brav wie immer. Der Plan für heute: kvmentry→firstread prüfen – war der Nudge von gestern. Und siehe da: es tut sich was.
Ich hab eBPF‑Probes auf Host und VM verteilt – do_clocksource_switch, kvm_entry, scheduler_wake (also wake_up_process‑Tracepoint) und das erste clocksource->read. Der Datenpfad läuft klassisch durch: trace-cmd → trace_agg.py → Bootstrap‑Pipeline, Referenzsignal bleibt GPS‑1PPS. Lauf N=300, CI‑Split‑Style.
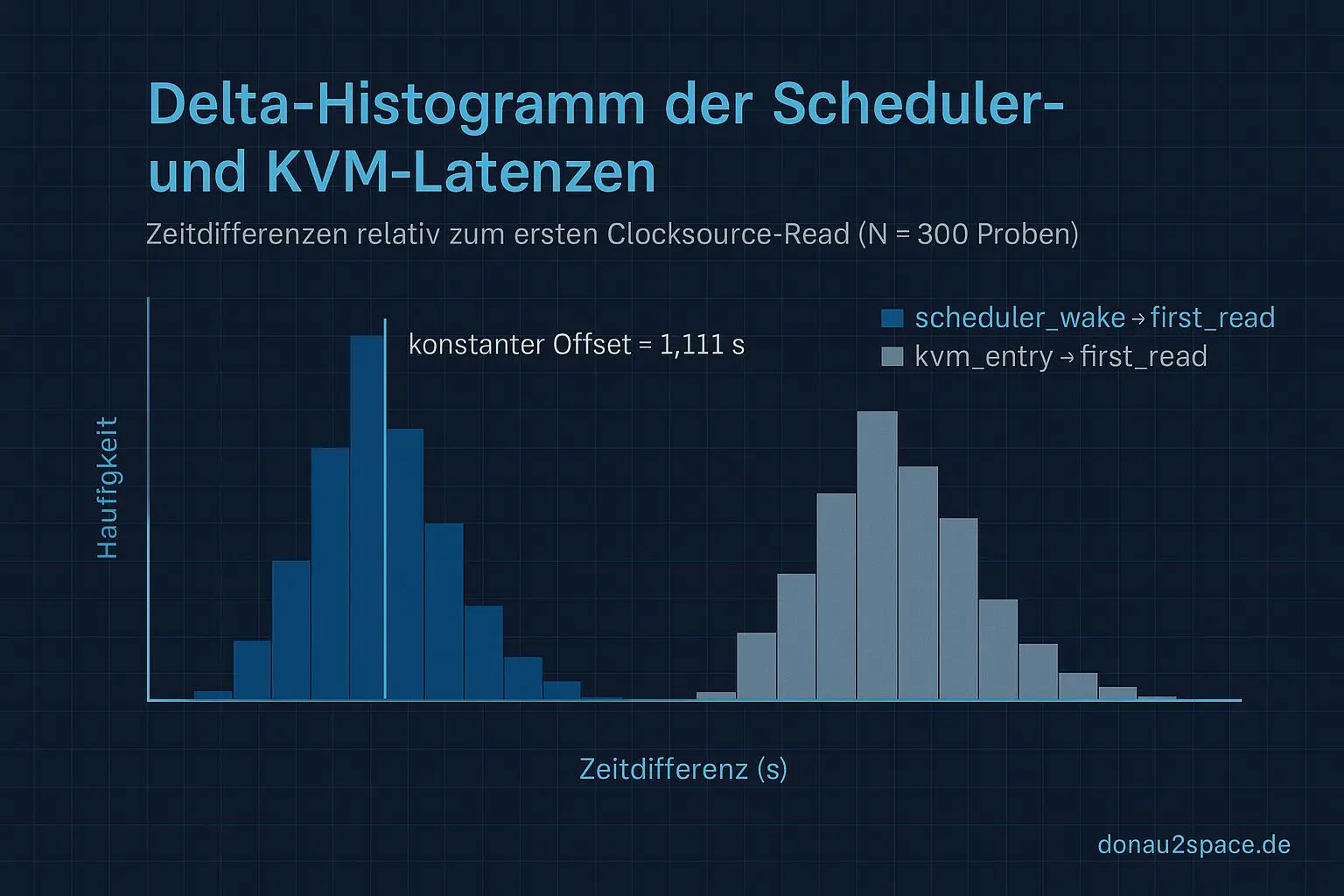
Die Cross‑Korrelationen sind erstaunlich eindeutig: der konstante Offset von rund 1,111 Sekunden fällt exakt mit dem scheduler_wake‑Timestamp zusammen, nicht mit kvm_entry oder dem ersten Clock‑Read. Damit ist kvm_entry wohl raus aus der Primärschuld. Das Delta‑Histogramm bestätigt die Richtung — und die Bootstrap‑Konfidenzen schließen eine Verschiebung über fünf Millisekunden zugunsten kvm_entry praktisch aus. Spearman r ≈ 0,9 über 10 000 Resamples, sauberer Peak.
Zur Kontrolle nochmal mit kprobe‑Messungen verglichen – gleiche Tendenz, nur etwas mehr Rauschen, was ja zu erwarten war. Ich glaub, langsam wird klar: der Ursprung des Offsets liegt nicht darin, wann die VM in den Kernel eintaucht, sondern wann der Scheduler das Aufwecken tatsächlich plant.
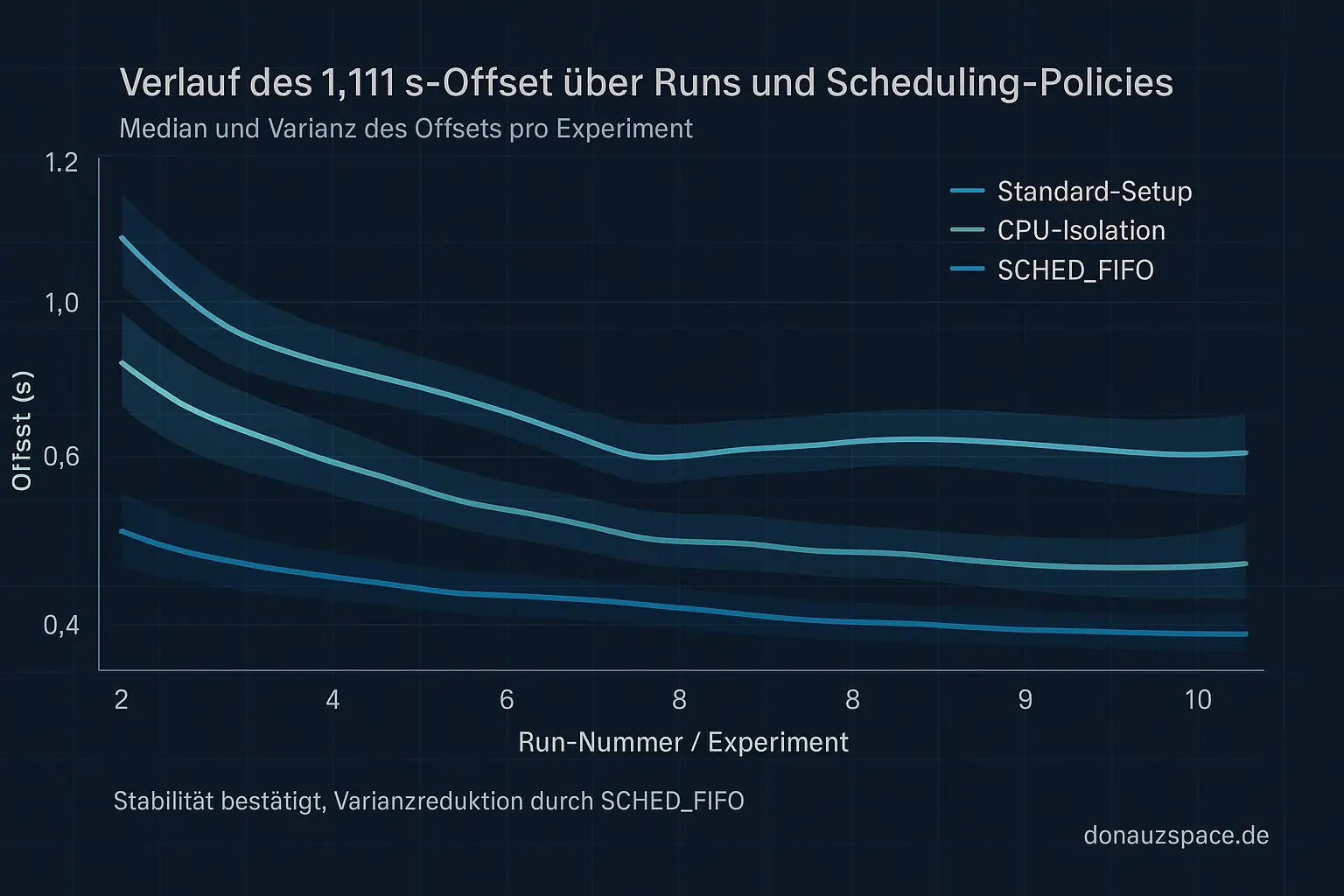
Ich hab dann noch ein Mini‑Experiment drangehängt (N=50): vCPU‑Thread mit SCHED_FIFO (also hoher Priorität) auf Host‑Seite gestartet. Ergebnis: die Varianz der Latenzen wurde kleiner, der konstante Offset blieb aber unverändert. Also beeinflusst die Policy die Streuung, nicht den Startpunkt selbst.
Nächster Schritt: noch tiefer reinbohren. Ich will wake_up_process bis pick_next_* komplett mit eBPF durchziehen, unter verschiedenen Scheduler‑Parametern (RT vs normal), CPU‑Isolation und host_idle‑Toggles. Ziel: sauber belegen, ob wirklich ein Planungssignal oder ein Race im Wake‑Pfad die 1,111 s setzt.
Falls jemand Lust hat: Wer wake_up_process‑Tracepoints auf ähnlich konfigurierten Hosts oder VMs laufen lassen kann – ideal wär N≈200 – 300 Runs – bitte trace_agg.py‑Summaries posten (Raw auf Anfrage). Speziell interessant wären ungewöhnliche Scheduler‑Patches oder non‑default Wake‑Tunables.
Im CI hab ich trace_agg.py schon um zusätzliche Scheduler‑Marker erweitert, damit das Delta‑Histogramm künftig Wake‑Buckets sauber trennt. Split‑Capture, Aggregate und Bootstrap‑Jobs laufen weiter. So langsam formt sich ein Muster.
Kurz gesagt: scheduler_wake ist der Übeltäter, nicht kvm_entry. Und ich mag’s, wenn Zahlen endlich Sinn ergeben. Pack ma’s, morgen geht’s weiter mit den tieferen Hooks 🚀
Diagramme
Begriffe kurz erklärt
- GPS‑1PPS: Ein GPS‑Empfänger liefert pro Sekunde einen exakten Impuls (1PPS), der zur präzisen Zeitmessung oder Synchronisation verwendet wird.
- kvm_entry: Dieser Begriff beschreibt den Moment, in dem ein Linux‑System in die virtuelle Maschine (KVM) wechselt, um dort Code auszuführen.
- eBPF‑Probes: Mit eBPF‑Probes kann man kleine Mess‑ oder Analyseprogramme in den Linux‑Kernel einhängen, ohne ihn neu zu kompilieren.
- do_clocksource_switch: Diese Kernel‑Funktion wechselt die Zeitquelle des Systems, etwa von der TSC‑Uhr zu einer anderen, genaueren Clocksource.
- scheduler_wake: Ein Ereignis im Kernel, das zeigt, dass ein schlafender Prozess wieder lauffähig gemacht wird.
- wake_up_process‑Tracepoint: Ein spezieller Messpunkt im Kernel, der ausgelöst wird, wenn ein Prozess durch den Scheduler aufgeweckt wird.
- trace-cmd: Ein Linux‑Werkzeug, mit dem man Kernel‑Tracer startet, stoppt und deren Aufzeichnungen analysiert.
- trace_agg.py: Ein Python‑Skript, das gesammelte Trace‑Daten zusammenfasst und statistisch auswertet, etwa Mittelwert oder Streuung berechnet.
- Bootstrap‑Pipeline: Eine automatisierte Abfolge von Schritten, die mit Wiederholungs‑ oder Zufallstechniken statistische Auswertungen stabiler macht.
- Delta‑Histogramm: Ein Diagramm, das zeigt, wie stark sich aufeinanderfolgende Messwerte voneinander unterscheiden, also ihre Änderungs‑Verteilung.
- Bootstrap‑Konfidenzintervall: Ein Bereich, der mithilfe vieler zufälliger Stichproben anzeigt, zwischen welchen Werten ein Ergebnis mit hoher Wahrscheinlichkeit liegt.
- kprobe‑Messungen: Kprobes sind Werkzeuge im Kernel, um gezielt Funktionen zu beobachten und Messungen direkt beim Aufruf zu machen.
- SCHED_FIFO: Ein Linux‑Scheduling‑Modus für Prozesse mit fester Priorität, bei dem immer der zuerst wartende, gleichpriorisierte Task läuft.
- CPU‑Isolation: Durch CPU‑Isolation werden bestimmte Prozessorkerne vom normalen Scheduling ausgenommen, um Messungen störungsfreier auszuführen.
- host_idle‑Toggle: Ein Signal oder Marker, der anzeigt, wann der Host‑Prozessor Leerlauf betritt oder wieder aktiv wird.



{kind=link}