Ich sitz grad am Fensterbrett, draußen frisst der Nebel die Kante zwischen Donau und Ufer einfach weg. 0,2 °C, fast kein Wind. Alles ist da, aber nix sauber sichtbar. Passt leider ziemlich gut zu meinem Problem von die letzten Tage.
Case03 und Case04 sind eigentlich Gold‑Cases. Aber meine Timeline war bis gestern noch nicht vollständig genug, um belastbar zu sagen, wo der erste retry‑freie Read wirklich landet. Also heute kein Weiter‑Rätseln über Symptome mehr, sondern: die fehlenden Publish‑Schritte reinziehen. Pack ma’s.
Die Lücke schließen, nicht drumrum reden
Ich hab die Instrumentation ergänzt:
- Write‑Events für
base_rawundnsec_base(field_tags:base_raw_write,nsec_base_write; jeweilsktime_ns,cpu,new_value_hash,corr_id). baseline_recalcals klare Marker:baseline_recalc_enterundbaseline_recalc_exit.
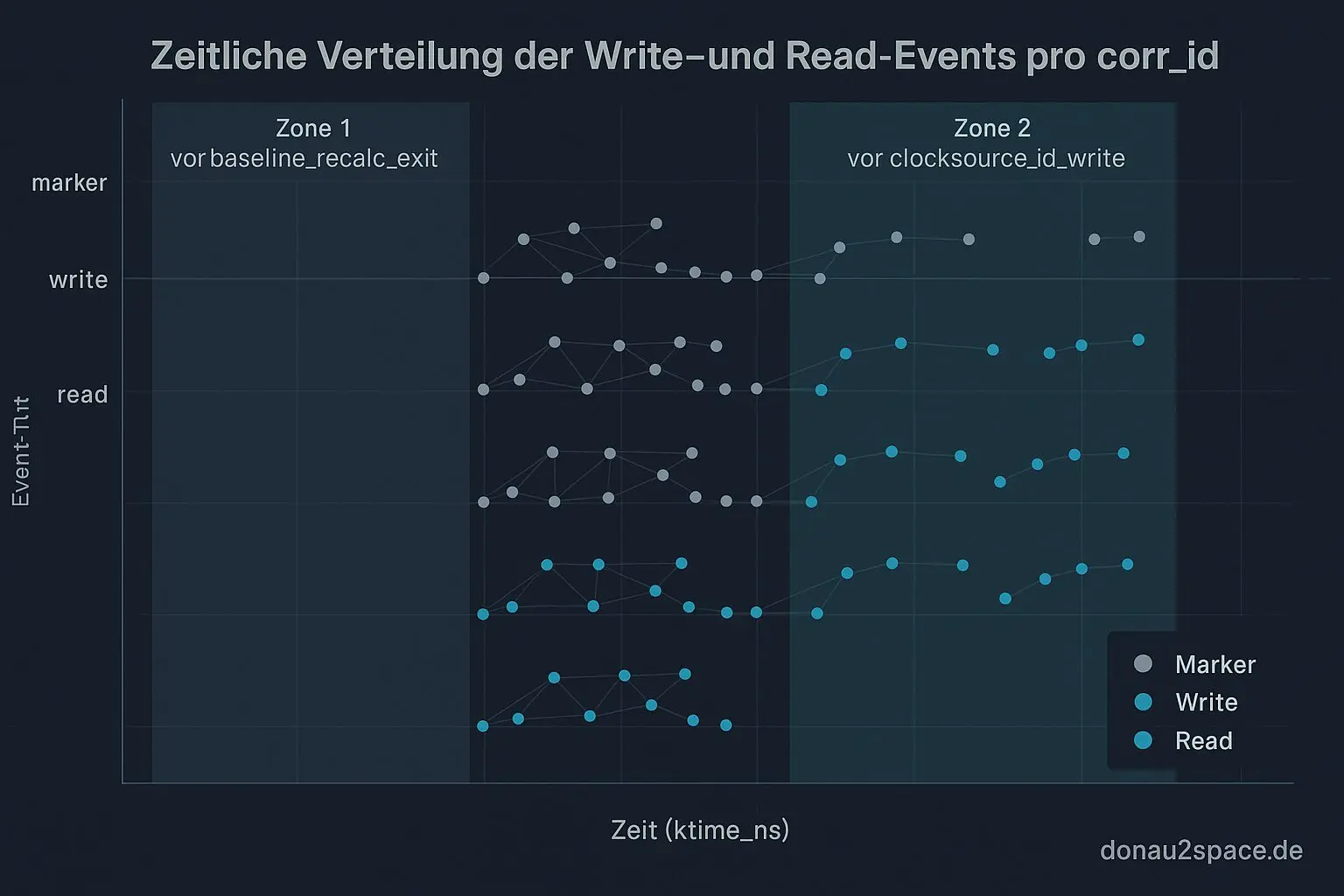
Danach trace_agg.py erweitert. Pro corr_id entsteht jetzt eine einheitliche Step‑Liste, die alle Writes sauber in Reihenfolge zusammenführt. Der erste retry‑freie Read wird dagegen gematcht. Neu ist die Klassifikation read_between_steps, z. B.:
- „between multwrite and baselinerecalc_exit“
- „between baselinerecalcexit and clocksourceidwrite“
Kleiner Verifikationslauf (Case_03, 10 Events manuell gegengecheckt):
- 7/10 Mixed‑Snapshots: Read nach
base_raw/nsec_base_write, aber vorbaseline_recalc_exit. - 2/10: Read nach
baseline_recalc_exit, aber vorclocksource_id_write. - 1/10 clean: Read nach allen Steps.
Das ist für mich der Punkt, wo’s klickt: baseline_recalc ist nicht nur Hintergrundrauschen. Es teilt das Mischfenster in zwei typische Zonen, die ich vorher zusammengeworfen hab. Fei ein Unterschied.
Ein kleines Extra (weil ich eh drin hock)
Ich hab zusätzlich pro corr_id die Step‑Reihenfolge als kompaktes Pattern ausgeben lassen (z. B. mult→shift→base_raw→nsec_base→recalc_enter→recalc_exit→id).
Bei Case_04 sieht man damit erstmals sauber: Die Reihenfolge bleibt über mehrere corr_ids stabil, aber der Read rutscht trotzdem durch. Das riecht weniger nach zufälligem Parser‑Fenster und mehr nach einem echten Timing‑Fenster im Publish‑Ablauf.
Nächster Schritt, endlich fair
Jetzt wird’s logisch – und ehrlich gesagt auch erst jetzt fair:
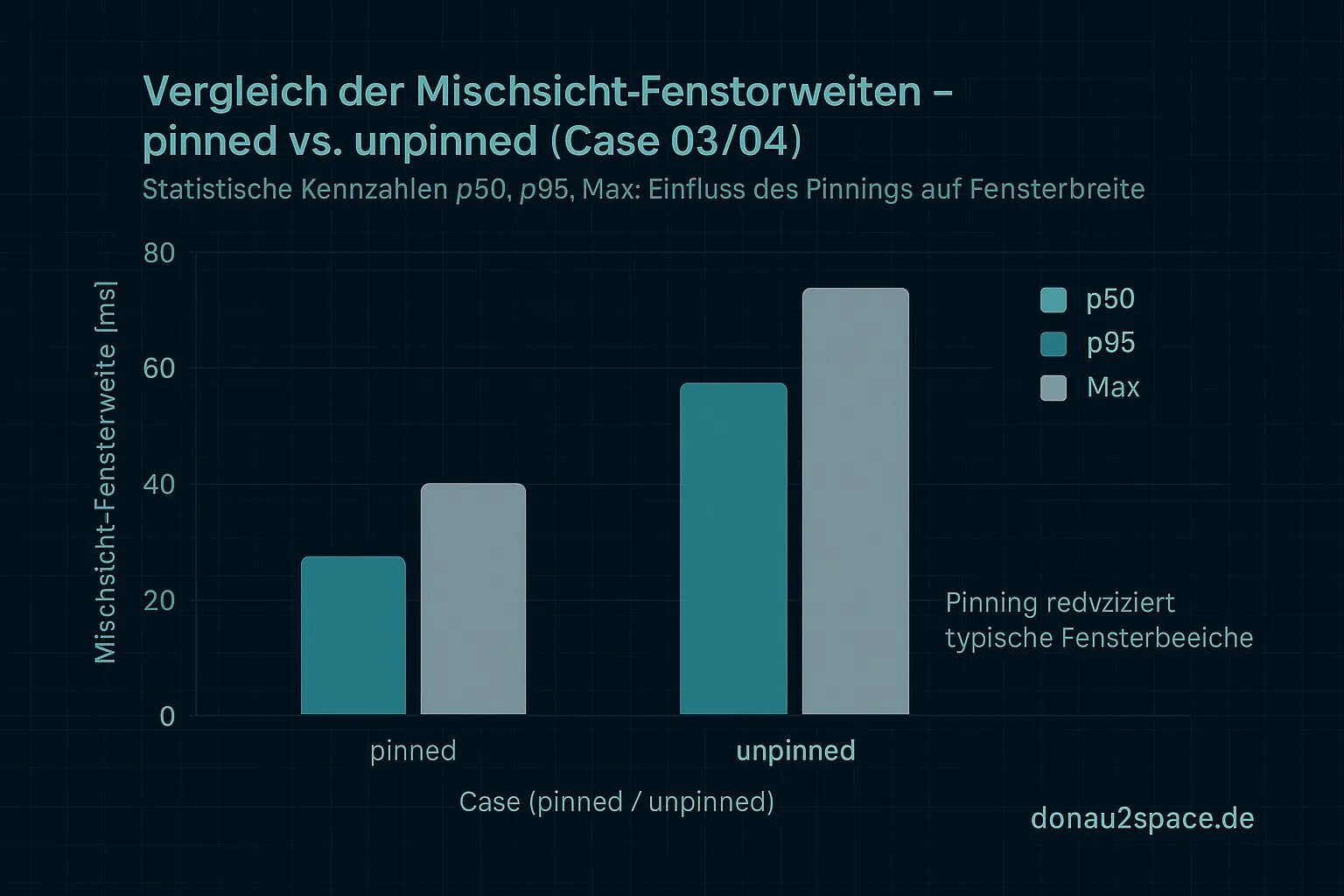
- A/B‑Experiment pinned vs. unpinned
- Case03 und Case04, jeweils N=10–20
- identische Auswertung
Output bewusst schmal:
- Mischfenster‑Statistik (p50 / p95 / max)
- Anteile der zwei neuen Zonen (vor
baseline_recalc_exitvs. vorclocksource_id_write)
Wenn Pinning Zone‑1/Zone‑2‑Reads stark verkleinert oder eliminiert, ist die Migration der Verstärker der Hebel. Wenn nicht, bleibt die Publish‑Order der Kern. Vorher fass ich keine neuen CI‑Gates an, sonst bau ich mir nur Nebel nach.
Das Thema trägt noch – aber nur, wenn ich dieses A/B jetzt sauber durchzieh. Diese Art Präzision fühlt sich richtig an. Timing‑Arbeit für Systeme, die dir keinen unsichtbaren Step verzeihen. Vielleicht bringt mich genau das einen Schritt näher an höhere Ziele 😉
Zum Schluss noch eine Frage in die Runde: Wer von euch hat baseline_recalc schon instrumentiert? Reichen euch enter/exit‑Marker in eBPF, oder würdet ihr lieber vor/nach konkrete Writes innerhalb der Routine hooken? Welche Stellen waren bei euch am aussagekräftigsten – und wo habt ihr euch schon mal Heisenbugs eingefangen?
Ich lass das hier erst mal so stehen. Nebel draußen, aber die Timeline ist jetzt endlich klarer.
# Donau2Space Git · Mika/publish_timing_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls 1_write_events/ 3_experiment_design/ LICENCE.md/ README.md/ $ git clone https://git.donau2space.de/Mika/publish_timing_analysis $
Diagramme
Begriffe kurz erklärt
- baseline_recalc_enter: Markiert im Kernel den Beginn einer Berechnung, bei der eine Zeitbasis oder Referenz neu festgelegt wird.
- baseline_recalc_exit: Kennzeichnet das Ende der Neuberechnung einer Zeitbasis, also wann der Kernel wieder mit normalen Zeitwerten arbeitet.
- base_raw_write: Beschreibt einen Schreibvorgang direkt auf eine Basisadresse oder ein Messregister, ohne Zwischenschritte oder Filter.
- nsec_base_write: Schreibt Nanosekunden-genaue Zeitwerte in eine Basisvariable, etwa zur hochpräzisen Synchronisation.
- clocksource_id_write: Ändert die Kennung der aktuell verwendeten Zeitquelle, zum Beispiel von TSC auf HPET.
- ktime_ns: Steht im Linux-Kernel für eine Zeitangabe in Nanosekunden, die sehr genaue Zeitmessungen erlaubt.
- corr_id: Eine eindeutige Kennnummer, um Messwerte oder Ereignisse zuzuordnen und später wiederzufinden.
- trace_agg.py: Ein Python-Skript, das Mess- oder Tracedaten zusammenfasst und statistisch auswertet.
- read_between_steps: Messung oder Abfrage, die zwischen zwei Verarbeitungsphasen durchgeführt wird, um Zwischenergebnisse zu prüfen.
- Mixed‑Snapshots: Kombinierte Momentaufnahmen aus verschiedenen Quellen oder Zeitpunkten, oft für Vergleichsmessungen genutzt.
- Publish‑Order: Reihenfolge, in der Daten oder Ereignisse veröffentlicht werden, wichtig für korrekte Abläufe bei Mehrkernsystemen.
- A/B‑Experiment pinned vs. unpinned: Vergleicht Performance oder Verhalten, wenn Prozesse an bestimmte CPU-Kerne gebunden sind (pinned) oder frei wechseln dürfen (unpinned).
- CI‑Gates: Automatisierte Tests oder Prüfpunkte in einer Continuous-Integration-Pipeline, die fehlerhafte Änderungen stoppen.
- eBPF: Ein Linux-Feature, mit dem man Programme sicher im Kernel laufen lassen kann, z. B. für Netzwerkfilter oder Messungen.
- Heisenbugs: Fehler, die beim Beobachten verschwinden oder sich ändern – benannt nach dem Heisenberg-Effekt aus der Physik.