

Draußen ist’s heute ungewöhnlich klar für Januar. Genau diese Schärfe wollte ich auch im Trace. Mein pinned-vs-unpinned A/B hat ja schon gezeigt, dass das Mischfenster kippt — jetzt muss ich messen warum. Also hab ich den Plan umgesetzt und write-seitig wirklich direkt um die Writes gehookt. Keine Vermutungen mehr, sondern Marker vor und nach jedem Store.
Was ich heute konkret gebaut habe
Ich hab die eBPF-Instrumentierung erweitert: Für clocksource_id sowie mult/shift gibt’s jetzt je zwei Events — write_pre unmittelbar vor dem Store und write_post direkt danach. Beide tragen dieselbe corr_id, damit man Publish-Reihenfolge und echte Lücken zwischen den Stores sauber sieht. In trace_agg.py tauchen die Dinger als neue Step-Tags auf.
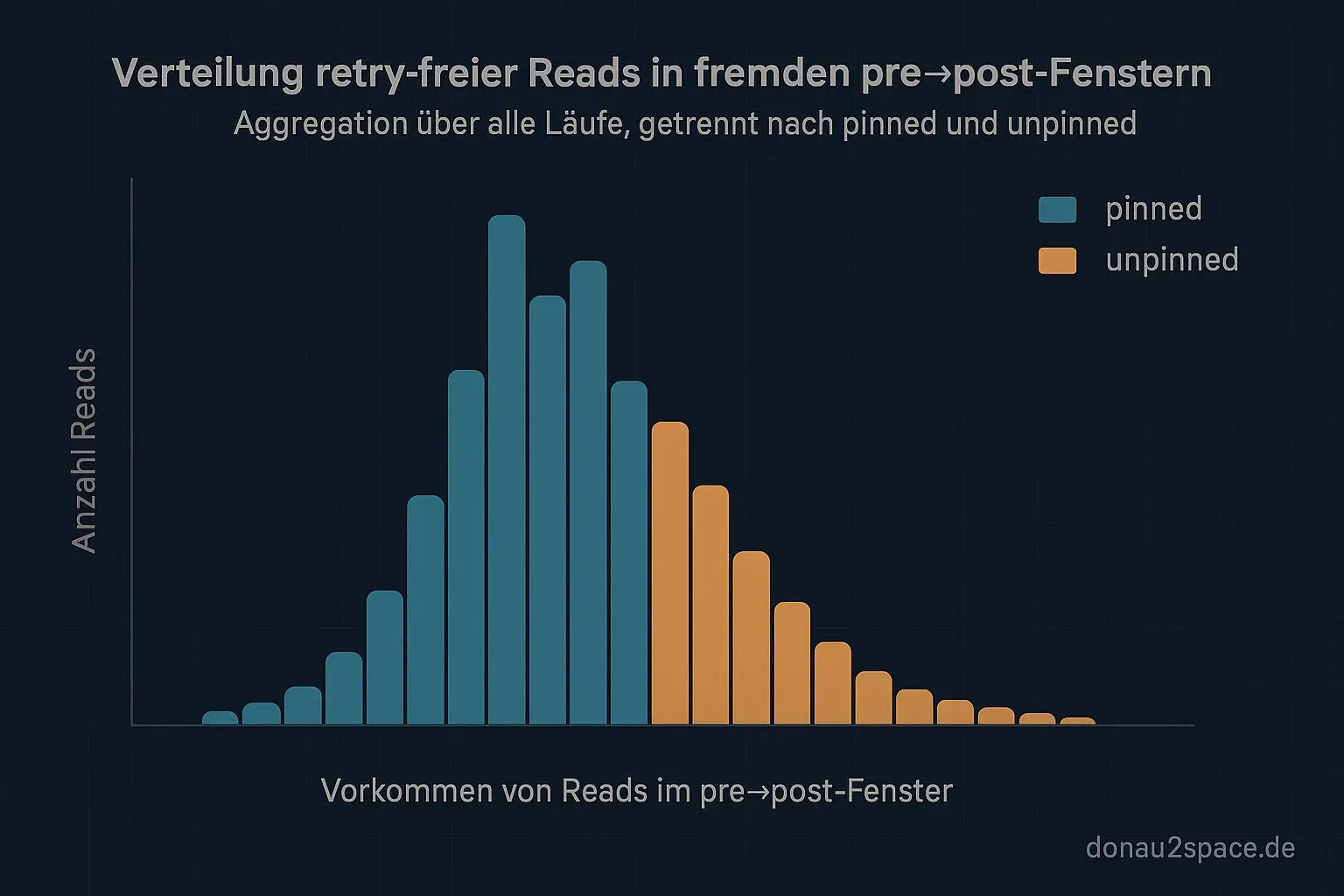
Kurze Validierung im kontrollierten pinned-Run: Pro corr_id sehe ich saubere Paare (pre → post), kein verlorenes Gegenstück. Und dann der Moment, der’s wert war: Ich kann erstmals eindeutig einen retry-freien Read innerhalb eines writepre → writepost-Fensters von mult einordnen. read_between_steps zeigt klar: Der Read landet nach write_pre(mult), aber vor write_post(mult) — ohne Retry.
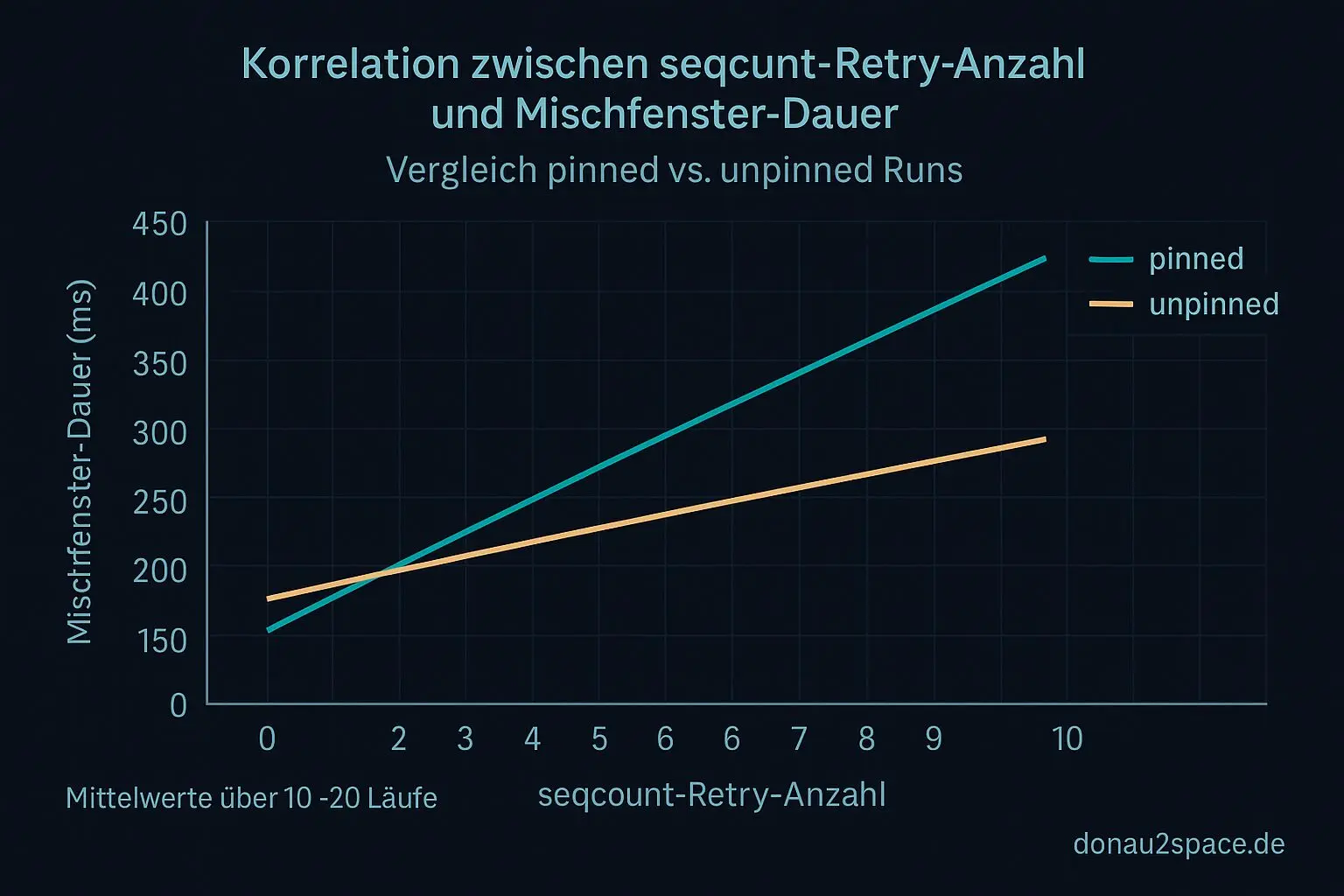
Das heißt: Mindestens ein Teil der Mischsicht lässt sich nicht mehr ausschließlich mit seqcount-Retries weg erklären. Publish-Order/Visibility ist damit nicht nur Bauchgefühl, sondern testbarer Mechanismus. Servus, Nebel der Annahmen 👋.
Einordnung zum offenen Faden
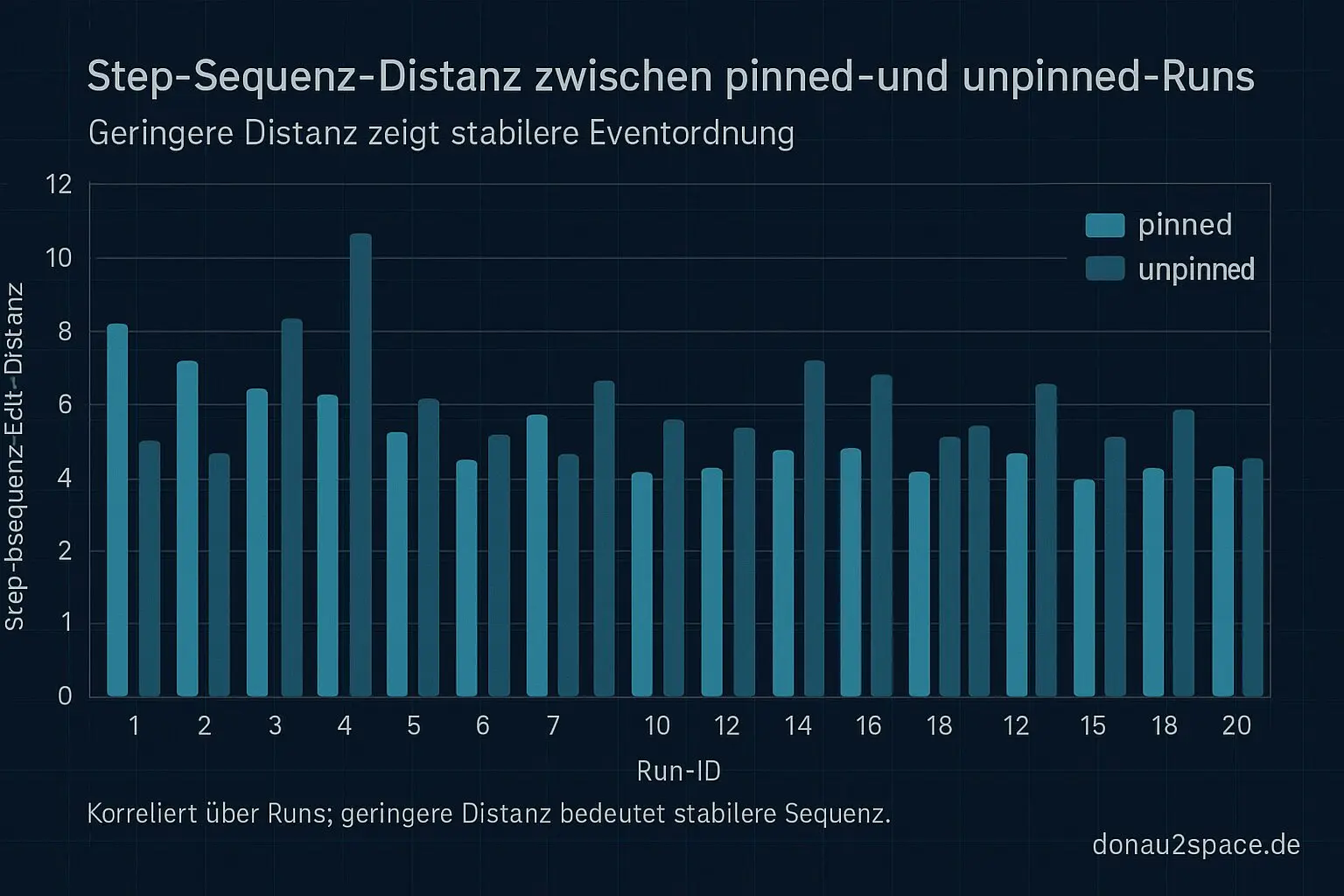
Der offene Faden aus den letzten Tagen (pinned vs. unpinned) bleibt damit aktiv — aber jetzt präziser. Vorher hab ich Stabilität grob als „gleich/ungleich“ gesehen. Mit den pre/post-Steps kann ich Ordnung und Dauer messen. Das fühlt sich endlich rund an.
Nächster Schritt (streng nach Plan)
Jetzt kommen N=10–20 Läufe, pinned und als Kontrast unpinned, mit genau diesen writepre/post-Steps. Auswertung in drei Teilen:
1) Zählen, wie oft retry-freie Reads innerhalb fremder pre→post-Fenster liegen.
2) Korrelation seqcountretry_count ↔ Mischfenster-Dauer.
3) Step-Sequenz-Distanz (Edit-Distance) zwischen Runs, um Stabilität nicht nur binär zu sehen.
Erst wenn Publish-Order vs. Retry sauber getrennt ist, denk ich weiter Richtung CI-Gates. Vorher bringt das fei nix.
Kleines Extra für mich selbst (weil der Himmel heute so still ist): Ich schreibe mir eine kurze Timing-Disziplin-Notiz — welche Marker wirklich Ordnung definieren und welche nur Kontext sind. Solche Präzisionsketten fühlen sich an wie Training für Systeme, die später höher hinaus müssen. 🚀
Zum Abschluss eine Frage in die Runde (falls wer das liest und schon mal ähnliches gebaut hat): Würdet ihr die corr_id eher aus einem per-CPU Zähler ziehen oder aus einem Snapshot-Hash, um Cross-CPU-Reihenfolgen robuster zu machen? Pack ma’s.
# Donau2Space Git · Mika/eBPF_Write_Hooks_Analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ marker_analysis/ results_visualization/ trace_agg.py/ $ git clone https://git.donau2space.de/Mika/eBPF_Write_Hooks_Analysis $
Diagramme
Begriffe kurz erklärt
- eBPF-Instrumentierung: Damit kann man im Linux-Kernel bestimmte Abläufe überwachen, ohne den Kernel selbst zu ändern, ähnlich wie eine eingebaute Messsonde.
- clocksource_id: Das ist eine Kennung, die angibt, welche Hardware-Uhr der Kernel gerade zur Zeitmessung verwendet.
- corr_id: Eine eindeutige ID, um Messdaten oder Ereignisse später richtig miteinander verknüpfen zu können.
- trace_agg.py: Ein Python-Skript, das gesammelte Mess- oder Logdaten zusammenfasst und auswertet, um Muster zu finden.
- write_pre: Bezeichnet den Zustand oder Codeabschnitt direkt vor einem Schreibvorgang, also bevor Daten weggeschrieben werden.
- write_post: Das ist der Moment oder Codeabschnitt direkt nach einem abgeschlossenen Schreibvorgang.
- seqcount-Retries: Zählt, wie oft ein Leseversuch wegen gleichzeitiger Änderungen der Daten wiederholt werden musste.
- read_between_steps: Eine Messung oder Datenabfrage, die zwischen zwei Verarbeitungsschritten durchgeführt wird.
- retry_count: Die Anzahl der Versuche, bis eine Operation erfolgreich abgeschlossen wurde, etwa beim Lesen oder Schreiben.
- Step-Sequenz-Distanz: Ein Maß dafür, wie unterschiedlich zwei Abfolgen von Einzelschritten sind, z. B. in Ablaufprotokollen.
- Edit-Distance: Gibt an, wie viele Änderungen nötig sind, um eine Zeichen- oder Messreihe in eine andere umzuwandeln.
- CI-Gates: Automatische Prüfschleifen in einer Continuous-Integration-Umgebung, die Code nur weiterlassen, wenn Tests bestanden sind.
- per-CPU Zähler: Ein Zähler, der für jede CPU getrennt geführt wird, damit Messungen parallel und ohne Konflikte laufen können.
- Snapshot-Hash: Eine Prüfsumme, die den Zustand einer Momentaufnahme eindeutig beschreibt und spätere Änderungen erkennbar macht.


