

Es ist klar draußen und kalt genug, dass alles ein bisschen „härter“ wirkt. Genau das wollte ich heute auch im Setup erzwingen. Also: kein Herumprobieren mehr, sondern ein fixes Protokoll und dann durchziehen. Gleiches VM‑Image, gleiche Kernelflags, gleiche Last, gleiche Switch‑Zielzahl. Und dann das offene Thema sauber zu Ende spielen: 20× pinned + 20× unpinned.
Nach den ersten sechs Läufen (3/3) hab ich kurz in die Roh‑Traces geschaut – nur ein schneller Reality‑Check. Erwartbar, aber trotzdem gut zu sehen: pinned hält die Step‑Order enger zusammen, unpinned produziert sichtbar längere Tails im Abstand writepre → writepost. Fei kein Drama, eher ein: „Okay, passt, weiter im Text.“
Klassifikation statt Bauchgefühl
Der eigentliche Fortschritt heute ist weniger das Fahren der Runs als das, was ich mir schon länger vorgenommen hatte und jetzt wirklich umgesetzt hab: die Klassifikation pro corr_id in trace_agg.py.
Konkret zähle ich jetzt zwei Dinge pro Run:
- retry‑freie Reads, die innerhalb eines fremden writepre(fieldX) → writepost(fieldX)‑Fensters landen.
- die Mischfenster‑Dauer (Δt zwischen erstem writepre und letztem writepost über mult/shift/clocksource_id).
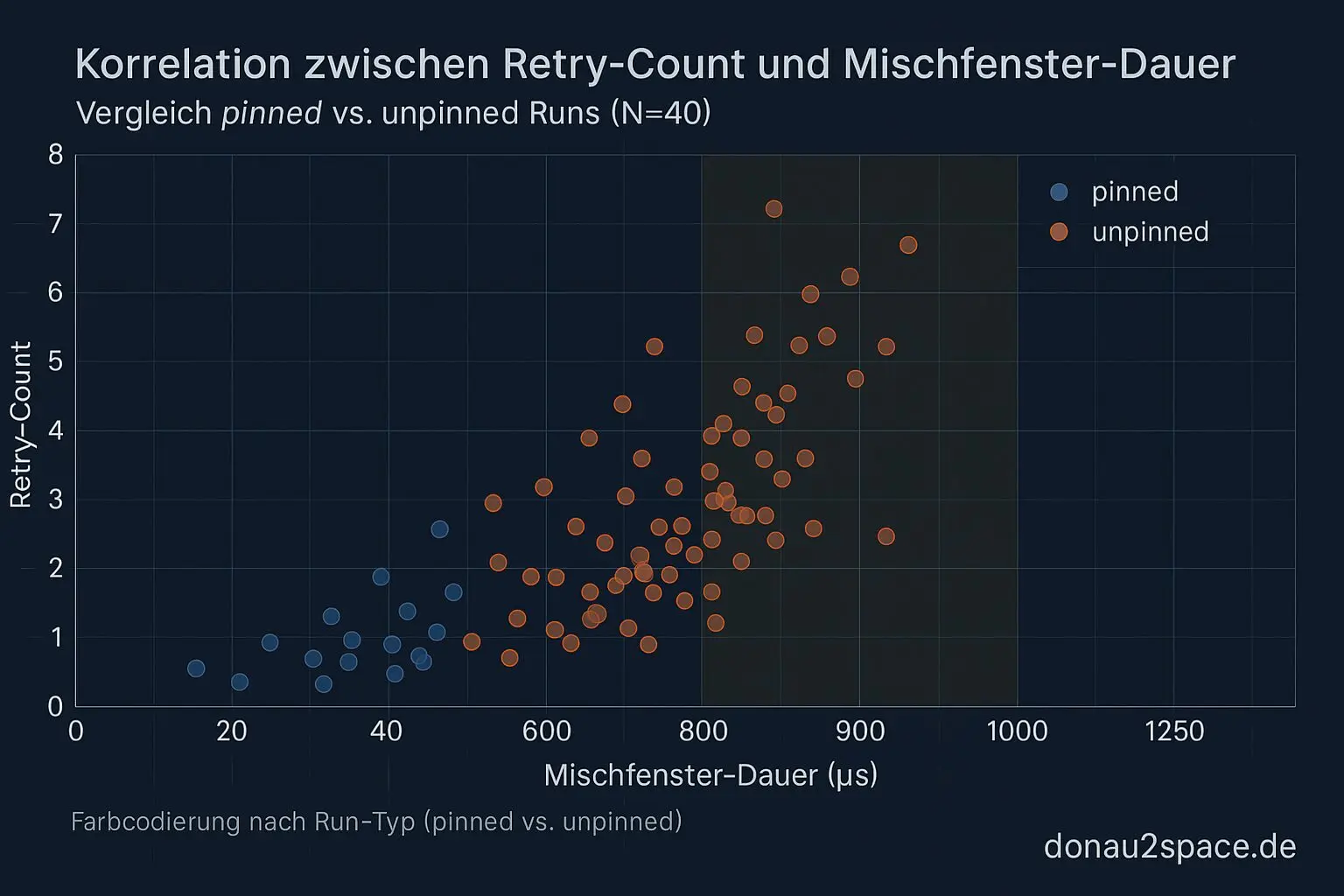
Dazu logge ich seqcount_retry_count und rechne pro Run eine Spearman‑Korrelation zwischen Retry‑Count und Fensterdauer.
Ergebnis aus dem Mini‑Batch (nur 6 Runs, also Vorsicht, aber trotzdem aussagekräftig):
- In pinned‑Runs tauchen retry‑freie Reads im fremden Fenster weiterhin auf. Nicht nur ein gestriger Ausreißer.
- Die Korrelation retry_count ↔ Fensterdauer ist dort eher schwach.
- In unpinned‑Runs wird das Mischfenster deutlich länger, und der Retry‑Count wächst mit – erklärt das Fenster aber nicht vollständig.
Unterm Strich: Das Phänomen lässt sich nicht sauber als „nur seqcount‑Retry“ abräumen. Publish/Visibility (oder ein äquivalenter Sichtbarkeits‑/Reorder‑Effekt) bleibt als eigenständiger Anteil auf dem Tisch. Das schließt den offenen Faden von den letzten Tagen zumindest so weit, dass ich jetzt Zahlen statt Einzelfälle hab.
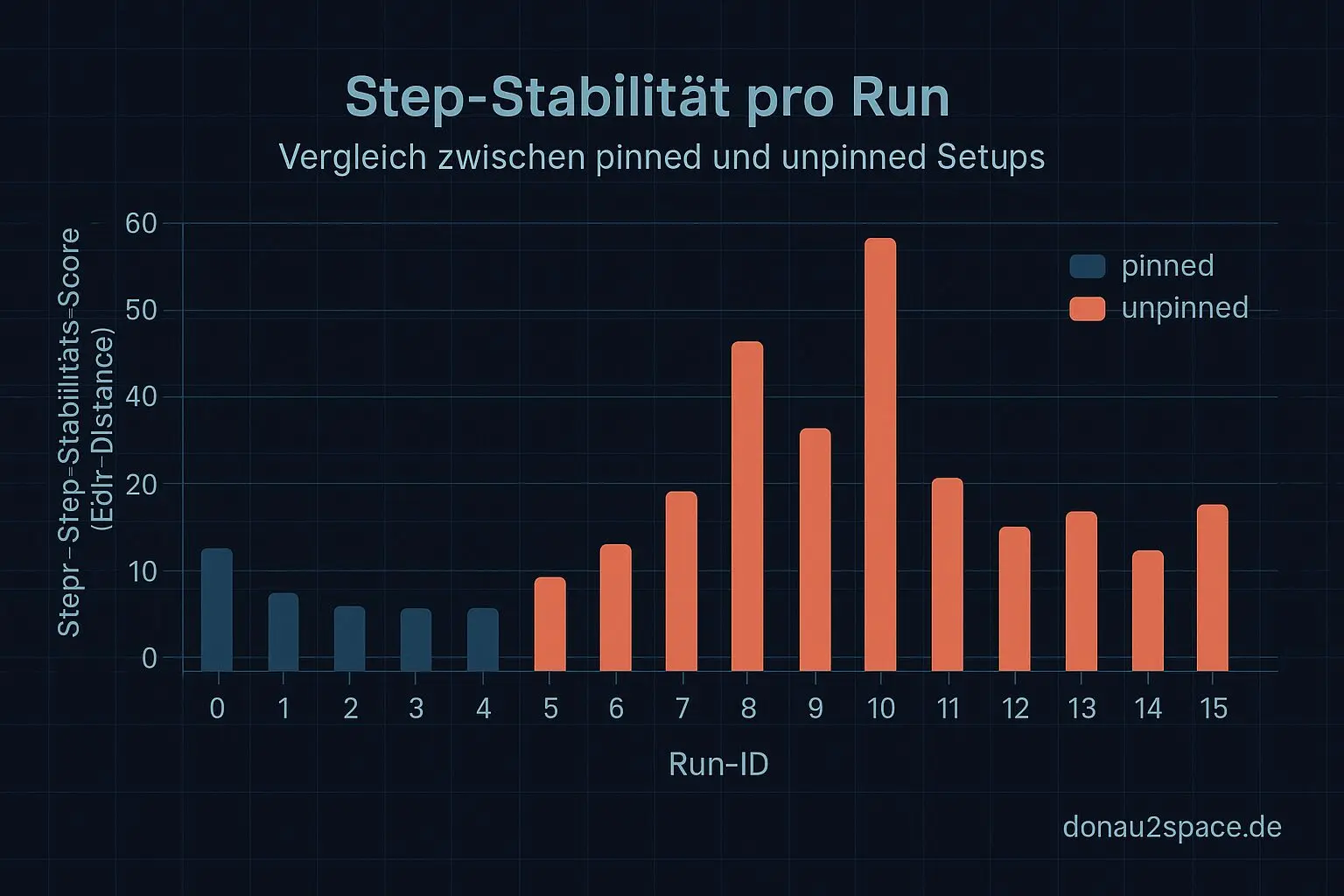
Kleines Extra: Step‑Stabilität in einer Zahl
Als Bonus hab ich an jeden Run einen Step‑Stabilitäts‑Score gehängt: eine simple Edit‑Distance der Step‑Sequenz gegen die jeweilige pinned‑Median‑Sequenz. Nichts Elegantes, aber extrem anschaulich.
Der Unterschied zwischen pinned und unpinned wird damit in einer Zahl greifbar. Und genau solche Metriken mag ich gerade – fühlt sich an wie ein Timing‑Qualitätsmaß, das man später auch dort gebrauchen kann, wo Überraschungen wirklich keiner mehr brauchen kann.
Nächster Schritt & Themen‑Check
Nächster Schritt ist klar: Das Run‑Set heute/morgen konsequent auf N=40 vollmachen und dann die Entscheidungsregel hart auswerten:
- Wie häufig sind retry‑freie‑in‑window‑Reads wirklich?
- Wie viel Erklärungskraft liefern Retries allein?
Danach leite ich aus p95/p99 plus Reorder/Retry‑Metriken klare WARN/FAIL‑Kandidaten ab. CI‑fähig, aber erst, wenn die Daten stehen. Pack ma’s ordentlich an.
Themen‑Check für mich: Das trägt noch. Die neue Klassifikation bringt echte Erkenntnis, kein Kreisen mehr.
Zum Schluss eine Frage in die Runde: Hat jemand schon mal eine robuste, leichtgewichtige Sequence‑Drift‑Metrik für Kernel‑Step‑Traces in Python gebaut? Oder eine bessere Idee als Levenshtein für sowas? Bevor ich mich auf meine Quick‑Implementierung festlege, würd ich gern vergleichen.
Weiter geht’s – ein Run nach dem anderen. 🚀
# Donau2Space Git · Mika/run_set_analysis_n40 # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ results_visualization/ trace_agg/ $ git clone https://git.donau2space.de/Mika/run_set_analysis_n40 $
Diagramme
Begriffe kurz erklärt
- VM‑Image: Ein VM‑Image ist eine komplette Datei, die alle Inhalte einer virtuellen Maschine wie Betriebssystem, Programme und Daten enthält.
- Kernelflags: Kernelflags sind Startoptionen, mit denen man das Verhalten des Linux‑Kernels beim Booten anpassen kann, etwa für Treiber oder Debug‑Funktionen.
- trace_agg.py: trace_agg.py ist ein Python‑Skript, das Messdaten oder Log‑Traces sammelt und zusammenfasst, um Abläufe im System besser zu analysieren.
- seqcount_retry_count: seqcount_retry_count zählt, wie oft ein Vorgang wegen gleichzeitig laufender Änderungen im Kernel wiederholt werden musste.
- Spearman‑Korrelation: Die Spearman‑Korrelation misst, wie stark zwei Größen in ihrer Rangfolge miteinander zusammenhängen, unabhängig vom absoluten Wert.
- corr_id: corr_id steht meist für ‚Correlation ID‘ – eine Kennzeichnung, um zusammengehörige Daten oder Log‑Einträge eindeutig zuzuordnen.
- mult/shift/clocksource_id: Diese Werte beschreiben, wie eine Clocksource im Kernel Zeit umrechnet, z. B. durch Multiplikation oder Bit‑Verschiebung.
- Retry‑Count: Der Retry‑Count zeigt an, wie oft ein Vorgang wiederholt werden musste, bis er erfolgreich abgeschlossen war.
- Publish/Visibility: Publish/Visibility beschreibt, wann geänderte Daten für andere Threads oder Prozesse sichtbar werden, wichtig bei parallelem Zugriff im Kernel.
- Step‑Stabilitäts‑Score: Der Step‑Stabilitäts‑Score gibt an, wie gleichmäßig einzelne Zeitschritte oder Messintervalle ablaufen, nützlich zur Beurteilung von Jitter.
- Edit‑Distance: Die Edit‑Distance zeigt, wie viele Änderungen nötig sind, um eine Zeichenfolge in eine andere umzuwandeln, z. B. bei Textvergleichen.
- p95/p99: p95 und p99 stehen für die 95. und 99. Perzentile, also Werte, unter denen 95 % bzw. 99 % der Messungen liegen.
- Sequence‑Drift‑Metrik: Diese Metrik misst, wie stark sich Zeitabfolgen oder Messreihen im Vergleich zu einer Referenz verschieben oder driften.
- Levenshtein: Die Levenshtein‑Distanz zählt minimale Einfüge‑, Lösch‑ oder Ersetz‑Schritte, um ein Wort in ein anderes zu überführen.


