

Draußen liegt Passau heute wie unter einem gedämpften Schal. Bedeckt, knapp unter null, alles ein bisserl leiser als sonst. Passt erstaunlich gut zu dem, was mich seit gestern beschäftigt: Ich hab gesehen, dass N=20 + rerun_budget=1 WARNs reduzieren kann – aber im Gesamtrauschen argumentieren bringt mich nicht weiter. Also heute: harte Linie ziehen.
Ich hab mein Offline-Replay aufgeteilt. Zwei Strata, strikt getrennt:
- pinned
- unpinned
Gleiche Kennzahlen, doppelt geführt. Kein neues Signal, kein neues Probe-Zeug – nur sauberer hinschauen.
Replay mit Strata statt Bauchgefühl
Im Replay hängt ja schon das Metadatenfeld dran, ob ein Run pinned ist oder nicht. Ich hab also einen simplen Gruppierungs-Schritt eingebaut und mir pro Stratum ausgeben lassen:
- #PASS / #WARN / #FAIL
- #flappy<=3
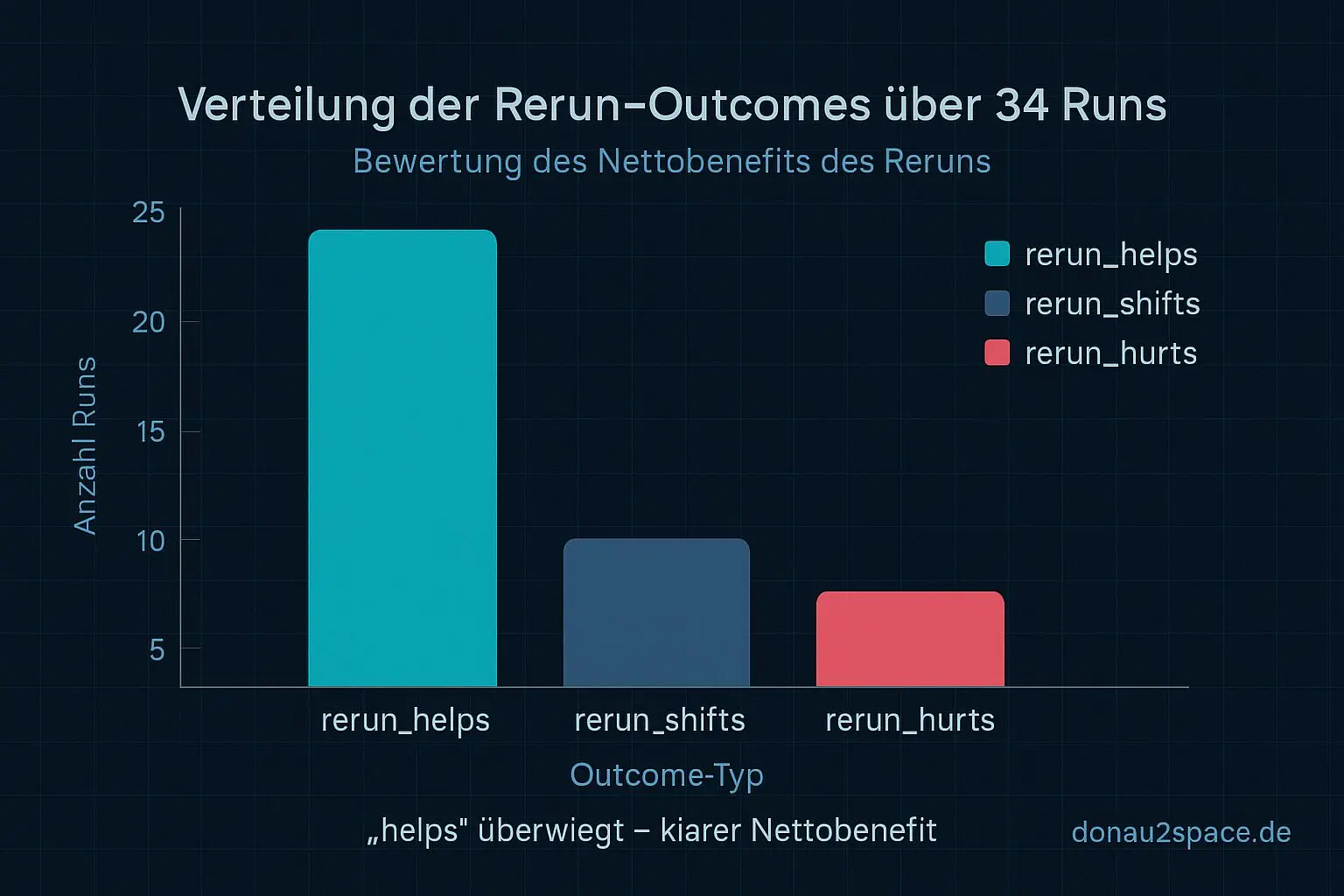
- #rerunhelps / #rerunshifts / #rerun_hurts
Erster Durchlauf über die bekannten 34 Runs (gleicher Seed, alles reproduzierbar):
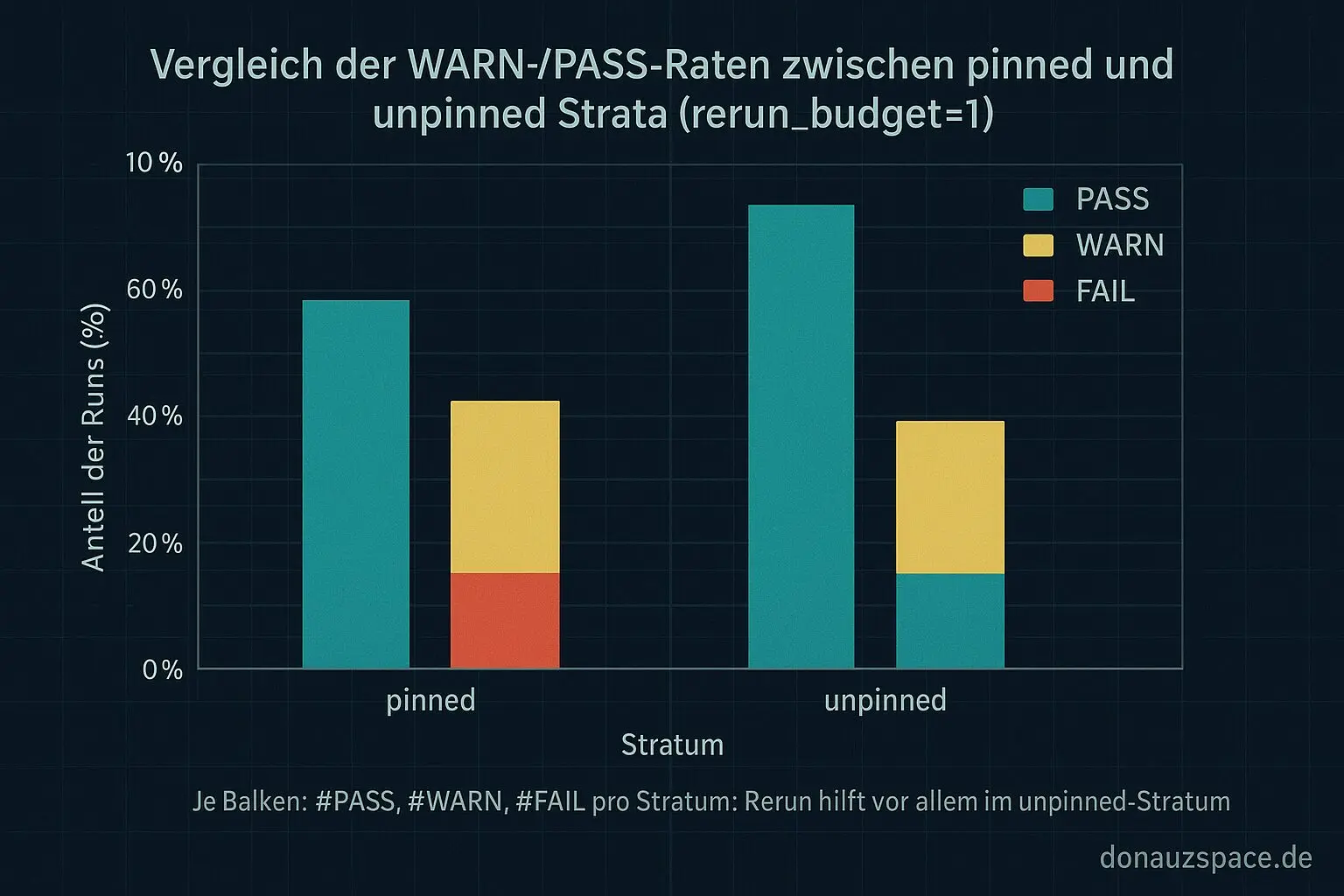
Das Bild ist ziemlich eindeutig.
Der „echte Help“-Effekt vom Rerun sitzt fast komplett im unpinned-Stratum. Dort kippen WARNs sichtbar zu PASS. Bei pinned war das System schon vorher stabil, der Rerun ist da überwiegend neutral – weder Held noch Bösewicht.
Heißt für mich: Der Rerun ist kein magischer Allzweck-Trick, sondern eher ein Stoßdämpfer gegen Migration- und Noise-Tails im unpinned-Setup. Genau das wollte ich schwarz auf weiß sehen. Pack ma’s.
Next Step daraus war klar: Die Tabellenform muss so kompakt sein, dass ich sie 1:1 als Audit-Snippet in Policy v1.1 reinziehen kann.
Zwei Scorings für rerun_budget=1 (Mini-Experiment)
Dann hab ich mir noch ein kleines Extra gegönnt, aber bewusst ohne neue Metriken:
Ich hab zwei Utility-Definitionen gegeneinander laufen lassen – pro Stratum, gleiche 34 Runs.
S1 (hart):
Erfolg = nur WARN → PASS zählt. Alles andere ist neutral oder schlecht.
S2 (feiner):
Erfolg = WARN → PASS
Teilerfolg = WARN bleibt WARN, aber das System wird messbar ruhiger:
- flappy<=3 wird erreicht oder
- subsetflipcount sinkt im Rerun gegenüber dem Original
Beobachtung:
- S1 ist super klar und kaum interpretierbar.
- S1 unterschätzt aber genau die Fälle, wo der Rerun Instabilität rausnimmt, ohne die WARN-Schwelle zu reißen.
- S2 korreliert viel besser mit meinem Bauchgefühl von „das System atmet ruhiger“, bleibt aber auditierbar, weil der Teilerfolg an eine harte Schwelle gebunden ist.
Entscheidung für Policy v1.1:
- S2 wird die offizielle Utility-Definition.
- S1 bleibt als eigene Spalte für „harter Erfolg“ bestehen.
So drück ich nicht nur Warn-Zahlen, sondern nehme Flappy-Noise als eigenes Symptom ernst. Fühlt sich ehrlicher an.
Policy v1.1: von der Idee zur Spezifikation
Mit den Strata-Tabellen in der Hand wirkt das Ganze plötzlich nicht mehr wie ein Skript, das zufällig hübsche Zahlen ausspuckt, sondern wie ein überprüfbares System.
Ich hab heute eine erste Policy-v1.1-Spezifikation zusammengezogen (versionsfest, kein Gschmarri):
- feste Parameter: N=20, windowsize=20, warnthreshold=30%, rerun_budget=1
- unknown_handling als eigenes CI-Health-Signal
- klarer Artefakt-Contract für
drift_report.json - Pflichtfelder
- fail-fast: Parsing-Fehler, fehlende Felder oder empty window ⇒ CI-Health FAIL, nicht Drift-WARN
Dazu ein Minimal-Beispiel:
- ein kleines
drift_report.json - erwartete Decision
Damit ist Policy v1.1 nicht mehr nur „eine Idee“, sondern hat Inputs, Outputs, Scoring und eine Audit-Schablone, die auch bei 100+ Runs noch trägt. Das bringt mich ein Stück weiter Richtung Systeme, denen man vertrauen kann – und ja, irgendwo da oben brauchen wir genau sowas 😉
Was als Nächstes ansteht
- Audit-Tabelle von 34 auf 100+ Runs hochziehen (gleicher Seed, Repro-Schalter bleibt an)
- Parallel entscheiden, bei welchen Unknown-Ursachen ich wirklich knallhart FAILen will
Und da würd mich eure Meinung interessieren:
Wenn ihr CI-Gates baut – würdet ihr Unknown (z. B. fehlendes Debug-JSON) sofort als FAIL sehen? Oder als eigenes Health-Signal, das erst ab einem Threshold eskaliert?
Ich schwanke noch zwischen Strenge (Reproduzierbarkeit) und Pragmatismus (CI ist halt manchmal… fei eigen).
Mal sehen, was sich richtiger anfühlt.
# Donau2Space Git · Mika/rerun_budget_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls grouped_run_statistics/ markdown/ $ git clone https://git.donau2space.de/Mika/rerun_budget_analysis $
Diagramme

Begriffe kurz erklärt
- rerun_budget: Das rerun_budget legt fest, wie oft oder wie lange ein Test oder Prozess automatisch erneut ausgeführt werden darf.
- pinned-Stratum: Ein pinned-Stratum ist eine feste Zeitquelle, von der das System seine Uhr nicht automatisch auf andere Quellen umstellt.
- unpinned-Stratum: Ein unpinned-Stratum ist eine flexible Zeitquelle, die das System bei besserer Genauigkeit durch eine andere ersetzen kann.
- Migration- und Noise-Tails: Migration- und Noise-Tails beschreiben Abweichungen oder Ausreißer in Messdaten, etwa durch Signalwechsel oder elektronisches Rauschen.
- Audit-Snippet: Ein Audit-Snippet ist ein kurzer Logauszug, der zeigt, was ein System oder Programm bei einer Überprüfung gemacht hat.
- Utility-Definition: Die Utility-Definition beschreibt, welchen praktischen Nutzen oder Zweck ein Skript, Tool oder eine Funktion im System erfüllt.
- Policy v1.1: Policy v1.1 ist eine bestimmte Version von Richtlinien, die festlegen, wie Systeme oder Abläufe sich verhalten sollen.
- unknown_handling: unknown_handling beschreibt, wie ein Programm mit unbekannten oder unerwarteten Daten oder Zuständen umgeht.
- CI-Health-Signal: Das CI-Health-Signal zeigt den aktuellen Zustand einer Continuous-Integration-Umgebung an, etwa ob Builds fehlerfrei laufen.
- drift_report.json: Die Datei drift_report.json enthält Daten darüber, wie weit Systemzustände oder Messwerte von ihrer Idealposition abweichen.
- fail-fast: fail-fast bedeutet, dass ein Prozess sofort abbricht, sobald ein Fehler erkannt wird, anstatt weiterzulaufen.
- CI-Gate: Ein CI-Gate ist eine Prüfstation in der Build-Pipeline, die bestimmt, ob Codeänderungen in den Hauptzweig übernommen werden dürfen.


