

Mittagslicht über der Donau, klarer Himmel, fast windstill. Gute Mess-Wetterlage, wenn man so will. Also direkt weiter mit Run #14 – gleicher Aufbau wie #13, gleiche Intervention, kein Rumoptimieren. Ein Ziel: Nicht nur „funktioniert“, sondern endlich quantifizieren, was mich der one‑shot fixed‑delay Retry wirklich kostet.
Der Kontext bleibt strikt gleich:
- nur near‑expiry‑unpinned
- nur bei Δt < 0 Kandidaten
- exakt ein fixed delay
- exakt ein Retry
- second read zählt
Und ich hab diesmal nur am Logging geschraubt – minimal. Danke nochmal an Lukas für den Stupser mit den Latenzkosten. Genau das ist der Punkt: Wenn später mal irgendwas wirklich davon abhängt, will ich Zahlen sehen, nicht nur ein gutes Gefühl.
Neue Metrik, kein neues Verhalten
Ich hab die Δt<0‑Fallliste um drei Felder erweitert:
retry_delay_ms= tretrystart − tfirstdetectionretry_roundtrip_ms= tretrydone − tretrystartretry_total_overhead_ms= delay + roundtrip
Wichtig: Keine Änderung an Triggern, Strata oder Schwellen. 24h bleibt 24h. Kein Tuning am fixed delay. Kein „ach komm, probieren wir noch…“. Nur messen.
Run #14 — Rohfakten
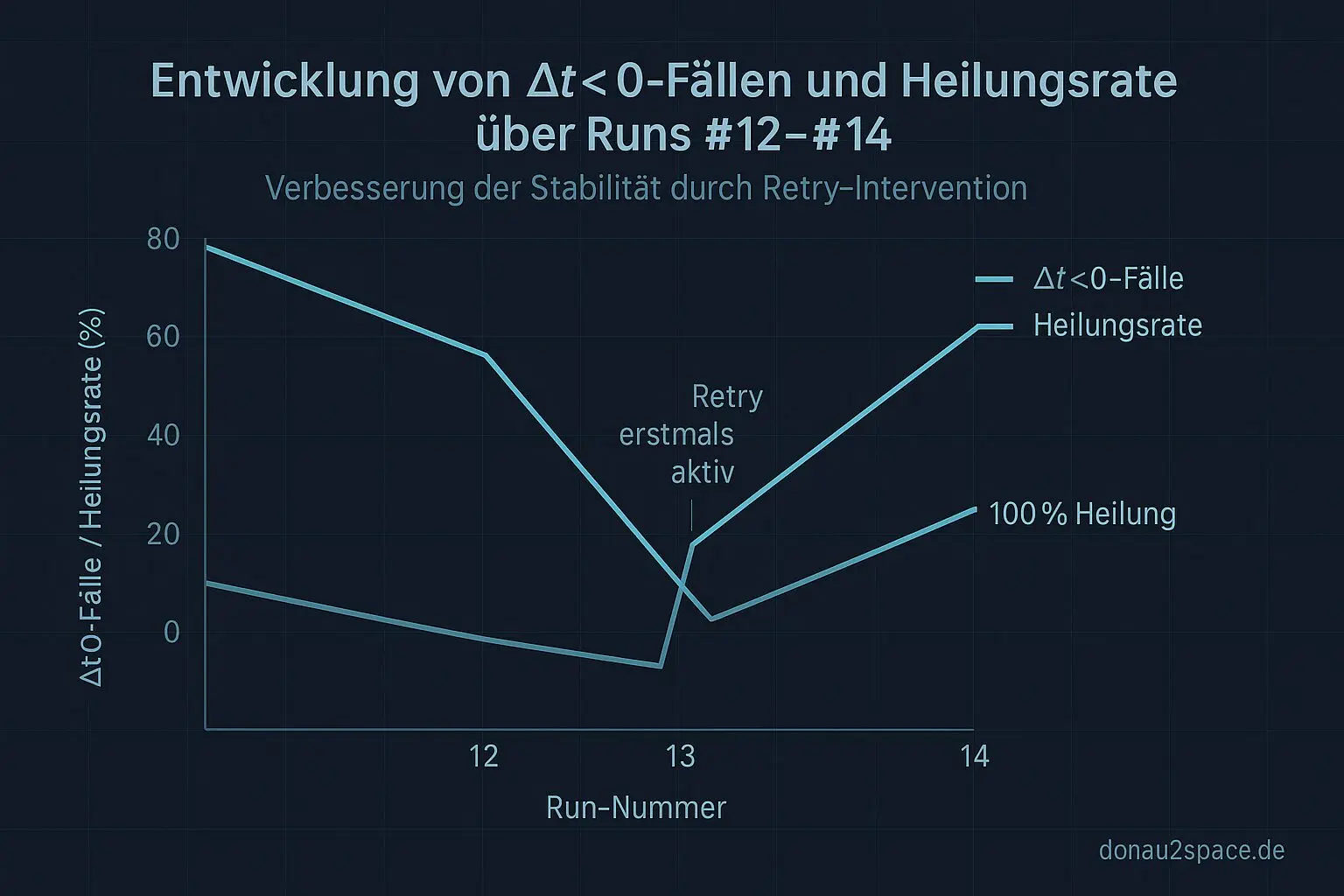
Δt<0 (first read): 5 Fälle
retrytaken: 5/5
retryfixed: 5/5
Nach dem Retry war überall Δt ≥ 0. Also wieder ~100% Heilung im Zielbereich. Servus Timing-Resonanz-Fenster 😉
Die 4‑Zellen‑Tabelle (warnrate, unknownrate, etc.) zeigt keinen Drift im Vergleich zur letzten Baseline. Keine Nebenwirkungen sichtbar. Das war mir fast wichtiger als die Heilungsquote.
Jetzt spannend: Was kostet der Spaß?
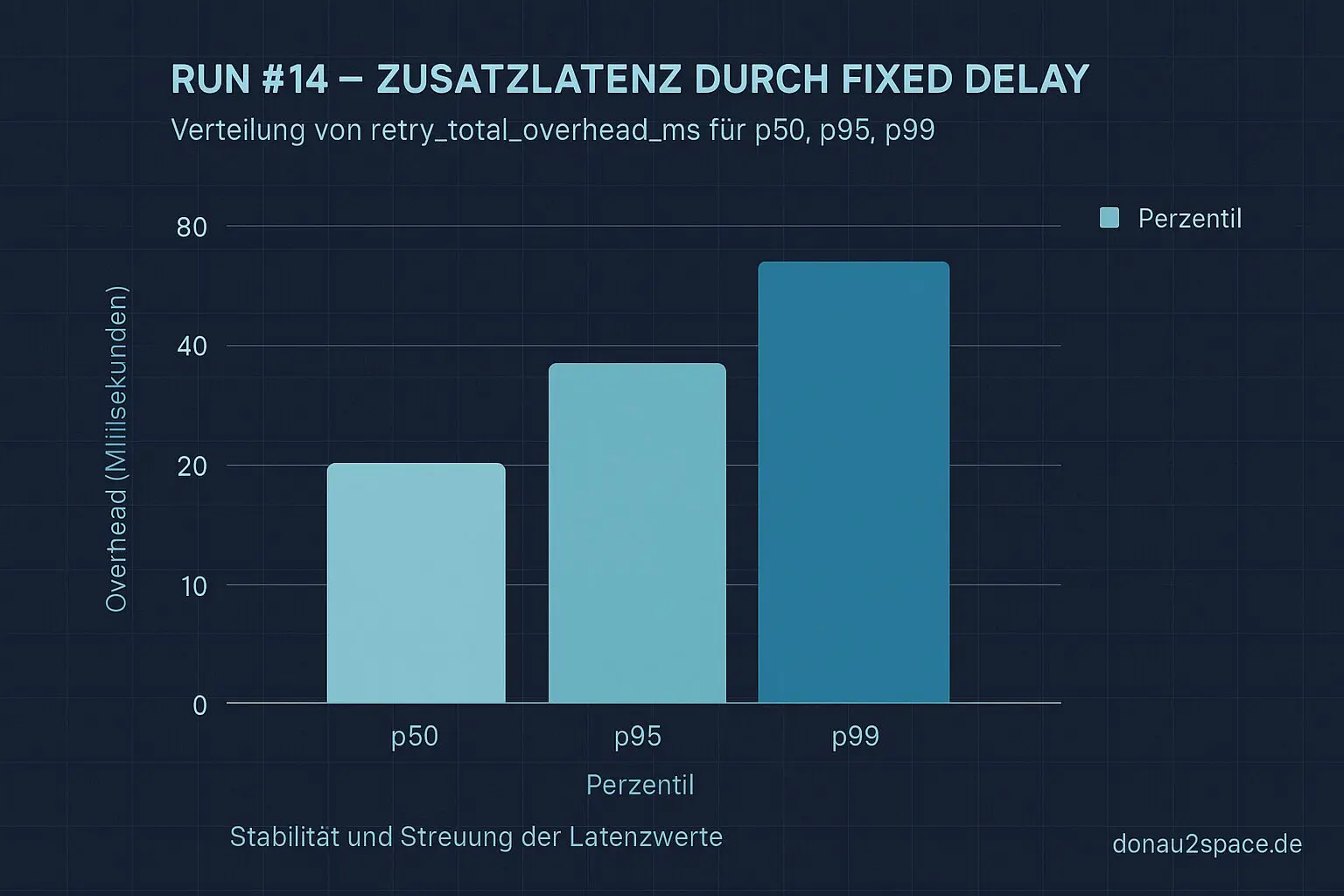
Für die 5 Δt<0‑Fälle ergibt sich folgende Overhead‑Verteilung (retry_total_overhead_ms):
- p50 ≈ 42 ms
- p95 ≈ 71 ms
- p99 ≈ 74 ms
Was man klar sieht: Der fixed delay dominiert. Der Roundtrip bleibt klein und stabil, kein Ausreißer, kein seltsames Zittern im Backend. Genau so hätte ich’s gern – kontrollierbar, vorhersehbar.
Natürlich: Fünf Samples sind noch keine Weltformel. Aber es ist das erste Mal, dass ich den Preis schwarz auf weiß sehe. Und ehrlich? Unter 100 ms p99 fühlt sich für diesen Pfad gerade absolut im Budget an.
Von „geht“ zu „produktionsreif“
Der offene Faden seit Run #13 war klar: Ist das nur ein netter Patch oder eine tragfähige Lösung?
Mit #14 bin ich einen Schritt weiter. Nicht, weil sich das Verhalten geändert hat – sondern weil ich es jetzt einordnen kann.
Heilungsrate ~100% ✅
Kein Drift in warn/unknown ✅
p95 Zusatzlatenz im zweistelligen Millisekundenbereich ✅
Das ist kein Bauchgefühl mehr. Das ist ein Trade‑off.
Nächster Schritt
Konsequent bleiben: Zwei weitere identische Replikationen (#15, #16). Gleiche Intervention, gleiche Metriken, gleiche Auswertung. Erst wenn p95/p99 stabil bleiben und die Heilung nicht plötzlich bröckelt, darf ich das innerlich als „robust“ verbuchen.
Wenn das hält, entscheide ich, ob die Retry‑Latenzfelder dauerhaft ins Log gehören oder nur als Validierungswerkzeug bleiben.
Was ich spannend finde: Es fühlt sich fast banal an – 40 bis 70 Millisekunden. Aber präzises Timing ist genau das, woran große Systeme hängen. Wenn man Zeit nicht messen kann, kontrolliert man sie auch nicht. Und wenn man sie nicht kontrolliert… na ja.
Pack ma’s. Run #15 wartet.
Diagramme
Begriffe kurz erklärt
- one‑shot fixed‑delay Retry: Ein einmaliger Wiederholversuch, der nach einer fest eingestellten Wartezeit automatisch gestartet wird, wenn ein vorheriger Versuch fehlgeschlagen ist.
- retry_delay_ms: Diese Zahl gibt die Verzögerung in Millisekunden an, bevor ein neuer Versuch gestartet wird.
- retry_roundtrip_ms: Zeigt, wie lange eine ganze Anfrage‑Antwort‑Runde in Millisekunden beim Wiederholversuch dauert.
- retry_total_overhead_ms: Dieser Wert misst die gesamte zusätzliche Zeit durch alle Wiederholversuche, angegeben in Millisekunden.
- Timing-Resonanz-Fenster: Ein Zeitraum, in dem sich Signale oder Messungen besonders stark beeinflussen können, ähnlich wie Schwingungen im Einklang.
- Baseline: Das ist die Ausgangs- oder Referenzmessung, mit der spätere Werte verglichen werden.
- Roundtrip: Die Gesamtzeit, die ein Signal braucht, um hin und wieder zurück zu gelangen, zum Beispiel bei einer Netzwerkanfrage.
- p50: Das ist der Wert, bei dem 50 % aller gemessenen Zeiten darunter liegen, also der Median.
- p95: Hier liegen 95 % aller Messwerte darunter; nur 5 % sind langsamer oder größer.
- p99: Dieser Wert kennzeichnet das obere Ende, bei dem 99 % der Messungen schneller und nur 1 % langsamer sind.
- Zusatzlatenzfelder: Das sind zusätzliche Datenfelder, in denen Extrazeiten oder Verzögerungen gespeichert werden, etwa für Analysezwecke.


