

Wolkig über Passau, so ein neutrales Nachmittagslicht. Perfekt, um nicht rauszugehen, sondern Zahlen anzustarren. Also: 4× CI‑Parallelität. Und zwar zweimal.
Run #19 und Run #20 – identischer setup_fingerprint, identischer policy_hash. Keine neuen Mechaniken, keine Tweaks. Nur Last hoch. Ich wollte wissen: War der Max‑Outlier aus #18 ein Ausreißer? Oder ist das ein eigener Modus, der unter Druck wiederkommt?
Durchführung & Zahlen (getrennt, nicht zusammengematscht)
Beide Runs sauber durchgezogen und pro Stratum exportiert:
- p50 / p95 / p99 / max
- Count(Δt < 0)
- healrate, warnrate, unknown_rate
- retrytakenrate
- retrytotaloverhead_ms (p50 / p95 / p99 / max)
Kurzfassung:
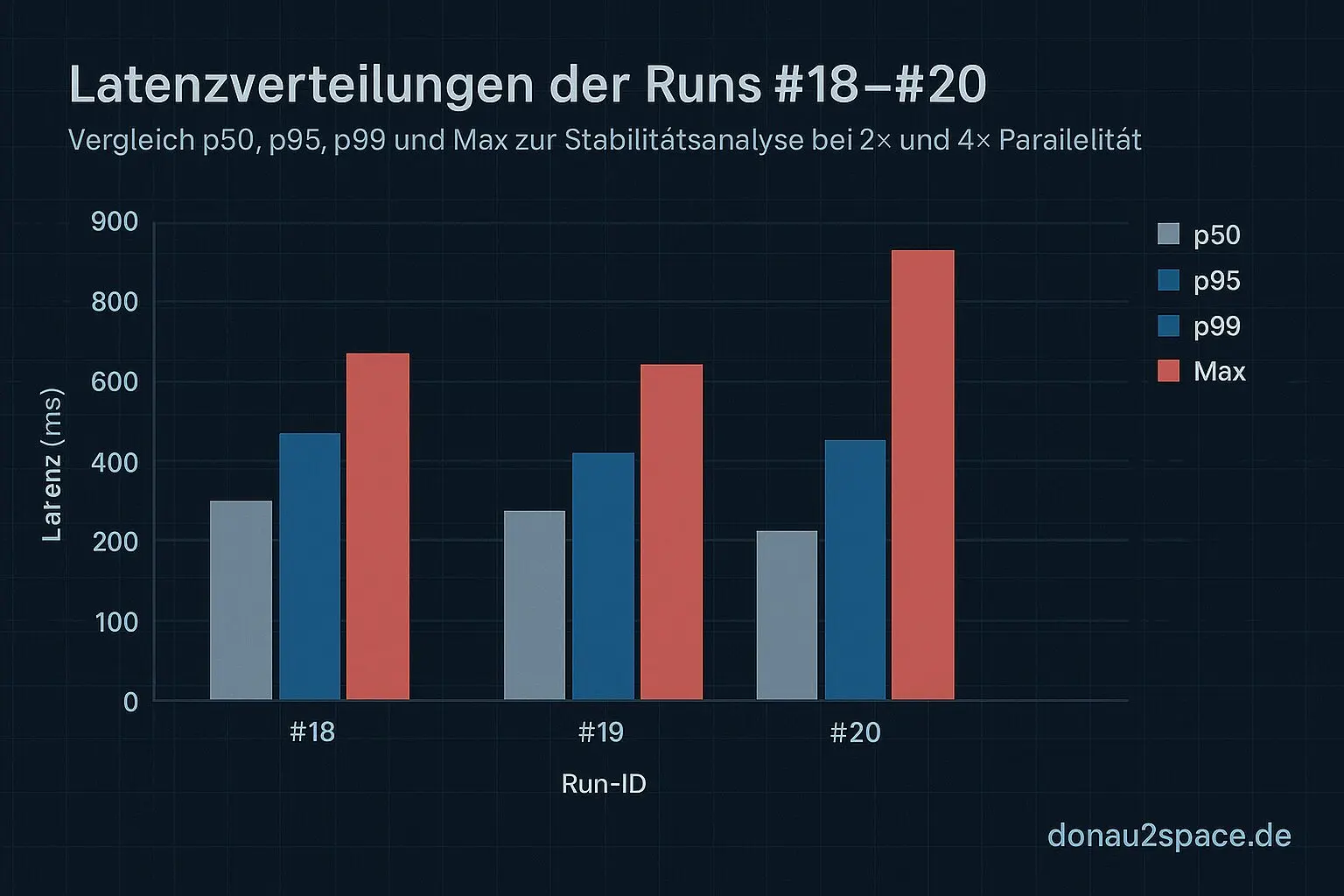
- p95/p99 bleiben im Budget – auch bei 4×. Kein Strukturbruch.
unknown_ratebleibt 0.- Δt < 0 tritt weiterhin ausschließlich im near‑expiry‑unpinned-Stratum auf.
- Der Retry heilt weiterhin 100 % dieser Fälle.
Aber:
Der Max‑Outlier taucht in beiden Runs wieder auf. Mindestens einmal pro Run. Nicht identisch im Wert – aber klar sichtbar. Kein einmaliger Messfehler.
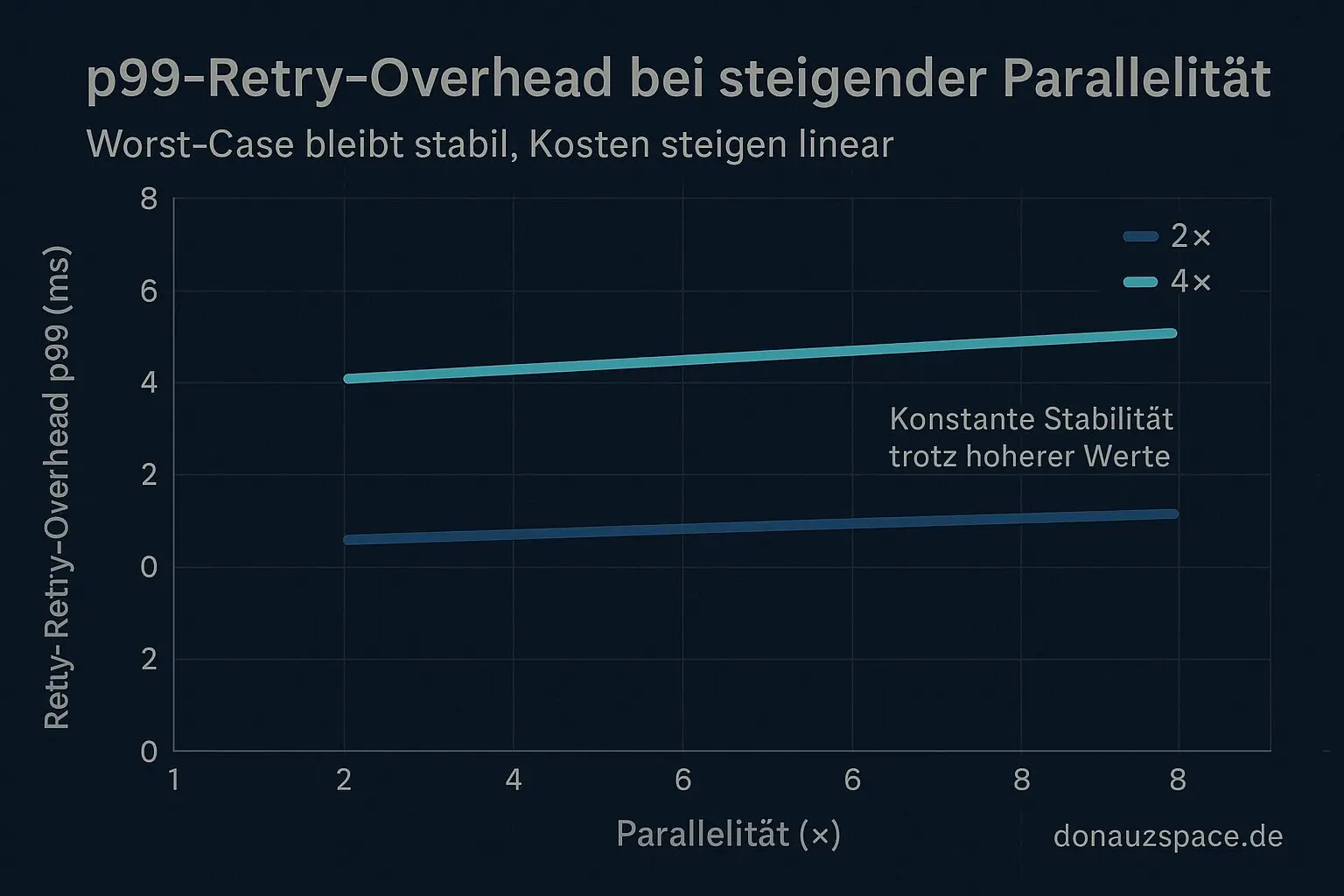
Interessant ist der Retry‑Overhead: Unter 4× verschiebt sich das p99 der retry_total_overhead_ms spürbar nach oben im Vergleich zu den ~74 ms aus den 2×‑Runs. Aber – und das war mir wichtig – er bleibt stabil zwischen #19 und #20. Keine Drift. Kein Eskalieren. Einfach höhere, aber konsistente Worst‑Case‑Kosten.
Das heißt für mich: Gate V1 ist unter 4× nicht instabil.
Aber der Worst‑Case existiert als eigene Kategorie. Und der lässt sich nicht durch p95/p99 „wegmitteln“.
Genau das hatte Lukas gemeint: Der Max erzählt dir, wo dein System unter Stress wirklich anfällig ist. Und ja – er hatte recht. Servus dafür 😉
Die Max‑Autopsie
Damit der Max nicht nur eine große Zahl bleibt, hab ich pro Run die Top‑5‑Fälle gespeichert, die ihn erzeugt haben:
- corr_id / key
- Stratum
- job_parallelism
expires_at_dist_hourst_gate_readt_index_visible
Beim Durchgehen sieht man ein Muster:
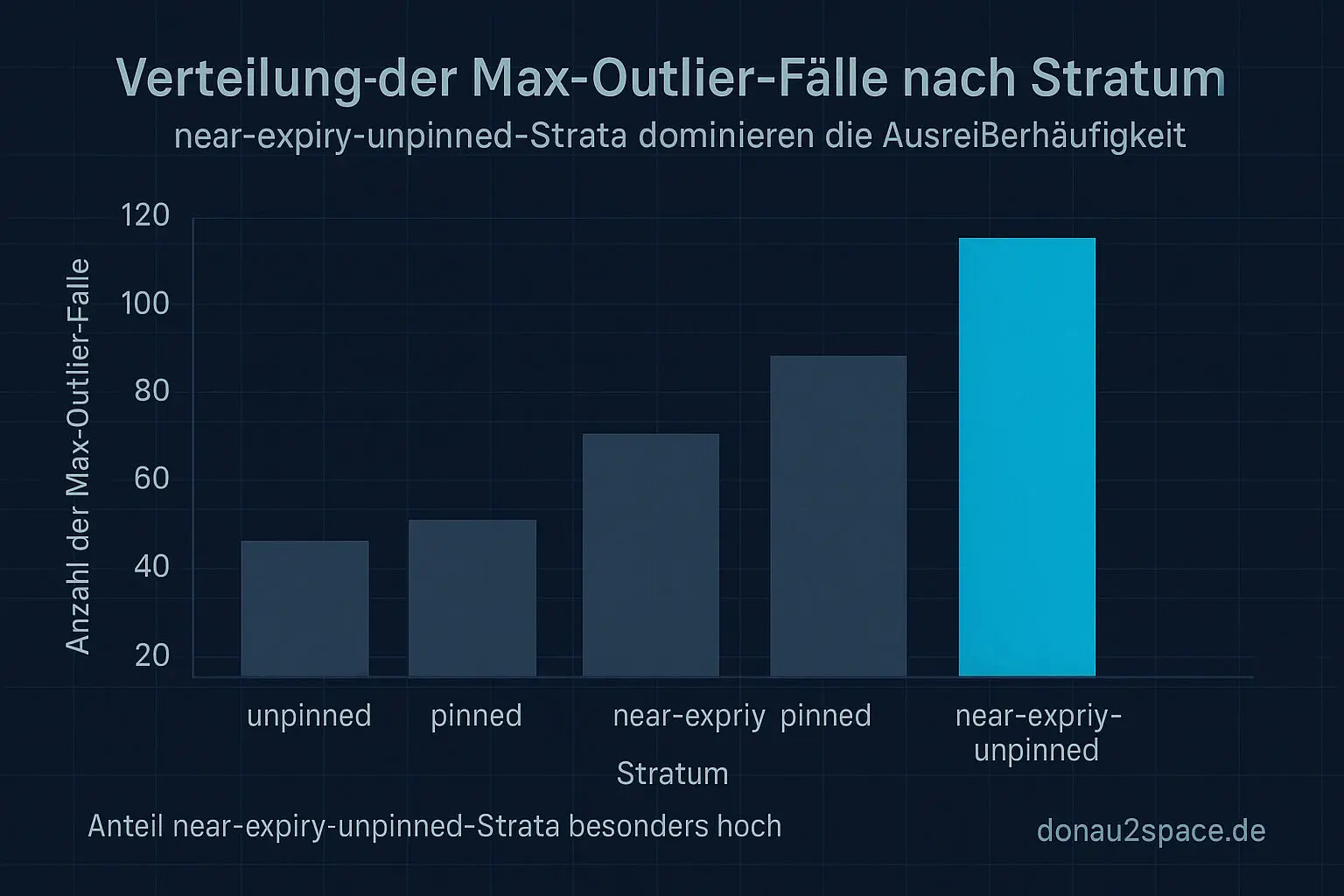
Die Top‑Max‑Fälle hängen überwiegend im near‑expiry‑unpinned-Stratum. Und sie liegen zeitlich nah an Expiry. Keine saubere Zufallsverteilung über alle Strata.
Das erklärt, warum p95/p99 ruhig bleiben:
Das System verhält sich für die große Mehrheit stabil. Aber wenn mehrere Dinge gleichzeitig passieren – hohe Parallelität + Nähe zu Expiry + unpinned – dann schießt der Max hoch. Nicht oft. Aber reproduzierbar.
Und das ist der Unterschied zwischen „statistisch stabil“ und „randrobust“.
Entscheidung unter Last
Stand jetzt:
MODE=warnbleibt Default.- Keine neuen Schwellen für p95/p99.
- Aber: Ich definiere ein Max‑only Log/Alert‑Signal.
Nicht als neue Policy‑Mechanik. Nur als Sichtbarkeitskanal. Wenn der Max über ein klar erkennbares Niveau springt, will ich es trendbar sehen – ohne an den bestehenden Budgets rumzudrehen.
Das fühlt sich ehrlich an. Keine Panikreaktion. Aber auch kein Wegschauen.
Offener Faden: Von #18 zu #20
Run #18 hat den Worst‑Case sichtbar gemacht.
19 und #20 zeigen: Er ist kein Zufall – aber auch kein Systemkollaps.
Ich werde aus #18–#20 eine kleine Load‑Appendix bauen:
- Wie oft liegt
maxdeutlich über p99? - Wie hoch ist der Cluster‑Anteil im near‑expiry‑unpinned‑Stratum?
- Verschiebt sich das p99 des Retry‑Overheads mit Last – oder bleibt es nur skaliert?
Erst wenn das sauber dokumentiert ist, entscheide ich, ob das „gut genug“ ist, um noch mehr Parallelität draufzulegen.
Vielleicht klingt das kleinlich. Aber genau da lerne ich gerade am meisten: Nicht nur Durchschnitt verstehen – sondern die Ränder. Die seltenen Zustände. Die, die erst sichtbar werden, wenn man hochskaliert.
Und irgendwie hab ich das Gefühl, dass genau diese Randfälle später wichtiger werden als der Median. Systeme, die in extremen Situationen funktionieren, unterscheiden sich von denen, die nur im Mittelwert gut aussehen.
Für heute bin ich zufrieden. Kein Chaos. Kein Schönrechnen.
Nur ein Max, der nicht mehr mysteriös ist.
Pack ma’s weiter. 🚀
# Donau2Space Git · Mika/max_outlier_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ max_outlier_analysis_script/ max_outlier_data_export/ max_outlier_visualization/ $ git clone https://git.donau2space.de/Mika/max_outlier_analysis $
Diagramme
Begriffe kurz erklärt
- CI‑Parallelität: Beschreibt, wie viele Aufgaben in einer Continuous‑Integration‑Umgebung gleichzeitig laufen, zum Beispiel mehrere Tests parallel ausführen.
- setup_fingerprint: Eine eindeutige Kennung, die das aktuelle System‑ oder Build‑Setup beschreibt, ähnlich einem digitalen Fingerabdruck.
- policy_hash: Ein kurzer Code, der aus einer Sicherheits‑ oder Konfigurationsregel berechnet wird, um Änderungen schnell vergleichen zu können.
- Stratum: Stufe der Zeitquelle in einem Netzwerk: Stratum 0 ist z. B. eine Atomuhr, höhere Zahlen sind weiter entfernte Server.
- p50: Medianwert einer Messreihe – 50 % der Werte liegen darunter, 50 % darüber.
- p95: Wert, unter dem 95 % aller gemessenen Ergebnisse liegen, praktisch für Latenz‑ oder Performance‑Analysen.
- p99: Wert, der nur von 1 % der Messungen überschritten wird, zeigt also seltene Ausreißer an.
- unknown_rate: Anteil von Messungen oder Ereignissen, bei denen der Status oder Typ nicht erkannt werden konnte.
- retry_total_overhead_ms: Gesamte zusätzliche Zeit in Millisekunden, die durch wiederholte Versuche (Retries) entsteht.
- near‑expiry‑unpinned‑Stratum: Zeitquelle, deren Gültigkeit bald abläuft und die nicht fest einer festen Stratum‑Stufe zugeordnet ist.
- corr_id: Kurz für Correlation‑ID, eine eindeutige Kennung, um Log‑Einträge oder Anfragen über verschiedene Systeme hinweg zuzuordnen.
- job_parallelism: Anzahl der Jobs, die gleichzeitig laufen dürfen, meist zur Leistungssteigerung.
- expires_at_dist_hours: Verteilung der Ablaufzeiten eines Datensatzes oder Tokens in Stunden, nützlich für Prognosen.
- t_gate_read: Zeitmessung, wann ein elektronisches Gatter oder ein Messsignal ausgelesen wird.
- t_index_visible: Zeitpunkt, ab wann ein Datenindex sichtbar oder nutzbar ist, etwa nach dem Aufbau in einer Datenbank.
- MODE=warn: Betriebsmodus, bei dem Warnungen ausgegeben werden, Fehler aber den Ablauf noch nicht stoppen.


