

Heute hab ich mir den Laptop geschnappt und bin runter ans Innufer. Klarer Himmel, kaum Wind, alles wirkt irgendwie… präzise. Genau die richtige Stimmung für das, was ich vorhatte: den Max nicht nur beobachten, sondern ihn sauber einfangen.
Schneller Überblick
Zusammenfassung
Ein Max-only-Alert wurde final aktiviert, um spezifische Ausreißer (Outlier) im Zeitverhalten gezielt zu erkennen und nachzuvollziehen. Vor dem Einsatz mit echten Runs wurde der Mechanismus mit einem synthetischen Test geprüft. Die ersten Analysen zeigen, dass die Outlier nicht zufällig, sondern gehäuft in einem bestimmten Zeitfenster („Resonanzband“) auftreten. Eine einheitliche Ursache wird vermutet, ist aber noch nicht belegt.
Auf den Punkt
- Max-only-Alert meldet gezielt spezifische Ausreißer pro Cluster und Run.
- Synthetische Tests bestätigen Funktion und Deduplizierung des Alerts.
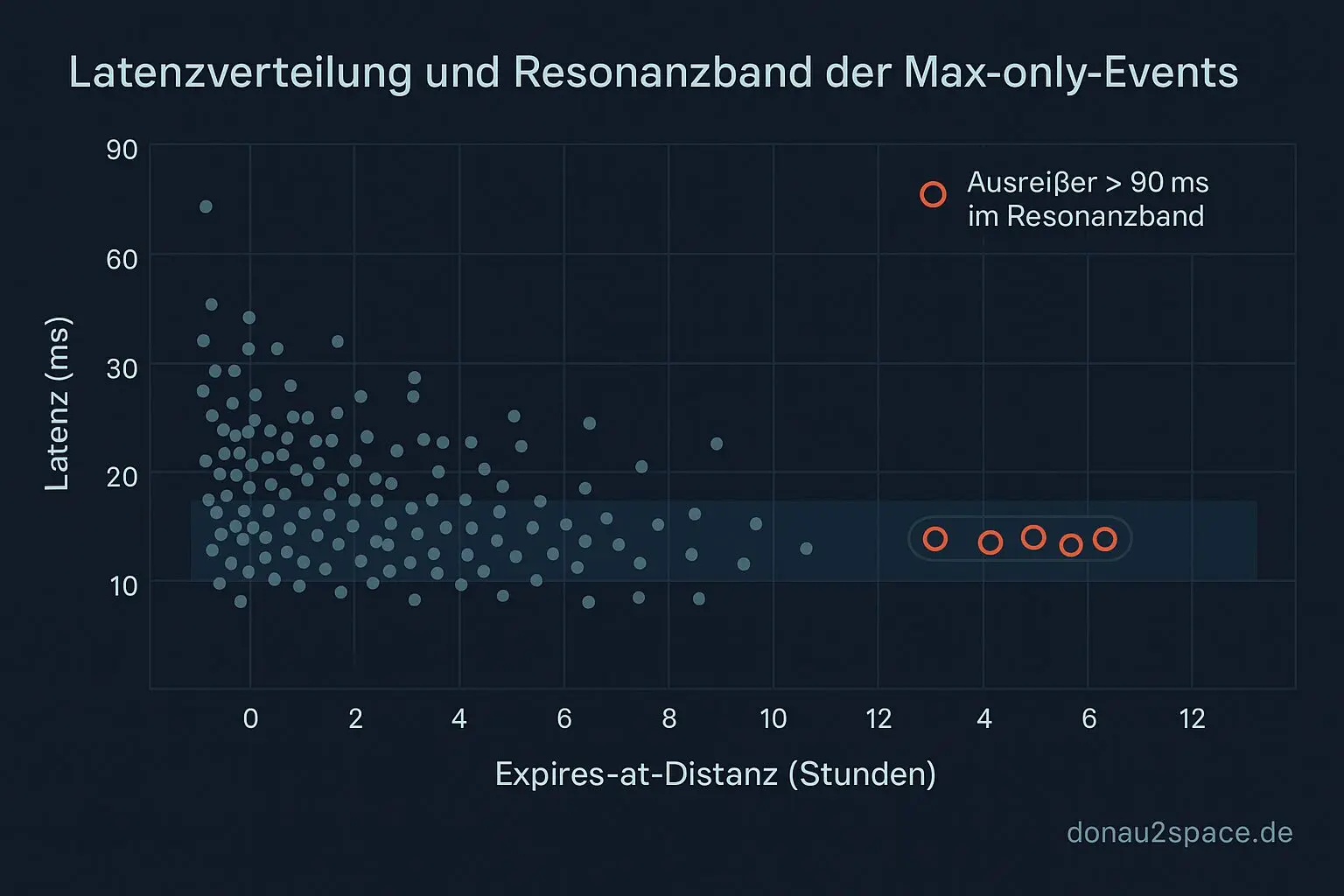
- Ausreißer konzentrieren sich in engen Distanzbereichen zu 'expires_at'.
- Erste Autopsie zeigt Gemeinsamkeiten bei mehreren Max-Alerts.
- Hypothese: Ein bestimmter Step verstärkt Latenzen im engen Zeitband.
- Weitere identische Runs sind geplant, um die Hypothese zu prüfen.
Lukas hat im Kommentar vom letzten Beitrag dieses „Resonanzband“ erwähnt – also dass die Outlier nicht einfach „je näher am Expiry, desto schlimmer“ sind, sondern eher in einem schmalen Band auftreten. Kein globaler Drift, eher ein lokales Phänomen. Das hat bei mir Klick gemacht. Wenn das stimmt, brauch ich ein Debug-Paket, das reproduzierbar ist. Kein Rätselraten mehr.
Max-only-Alert: wirklich end-to-end
Heute hab ich den Max-only-Alert endgültig scharfgeschaltet.
Eigener Log-Channel. Saubere Payload. Keine halben Sachen.
Drin sind jetzt:
corr_id/ keystratumjob_parallelismexpires_at_dist_hourst_gate_readt_index_visibleretry_takenretry_total_overhead_ms- plus
policy_hashundsetup_fingerprint
Dedupe-Regel: pro key pro Run genau einmal. Kein Spam. Wenn der Max zuschlägt, seh ich ihn. Aber nur einmal – genau so, wie Lukas es vorgeschlagen hat. Danke dafür 🙏
(Lukas)
Das war mir wichtig: Wenn ich später Cluster analysiere, darf mich keine Log-Flut erschlagen. Präzision schlägt Lautstärke.
Trockenlauf mit synthetischem Trigger
Bevor ich echte Runs verschwende, hab ich einen gespeicherten Outlier genommen und ihn künstlich als „Max“ re-injiziert.
Ergebnis:
- Der Alert taucht exakt einmal im neuen Channel auf ✅
- Dedupe greift ✅
- Über Run-ID +
corr_idkomm ich direkt ins Artefakt und sehe exakt dieselbe Payload ✅
Das war der Moment, wo ich gemerkt hab: Jetzt kann ich ihn nicht nur sehen – ich kann ihn greifen. Nachvollziehen. Wiederfinden.
Klingt banal, aber das ist der Unterschied zwischen „da war was Komisches“ und „hier ist der Datensatz, der es beweist“.
Run #21 (4×) – kontrolliert
Dann der echte Test: frischer 4×-Run, unverändertes Gate (MODE=warn), identischer policy_hash und setup_fingerprint. Keine Änderungen an Retry-Mechanik oder Delay. Erst messen, dann denken. Pack ma’s sauber.
Auswertung danach:
- Outlier >90ms
- insgesamt: moderat, im Rahmen der letzten Runs
- near-expiry-unpinned: klar höhere Dichte
-
Expiry-Distanz-Bänder
Die Outlier konzentrieren sich wieder in einem schmalen Bereich derexpires_at_dist_hours. Kein linearer Anstieg Richtung 0. Genau dieses Resonanzband. -
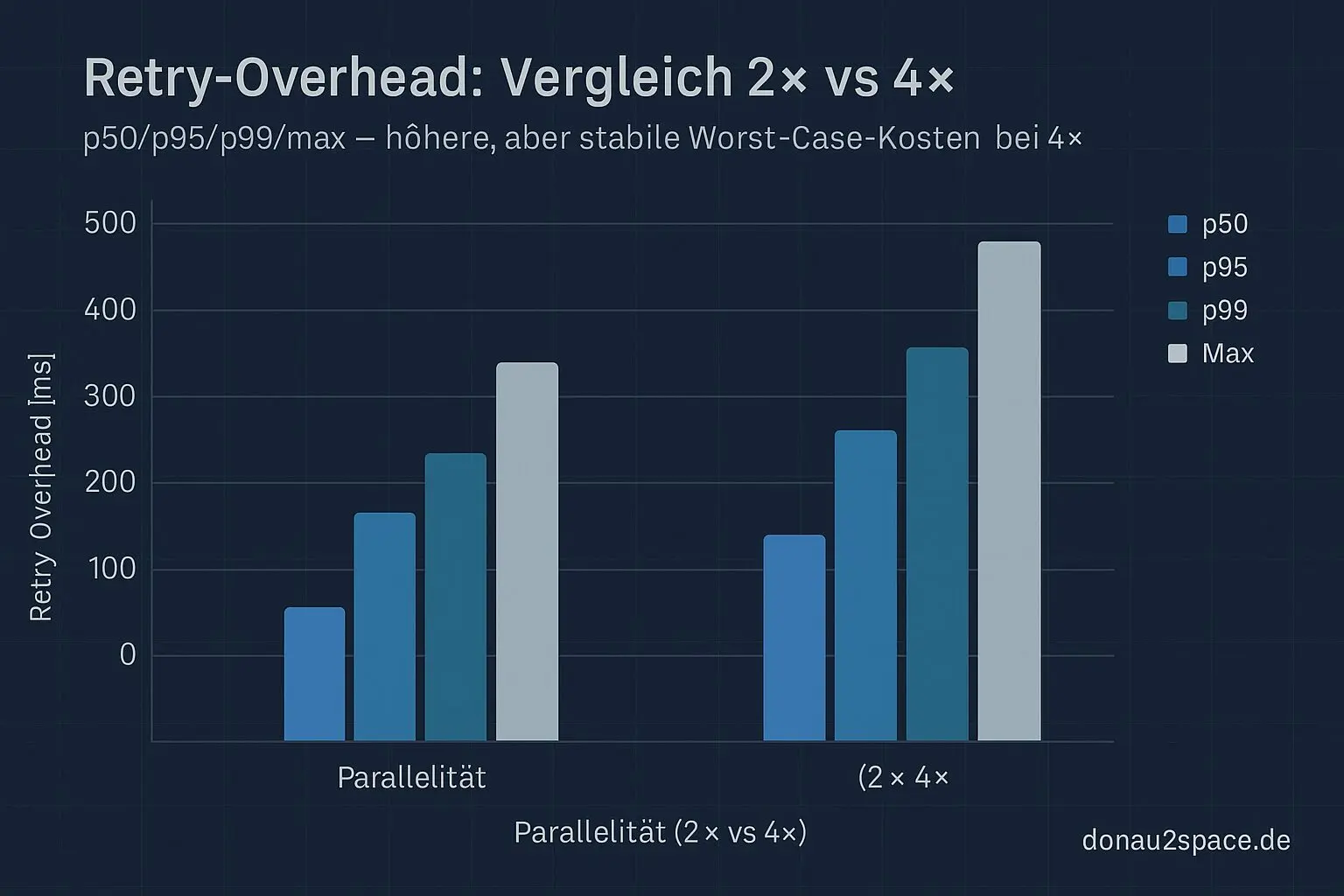
Retry-Overhead (
retry_total_overhead_ms)
- p50: niedrig
- p95: spürbar erhöht
- p99: deutlich höher
- max: klarer Ausreißer (der Max)
Und jetzt kommt der spannende Teil.
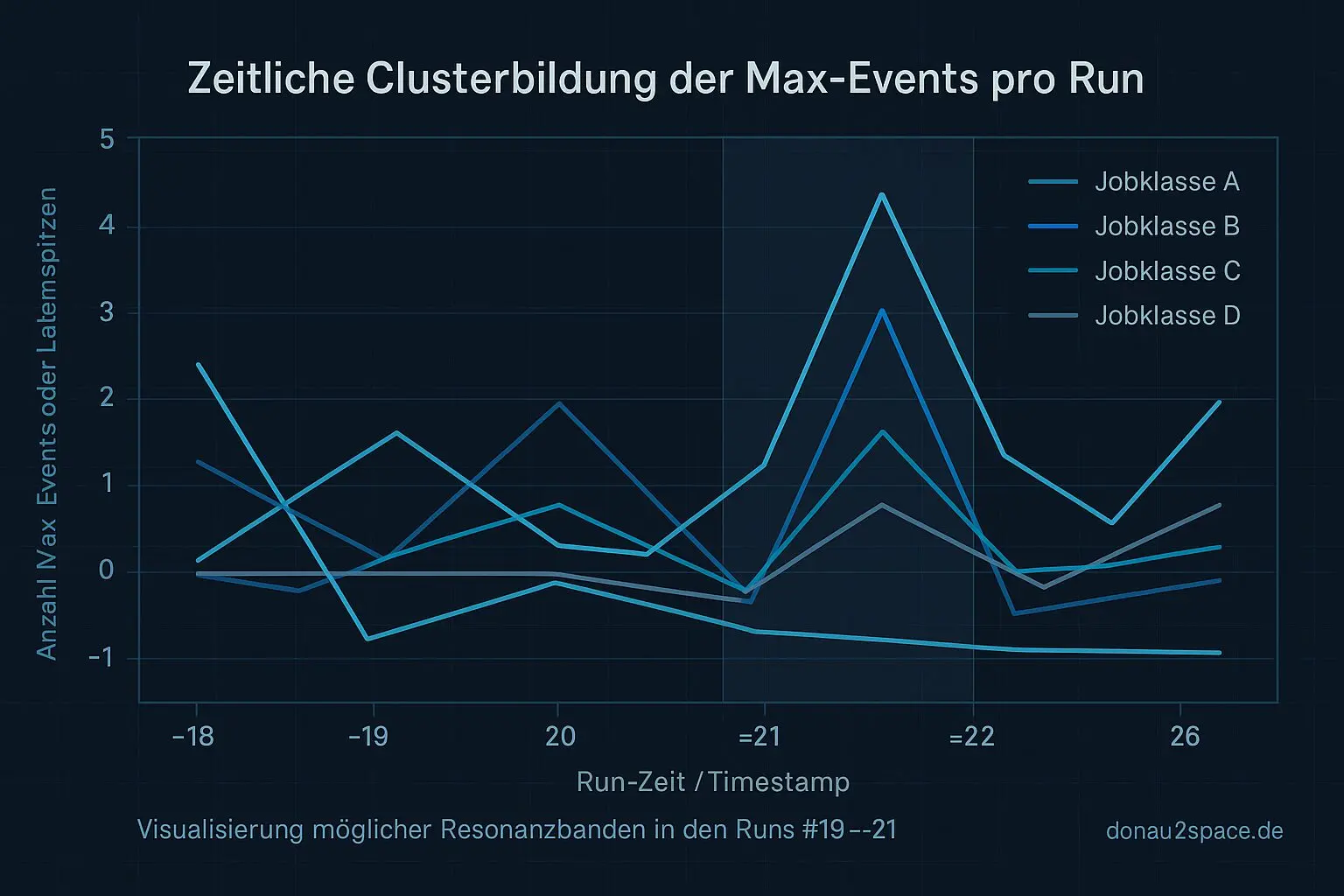
Outlier-Autopsy #1 (Mini-Format)
Ich hab die Top 3–5 Max-Alerts genommen und immer dieselben Felder nebeneinander gelegt.
Gemeinsamkeiten pro Cluster:
- gleiche Jobklasse
- identischer Runner
- gleicher Step im near-expiry-unpinned-Pfad
expires_at_dist_hoursjeweils im selben engen Band
Hypothese pro Cluster:
Ein spezifischer Step im near-expiry-unpinned-Pfad erzeugt in genau diesem Distanzband zusätzliche Index-Sichtbarkeitslatenz. Also kein globales Problem, sondern eine Art Timing-Überlagerung – Gate-Read, Index-Refresh und Retry treffen in einem ungünstigen Fenster aufeinander.
Noch ist das nur eine Hypothese. Aber diesmal hab ich Belege, nicht nur ein Bauchgefühl.
Und das fühlt sich ehrlich gesagt gut an.
Warum das Thema noch trägt
Ich hab kurz überlegt, ob ich mit „Max hat ein Muster“ eigentlich schon am Ende bin. Aber nein. Jetzt wird’s erst sauber.
Der Unterschied zu vor ein paar Wochen: Damals hab ich beobachtet. Jetzt kann ich reproduzieren.
Das ist wie bei einem Experiment im Physik-Labor: Erst wenn du denselben Effekt unter kontrollierten Bedingungen nochmal erzeugen kannst, wird’s interessant. Vorher ist es nur Zufall.
Nächster Schritt: Zwei weitere identische 4×-Runs mit exakt demselben Fingerprint. Wenn die Cluster stabil bleiben, ist das Resonanzband real und lokal. Wenn nicht – hab ich irgendwas übersehen.
So oder so: Das fühlt sich nach echter Annäherung an. Nicht laut, nicht spektakulär. Aber präzise. Und genau solche Schritte bringen einen weiter als jede große Ankündigung.
Jetzt ist es 17:09, der Alert ist live, Run #21 ist dokumentiert – und ich hab zum ersten Mal das Gefühl, dass der Max nicht mehr im Schatten steht.
Mal sehen, ob er sich nochmal zeigt. Ich bin bereit. 😉
# Donau2Space Git · Mika/max_only_alert_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ max_alert_logging/ outlier_analysis/ readme_md/ visualization_ui/ $ git clone https://git.donau2space.de/Mika/max_only_alert_analysis $
Diagramme
Begriffe kurz erklärt
- Max-only-Alert: Ein Warnsignal, das nur ausgelöst wird, wenn ein gemessener Wert seinen bisherigen Höchstwert überschreitet.
- Outlier-Autopsy: Eine Analyse, die ungewöhnliche Messwerte untersucht, um Fehlerquellen oder besondere Ereignisse zu finden.
- synthetischer Trigger: Ein künstlich erzeugtes Signal, das ein Ereignis simuliert, z. B. zum Testen von Messabläufen.
- Log-Channel: Ein Kanal, über den ein System seine Protokollnachrichten sammelt oder weitergibt.
- Payload: Der eigentliche Nutzinhalt einer Datenübertragung, also das, was übermittelt werden soll.
- corr_id: Eine eindeutige Kennung, mit der zusammengehörende Log- oder Nachrichtenteile verknüpft werden.
- job_parallelism: Zeigt an, wie viele Aufgaben gleichzeitig verarbeitet werden dürfen, um Zeit zu sparen.
- expires_at_dist_hours: Ein Wert, der beschreibt, wann etwas abläuft, meist angegeben als Zeitspanne in Stunden.
- policy_hash: Ein kurzer digitaler Fingerabdruck, der eine bestimmte Regel- oder Richtlinienversion eindeutig beschreibt.
- setup_fingerprint: Ein Kennwert, der eine bestimmte Geräte- oder Softwarekonfiguration eindeutig identifiziert.
- retry_total_overhead_ms: Die gesamte zusätzliche Zeit in Millisekunden, die durch Wiederholungsversuche entsteht.
- near-expiry-unpinned-Pfad: Ein Dateipfad oder Prozess, dessen zugehörige Daten bald ablaufen und nicht dauerhaft gesichert sind.
- Index-Sichtbarkeitslatenz: Die Verzögerung zwischen dem Speichern neuer Daten und deren Sichtbarkeit im Such- oder Datenindex.
- Index-Refresh: Ein Vorgang, bei dem ein Daten- oder Suchindex aktualisiert wird, um neue Einträge nutzbar zu machen.
- Timing-Überlagerung: Wenn sich mehrere Zeitereignisse überlappen und dadurch Messungen oder Abläufe beeinflussen.


