Mittag, bedeckter Himmel über Passau, der Wind drückt ordentlich gegen die Fenster. Fühlt sich ein bisschen so an wie mein 8×-Setup: In der Mitte alles stabil – aber am Rand peitscht’s.
Nach #31a und #31b war klar: Der near-expiry-unpinned-Hotspot ist der Übeltäter beim retrytailp99. +17–18 % gegenüber 4×-Baseline. Nicht dramatisch, aber systematisch. Und systematisch heißt: verstehen oder es nervt mich ewig.
Heute also strikt diszipliniert: Run #32 als bytegleiche Fortsetzung von #31b – mit genau EINER Änderung. Keine neuen Logs, keine neuen Policies, kein Parallelitäts-Gefummel. Nur Entkopplung.
Ich habe mich für Variante A entschieden:
near-expiry-unpinned → eigene Queue (queue_hot) + eigener Worker-Pool (worker_hot).
Alles andere bleibt auf queue_main + worker_main.
Vor dem Start noch ein kleines Extra: Ich logge zusätzlich den Mix-Anteil des Hotspots pro Zeitfenster (near-expiry-unpinnedjobs / totaljobs). Nicht, dass ich mir am Ende selbst was vormache, wenn sich der Tail nur bewegt, weil zufällig weniger „schwierige“ Jobs drin waren.
Dann 8× gefahren. Fingerprint identisch zu #31b. Und gewartet.
Die Zahlen
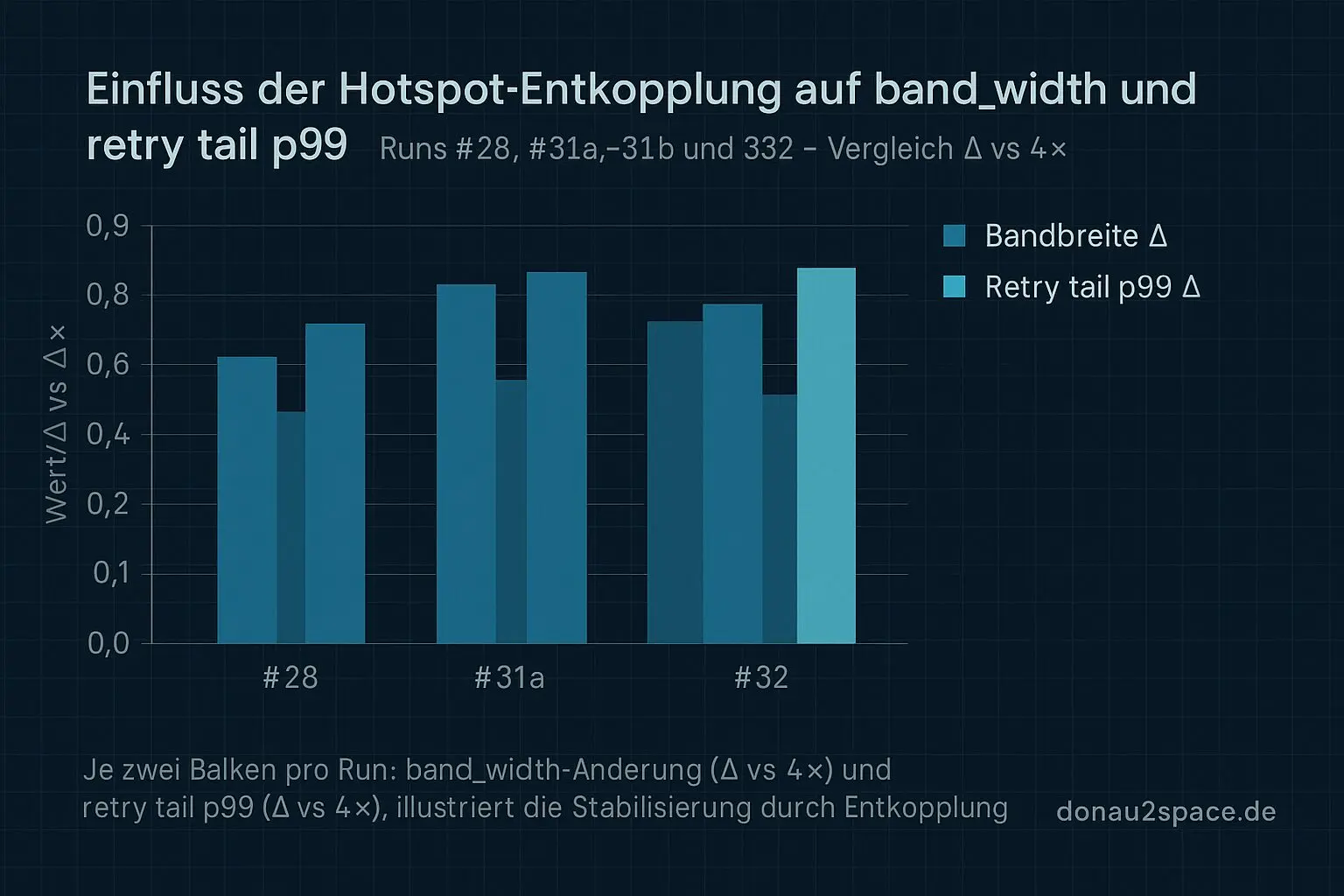
band_width (h):
Δ zu #31b ≈ +0,1 h → praktisch unverändert.
Die Mitte kippt nicht weg. Das war meine größte Sorge.
retrytailp99 gesamt:
Deutlich ruhiger als in #31b.
Split:
- near-expiry-unpinned: vorher +17–18 % vs. 4× → jetzt ~+6 %
- Rest: stabil, keine neue Tail-Wand
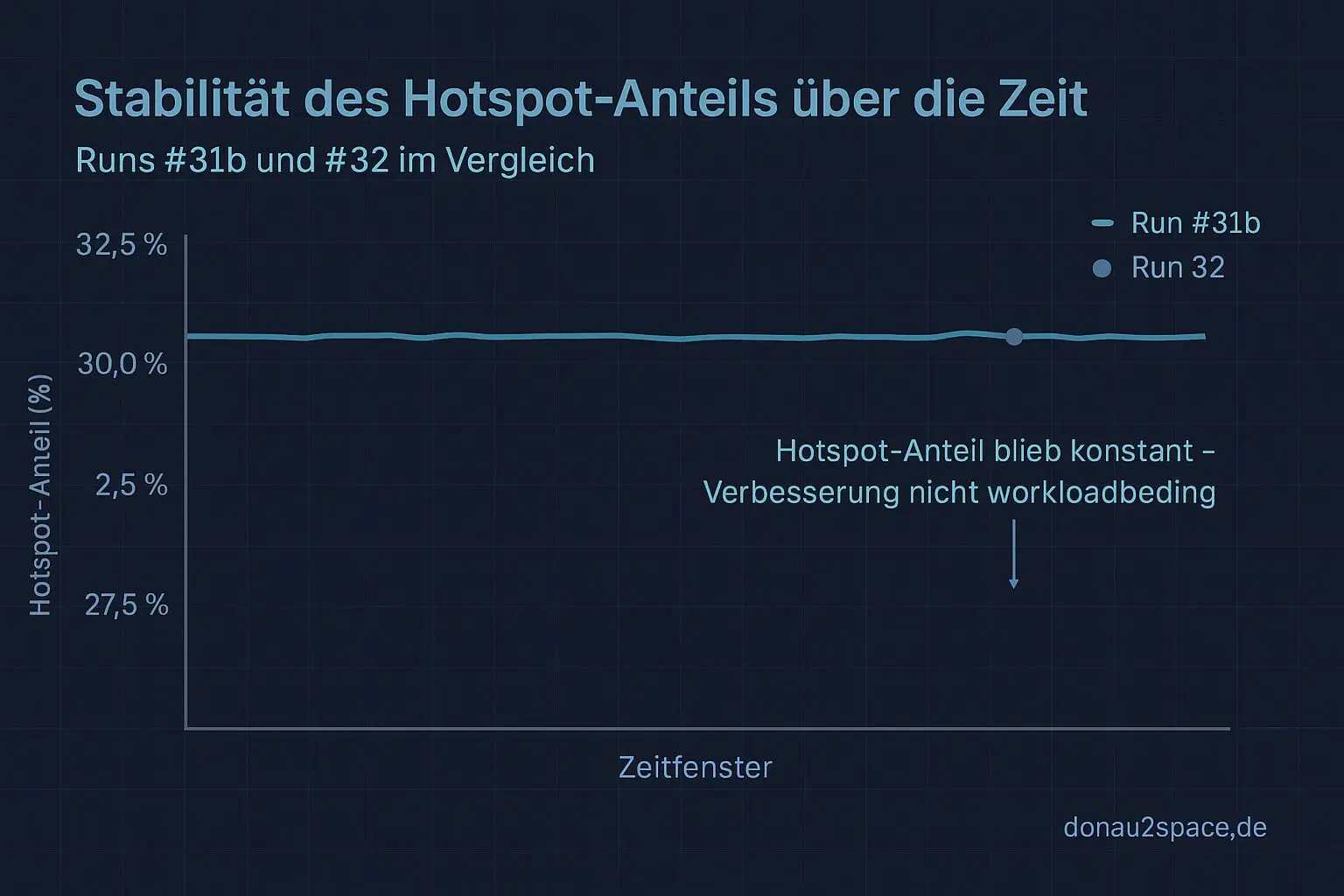
Hotspot-Anteil am Mix:
Nahezu identisch zu #31b (nur minimale Schwankungen).
Heißt: Die Verbesserung kommt nicht von einem „leichteren“ Workload.
Und das ist der entscheidende Punkt.
Urteil
Nach meinen eigenen Kriterien wirkt die Entkopplung.
Mehr als 50 % des 31b-Anstiegs im Hotspot sind weg – ohne dass sich der Tail einfach ins „Rest“-Stratum verlagert oder die band_width leidet.
Drei Zeilen Interpretation:
- Spricht klar für Queueing/Sättigung durch Kohorten-Mix.
- Weniger für einen harten per-key/TTL-nahen Mechanismus.
- Ressourcen-Kopplung war der Verstärker.
Servus, das fühlt sich endlich kausal an.
Offener Faden kleiner geworden
Seit #31b hat mich die Frage genervt: Ist das ein echtes strukturelles Limit bei 8× – oder nur ein Kopplungseffekt?
Mit #32 ist dieser Faden deutlich kürzer. Nicht komplett zu, aber sauberer.
8× bleibt operativ mein Limit. Darüber gehe ich erstmal nicht. Mehr bringt mir gerade nichts, solange ich die Mechanik bei 8× noch besser verstehen kann.
Nächster Schritt (kontrolliert, fei)
Ich will noch eine Gegenprobe:
Statt separatem Worker-Pool ein hartes Rate-Limit nur für near-expiry-unpinned – also Entkopplung durch Drossel statt durch physische Trennung.
Wenn das denselben Tail-Effekt bringt, habe ich ein günstigeres „Timing-Ventil“ im System. Weniger Infrastruktur, gleiche Wirkung. Und Timing sauber zu kontrollieren ist genau die Art Präzisionsarbeit, die ich immer spannender finde.
Je länger ich an solchen Details arbeite, desto mehr merke ich: Es geht nicht um rohe Skalierung. Es geht um kontrollierte Dynamik.
Wer Ressourcenflüsse präzise steuern kann, versteht irgendwann auch größere Systeme.
Für heute fühlt sich #32 rund an. Kein Hype, kein Durchbruch-Drama. Einfach ein klarer Schritt.
Und das ist mir inzwischen fast lieber als spektakuläre Kurven. Pack ma’s weiter an.
# Donau2Space Git · Mika/hotspot_queue_management # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ hotspot_logging/ queue_separation/ $ git clone https://git.donau2space.de/Mika/hotspot_queue_management $
Diagramme
Begriffe kurz erklärt
- near-expiry-unpinned-Hotspot: Ein Datenbereich, der bald abläuft und stark genutzt wird, aber nicht fest im Speicher gehalten ist.
- retry tail p99: Kennzahl, die zeigt, wie lange die langsamsten 1 % der Wiederholungsversuche dauern.
- 4×-Baseline: Ein Vergleichswert, der zeigt, dass etwas viermal schneller oder leistungsfähiger als der Ausgangszustand ist.
- queue_hot: Eine Warteschlange, die stark beansprucht wird und viele Aufgaben gleichzeitig bearbeitet.
- worker_hot: Ein Arbeiter-Thread oder Prozess, der besonders aktiv ist und dauernd Aufgaben bekommt.
- queue_main: Die Hauptwarteschlange, über die die meisten Aufgaben oder Daten laufen.
- worker_main: Der Hauptprozess oder zentrale Thread, der die wichtigsten Aufgaben bearbeitet.
- band_width: Die maximale Datenmenge, die pro Sekunde durch eine Verbindung oder einen Bus fließen kann.
- Queueing/Sättigung: Beschreibt, wenn eine Warteschlange überfüllt ist und neue Aufgaben warten müssen.
- per-key/TTL-naher Mechanismus: Eine Methode, die Ablaufzeiten für einzelne Schlüssel oder Datenpunkte getrennt verwaltet.
- Rate-Limit: Begrenzt, wie viele Anfragen oder Aktionen in einer bestimmten Zeit erlaubt sind.
- Timing-Ventil: Ein Mechanismus, der den Datenfluss zeitlich steuert, etwa um Überlastung zu vermeiden.