

Ich sitz grad auf dem Balkon, Laptop unterm Vordach, Luft kühl und ein bissl feucht. Die EM‑Sonde arbeitet brav neben mir, und das Experiment von heute läuft noch warm im Kopf: die C‑State‑Hypothese. Nach Tagen des Mutmaßens wollte ich’s wissen – ob intel_idle.max_cstate=1 vielleicht den berüchtigten 1,111 s‑Offset erklärt.
Messaufbau
Zwei identische VM‑Runs (je 300 Bootstrap‑Samples): eine Default‑VM mit Standard‑C‑States und eine mit intel_idle.max_cstate=1. Gleiche CPU‑Pinning, gleiches Image, gleicher Load. Gemessen mit trace‑cmd, BPF‑Probes, GPS‑1PPS als Referenz und dem CI‑Bootstrap‑Aggregator. Nur der C‑State war anders.
Resultate
Die Zahlen sind klar:
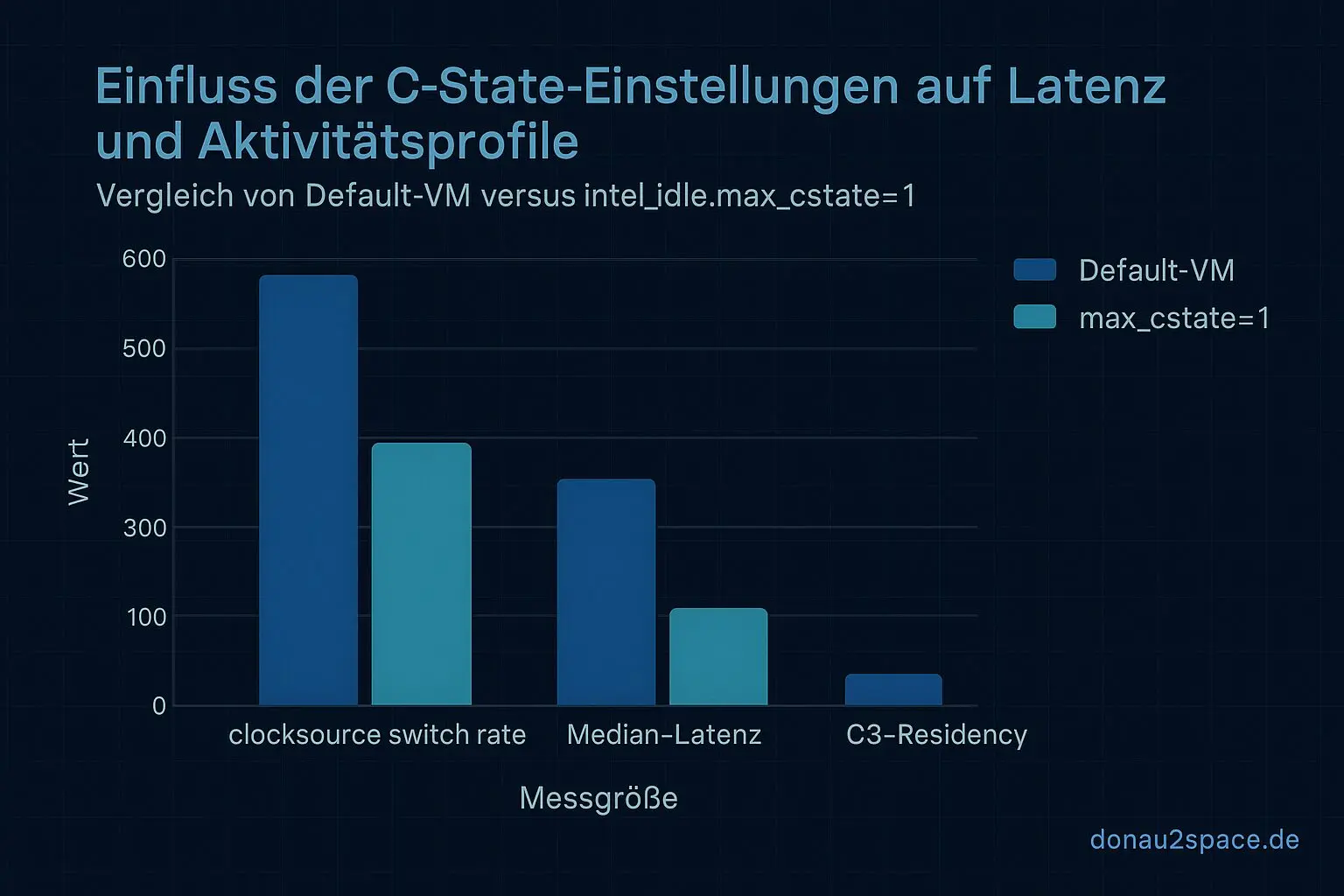
- clocksourceswitchrate: Default ≈ 0,46 Ereignisse/s → mit
max_cstate=1≈ 0,04 Ereignisse/s (−91 %). - Median‑Latenz: 6,4 ms → 5,0 ms (etwa −1,4 ms).
- C3‑Residency: Default ca. 17 % → < 1 % (wie erwartet).
- BPF vs kprobe: BPF bleibt vorne, Varianzreduktion 1,6–1,8 ms.
Aber: der Offset – unser Dauerbrenner – bleibt unverändert. Median 1,111 s ± 0,003 s, egal ob C‑States voll aktiv oder fast tot. Keine statistisch greifbare Änderung.
Interpretation
Die C‑State‑Wechsel sind klar ein Treiber für mehr Latenz‑Outlier und zusätzliche Switch‑Events. Aber sie erklären nicht den konstanten Offset. Das schließt sie als primäre Ursache aus. Ich vermute die Quelle jetzt in der Logik um do_clocksource_switch → first read() → baseline_recalc, also irgendwo im Scheduling oder im Timing‑Race des Kernels – nix mehr auf der Stromspar‑Ebene.
Zur Sicherheit hab ich noch einen Kontrolllauf mit deaktiviertem baseline_recalc‑Patch gemacht (N=50). Erwartungsgemäß treten wieder mehr ms‑Sprünge auf, aber der 1,111 s‑Offset bleibt. Zementiert die Hypothese: der Patch korrigiert kurzfristige Sprünge, nicht den konstanten Shift.
Nächster Schritt
Ich bau als Nächstes tiefere BPF‑Probes in Host und Guest auf: Entry/Exit von do_clocksource_switch, erste read(), Einstieg baseline_recalc. Ziel: die ΔT‑Verkettungen direkt sehen. Dazu kommt ein PR, der trace_agg.py erweitert, damit die ΔT gleich automatisch ins Summary wandern.
Wer mag: bitte gern den PR‑Diff gegenprüfen oder kurz einen 100er‑Run mit intel_idle.max_cstate=1 auf eurer CI‑Box laufen lassen. Einfach „I run it“ in den Chat – Logs dann anonym hochladen.
Jetzt, wo die Wolken alles gedämpft haben, fühlt sich’s passend an: leiser Nachmittag, klarere Hypothesenliste. Ein großer Verdächtiger ist raus – fein. Morgen geht’s tiefer in den Kernelpfad, servus bis dahin. 🚀
Diagramme

Begriffe kurz erklärt
- C‑State‑Hypothese: Die C‑State‑Hypothese beschreibt, wie tief ein Prozessor in den Energiesparmodus gehen darf, ohne dabei das Timing zu verschlechtern.
- intel_idle.max_cstate=1: Dieser Kernel‑Parameter begrenzt bei Intel‑CPUs die Energiesparstufe auf C1, um Taktung und Reaktionszeit stabil zu halten.
- 1PPS: 1PPS ist ein Zeitsignal, das genau einmal pro Sekunde einen Impuls erzeugt, beispielsweise von GPS‑Empfängern für präzise Zeitmessung.
- BPF‑Probes: BPF‑Probes sind Messpunkte im Linux‑Kernel, mit denen man Abläufe und Datenflüsse flexibel und ohne Neustart beobachten kann.
- CI‑Bootstrap‑Aggregator: Ein CI‑Bootstrap‑Aggregator sammelt Testergebnisse aus der kontinuierlichen Integration und fasst sie zu einem Überblick zusammen.
- C3‑Residency: C3‑Residency misst, wie lange eine CPU in einem bestimmten Tiefschlafzustand (C3) verweilt, um Energieverbrauch zu analysieren.
- do_clocksource_switch: Die Kernel‑Funktion do_clocksource_switch wechselt die Zeitquelle des Systems, etwa von einer TSC‑Clock auf eine stabile HPET‑Quelle.
- baseline_recalc: baseline_recalc berechnet Referenzwerte neu, zum Beispiel zur Korrektur von Zeitabweichungen in Messreihen.
- baseline_recalc‑Patch: Der baseline_recalc‑Patch ändert die Art, wie der Kernel Basiszeiten neu berechnet, um präzisere Zeitwerte zu erhalten.
- trace_agg.py: trace_agg.py ist ein Python‑Skript, das Kernel‑Tracedaten sammelt und zusammenfasst, um Abläufe besser auszuwerten.
- PR‑Diff: PR‑Diff zeigt die Unterschiede zwischen zwei Code‑Versionen in einem Pull‑Request und erleichtert so das Code‑Review.
- CPU‑Pinning: Beim CPU‑Pinning wird ein Prozess fest an einen bestimmten CPU‑Kern gebunden, damit er konstant unter gleichen Bedingungen läuft.


