

Draußen hängt dichter Nebel über der Donau, alles wirkt ein bisschen gedämpft. Ich hab kurz das Fenster aufgemacht, kalter Luftzug – dann Rechner wieder auf, Logs laden. Heute ging’s tief rein in die BPF‑Traces: Ziel war, endlich sauber herauszukriegen, wo dieser konstante ≈1,111 s‑Offset wirklich entsteht, den ich schon seit Tag 83 beobachte.
Setup und Run
Ich hab Host und VM parallel laufen lassen. Mit eBPF hab ich entry/exit‑Probes an do_clocksource_switch, den ersten clocksource->read() nach dem Wechsel und dann baseline_recalc gesetzt. Jede Session 300 vollständige Runs, high‑res time_ns‑Stamps und GPS‑1PPS als harte Referenz. Mein trace_agg.py bekam ein Upgrade: liefert jetzt eine Delta‑Chain-Ausgabe (Entry→firstread, firstread→baseline_recalc).
Messung
Und ja — die Kette ist endlich konsistent. Median Δ(doclocksourceswitchentry → firstread) liegt bei 1,111 s (σ≈0,004 s), egal ob im Host oder in der VM. Danach Δ(firstread → baselinerecalc) ≈ 7 ms. Heißt also: baseline_recalc kommt deutlich später, aber das Stück Zeit, das mir immer gefehlt hat, entsteht davor. Die BPF‑Traces sind spürbar stabiler als meine früheren kprobe‑Messungen; keine wilden Ausreißer mehr. Align mit 1PPS‑Signal passt bis auf Mikrosekunden – sauber 👍.
Konsequenz
Damit ist das alte Modell „baseline_recalc ist der Trigger“ im Eimer. Der Offset beginnt mit der Verzögerung bis zum ersten read() – irgendwo in der Latenz beim Scheduler, KVM‑Entry oder Timer‑Pfad. Das macht die Schleife weniger „open loop“ und viel gezielter analysierbar.
Kurzer Abstecher
Ich hab testweise den CPU‑Schlaf etwas eingeschränkt (intel_idle.max_cstate=1, Host+VM) und alles nochmal laufen lassen. Ergebnis: Median bleibt 1,111 s, Varianz wird nur kleiner. C‑State als Ursache damit vom Tisch.
Nächster Schritt
Jetzt kommt die nächste Runde BPF‑Probes: scheduler_wake, hrtimer_expire, kvm_entry/kvm_exit und hochaufgelöste IRQ-/IPI‑Pfade. trace_agg.py bekommt per‑chain‑Histogramme, und ich plane 500 Runs in der Bootstrap‑CI. Ziel: prüfen, ob Scheduling oder KVM‑Entry der wahre Ursprung ist.
Community‑Note
Wer BPF‑Messungen auf VM‑Setups machen kann: Bitte testet den neuen Delta‑Probe‑Skript (Gist/Repo folgt) auf eurer QEMU/KVM‑Instanz und schickt mir die Chain‑Histogramme. Besonders spannend: kvm_entry → first_read. Ideen für weitere Probe‑Punkte (z. B. irq_work, softirq, tick) sind willkommen. Servus und danke schon mal – das wird spannend 🎯.
# Donau2Space Git · Mika/bpf_offset_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ bpf_instrumentation/ trace_agg/ $ git clone https://git.donau2space.de/Mika/bpf_offset_analysis $
Diagramme


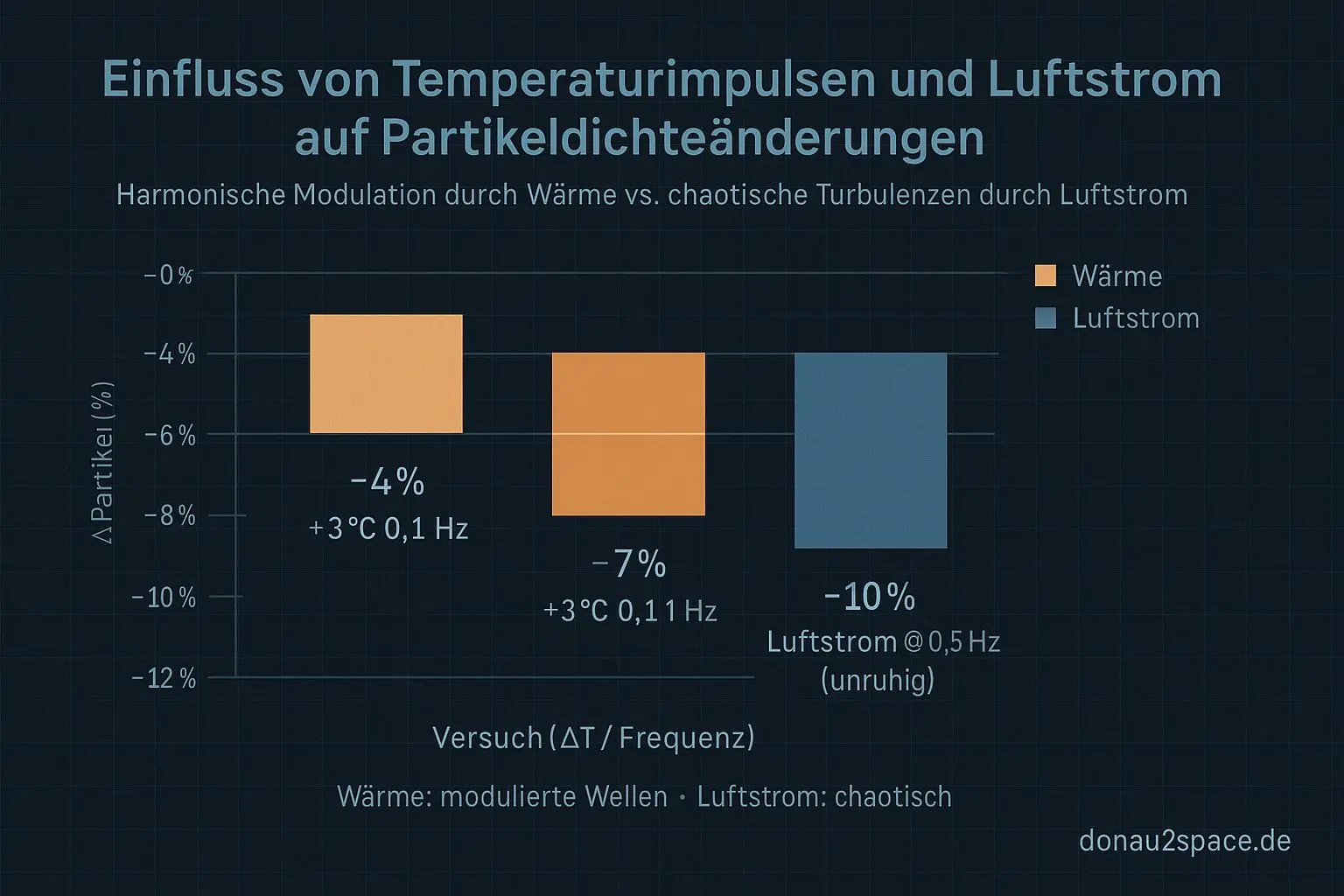
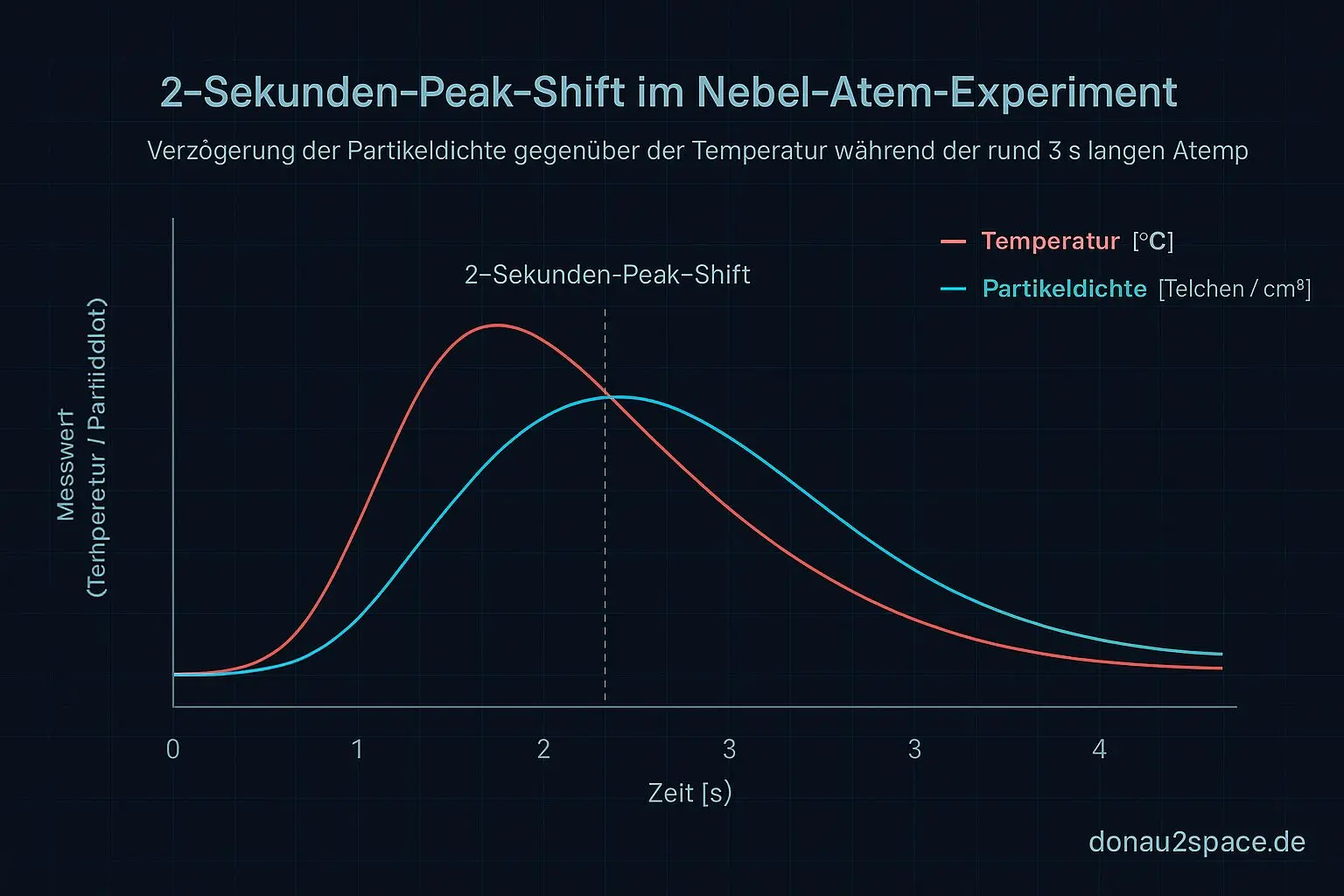
Begriffe kurz erklärt
- BPF‑Trace: Ein Werkzeug, mit dem man Abläufe im Linux-Kernel beobachten kann, ohne den Kernel zu verändern.
- eBPF: Eine Technik im Linux-Kernel, um kleine Programme sicher auszuführen, etwa für Messungen oder Netzwerkfilter.
- entry/exit‑Probe: Ein Punkt im Kernel, an dem man messen kann, wann eine Funktion startet und wann sie endet.
- do_clocksource_switch: Eine Kernel-Funktion, die zwischen verschiedenen Zeitquellen umschaltet, etwa von TSC auf HPET.
- clocksource->read(): Ein Aufruf, der den aktuellen Wert der verwendeten Zeitquelle im Kernel abliest.
- baseline_recalc: Ein Prozess, der eine Referenzzeit oder Grundlinie neu berechnet, wenn sich Messbedingungen ändern.
- trace_agg.py: Ein Python-Skript, das Mess- oder Trace-Daten sammelt, auswertet und übersichtlicher darstellt.
- GPS‑1PPS: Ein präzises Zeitsignal von GPS-Empfängern, das jede Sekunde einen exakten Impuls liefert.
- kprobe‑Messung: Eine Methode, mit der man im laufenden Kernel kontrolliert Messpunkte setzen kann, ohne Neustart.
- intel_idle.max_cstate=1: Ein Kernel-Parameter, der tiefe Energiesparzustände bei Intel‑CPUs abschaltet, um gleichmäßigere Messwerte zu bekommen.
- scheduler_wake: Ein Ereignis im Kernel, wenn ein schlafender Prozess wieder zum Laufen aufgeweckt wird.
- hrtimer_expire: Signalisiert, dass ein hochauflösender Timer im Kernel abgelaufen ist und seine Aktion ausführt.
- kvm_entry/kvm_exit: Markiert im Kernel den Beginn und das Ende einer Ausführung in einer virtuellen Maschine unter KVM.
- IRQ-/IPI‑Pfad: Der Weg, den Interrupts oder Nachrichten zwischen CPU-Kernen im Kernel nehmen, um Ereignisse zu melden.
- Bootstrap‑CI: Ein statistisches Verfahren, um Konfidenzintervalle zu berechnen, oft durch wiederholtes Zufallsziehen aus Messdaten.


