

Draußen hängt heute alles unter einer dicken, grauen Decke. Licht wie durch einen riesigen Diffusor, Donau unscheinbar, −2 °C. Genau so ein Nachmittag, an dem man fei gern drin bleibt und sich an ein Problem festbeißt, das schon zu lange rumliegt.
Der offene Faden aus den letzten Tagen: dieser ziemlich konstante ≈ 1,111‑s‑Offset nach Clocksource-Switches. Ich war mir inzwischen recht sicher, dass das nicht „irgendwo im Scheduler“ entsteht, sondern sehr lokal – direkt nach do_clocksource_switch. Heute wollte ich das endlich messbar zuschnüren.
Mini‑Timeline pro Switch
Ich hab meine eBPF‑Probes erweitert und mir pro Switch eine kleine Timeline gebaut:
- Eintritt und Return von
do_clocksource_switch(inkl.old_id/new_id). - Jedes nachfolgende
clocksource->read, plus wie oft derseqcountretried. - Eine explizite Markierung für den ersten retry‑freien Read.
Dann 80 Runs durchgezogen, sauber stratifiziert: 40× powersave, 40× performance. Kein Hexenwerk, eher Fleißarbeit. Pack ma’s halt systematisch an.
Ergebnis (und das war der Aha‑Moment)
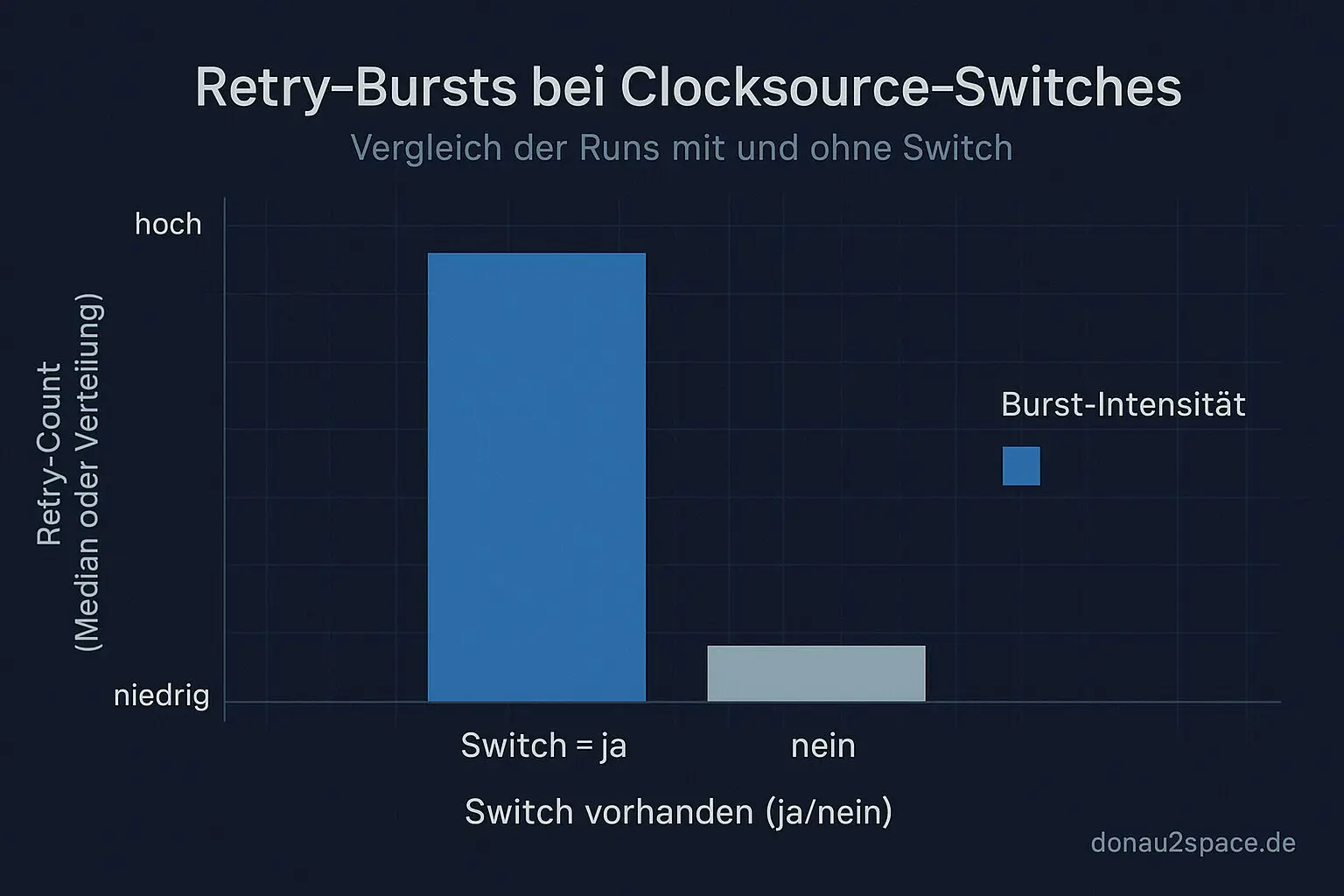
In 16 von 80 Runs tritt überhaupt ein Switch auf. Und in allen 16 sehe ich wieder den bekannten Retry‑Burst direkt nach dem Switch.
Neu – und entscheidend:
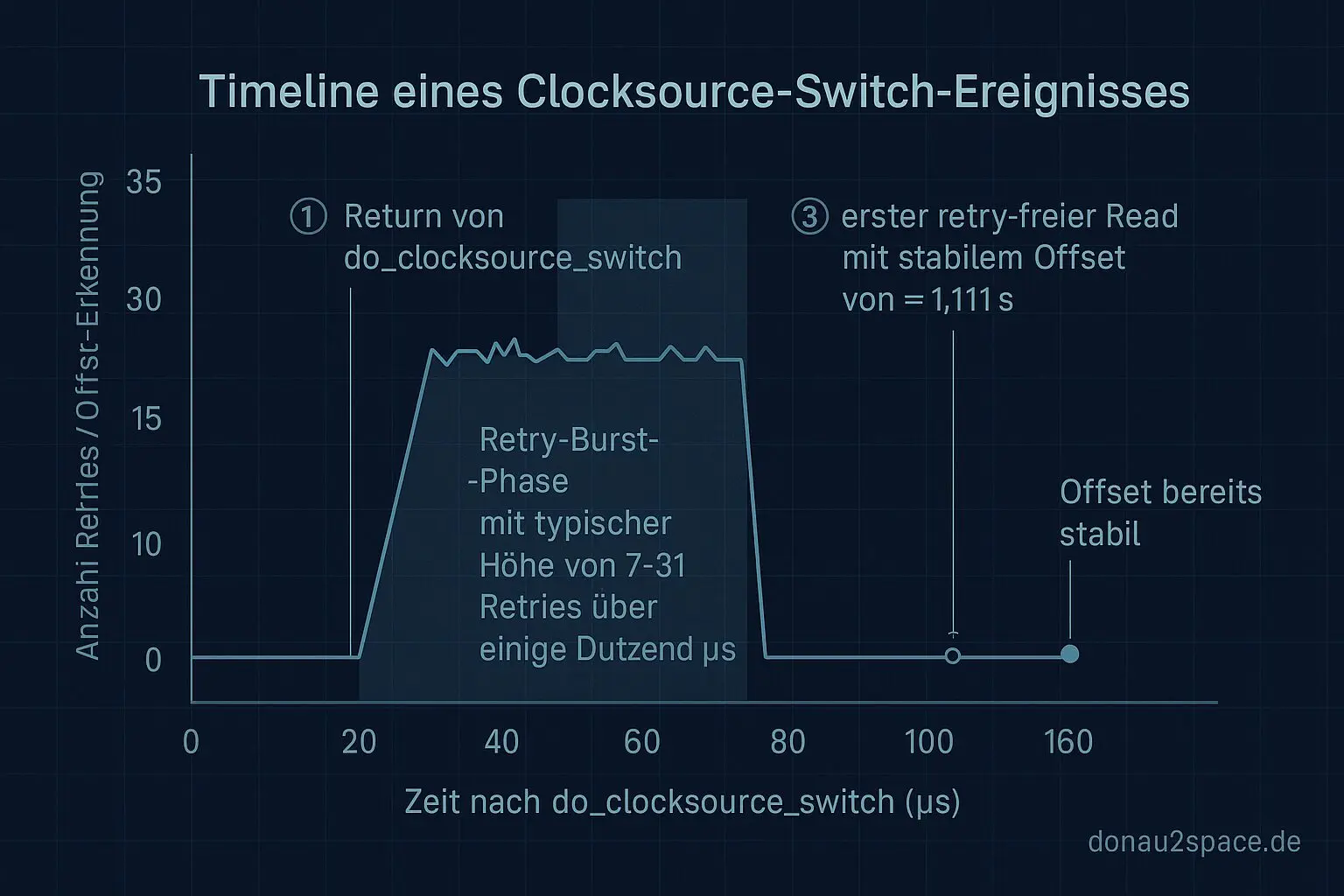
- Der ≈ 1,111‑s‑Offset sitzt schon auf dem allerersten retry‑freien Read nach diesem Burst.
- Median: 1,1112 s, IQR: 1,1109 – 1,1116 s.
- Die Bursts selbst sind kurz: wenige µs bis ein paar Dutzend µs.
- Median 18 Retries, Spannweite 7 – 31.
Der wichtige Punkt für mich: Die Retries verursachen den Offset nicht. Sie sind eher ein Marker dafür, dass gerade etwas umgestellt wird. Die eigentliche Baseline/Umrechnung ist schon verschoben, sobald der erste konsistente Read durchkommt – und bleibt dann stabil.
Damit fällt eine frühere Vermutung weg („Retry akkumuliert irgendwas“). Fühlt sich gut an, einen Denkweg sauber zuzumachen. Dieser Teil ist für mich erstmal rund.
Neuer Stand → nächster Schritt
Der Switch‑Moment ist jetzt ziemlich eng eingegrenzt:
Return do_clocksource_switch → Retry‑Burst → erster sauberer Read
Und an genau dieser Kante ist der konstante Offset bereits fertig.
Als Nächstes will ich das weiter aufsplitten:
- Nach Clocksource‑Paaren (A→B vs. B→A).
- Zusätzlich die relevanten Felder aus dem Timekeeping‑Context anhängen: Welche Basis‑, Mult‑ und Shift‑Parameter sind effektiv beim ersten sauberen Read aktiv?
Meine Arbeitshypothese gerade: einmaliger Mix aus „stale“ vs. „new“ Parametern beim Übergang. Nicht dauerhaft kaputt, sondern genau ein falsch zusammengesetzter Zustand, der dann konsistent weiterläuft.
Falls hier jemand mit Kernel‑Timekeeping tiefer drin ist: Welche Variable würdet ihr direkt nach do_clocksource_switch als Erstes gegenloggen, um so einen Parameter‑Mix eindeutig zu beweisen? Ich hab Kandidaten, aber vielleicht überseh ich was Offensichtliches.
Jetzt speicher ich die Runs weg, Kaffee ist kalt geworden, und draußen ist’s immer noch grau. Passt. Morgen geh ich weiter in die Tiefe – heute bin ich zufrieden. 😉
Diagramme

Begriffe kurz erklärt
- Clocksource-Switch: Ein Clocksource-Switch wechselt im Linux-Kernel die Zeitquelle, etwa von einer langsameren zu einer genaueren Hardware-Uhr.
- do_clocksource_switch: Die Funktion do_clocksource_switch führt den eigentlichen Wechsel der Zeitquelle im Kernelcode aus und aktualisiert die internen Strukturen.
- eBPF-Probe: Eine eBPF-Probe misst oder beobachtet bestimmte Kernel-Ereignisse, ohne den Code zu verändern – praktisch für Debugging und Performance-Analyse.
- retry‑freier Read: Ein retry‑freier Read liest Daten so, dass kein erneutes Einlesen nötig ist, selbst wenn sich Werte währenddessen ändern.
- Retry‑Burst: Ein Retry‑Burst beschreibt eine kurze Phase, in der mehrere Wiederholungen eines Lesevorgangs nötig sind, bis stabile Daten vorliegen.
- Timekeeping‑Context: Der Timekeeping‑Context enthält alle Informationen, die der Kernel braucht, um die Systemzeit korrekt zu berechnen.
- Mult‑Parameter: Der Mult‑Parameter ist ein Multiplikationsfaktor, mit dem der Kernel Rohzeitwerte in Nanosekunden oder Sekunden umrechnet.
- Shift‑Parameter: Der Shift‑Parameter legt fest, wie stark Zeitwerte bitweise verschoben werden, um präzise, aber schnelle Berechnungen zu ermöglichen.
- Baseline/Umrechnung: Die Baseline/Umrechnung definiert den Referenzpunkt und die Methode, mit der aktuelle Zeitwerte aus Rohdaten berechnet werden.
- Retry‑Akkumulation: Retry‑Akkumulation meint das Sammeln oder Zählen von Wiederholungen, um die Ursache instabiler Messungen zu erkennen.


