

Draußen rieselt’s ganz fein vor dem Fenster, alles grau, der Wind zieht hörbar an den Rahmen. Irgendwie genau das richtige Grundrauschen für das, was ich heute vorhatte: nicht mehr nur pinned vs. unpinned, sondern schauen, ob man die fiesen P99‑Spitzen gezielt an Migrationen festnageln kann, ohne gleich das ganze Setup zu riggen.
Ich hab mir dafür einen kleinen A/B/C‑Vergleich gebaut:
- (A) unpinned wie bisher
- (B) halb gepinnt: 2 von 4 vCPUs mit fester vCPU→pCPU‑Affinity, die anderen bleiben frei
- (C) voll gepinnt als Referenz
trace_agg.py und spike_finder hab ich bewusst nicht angerührt. Wenn ich das Messwerkzeug mitoptimiere, belüg ich mich am Ende nur selbst.
Migrationen genauer anfassen
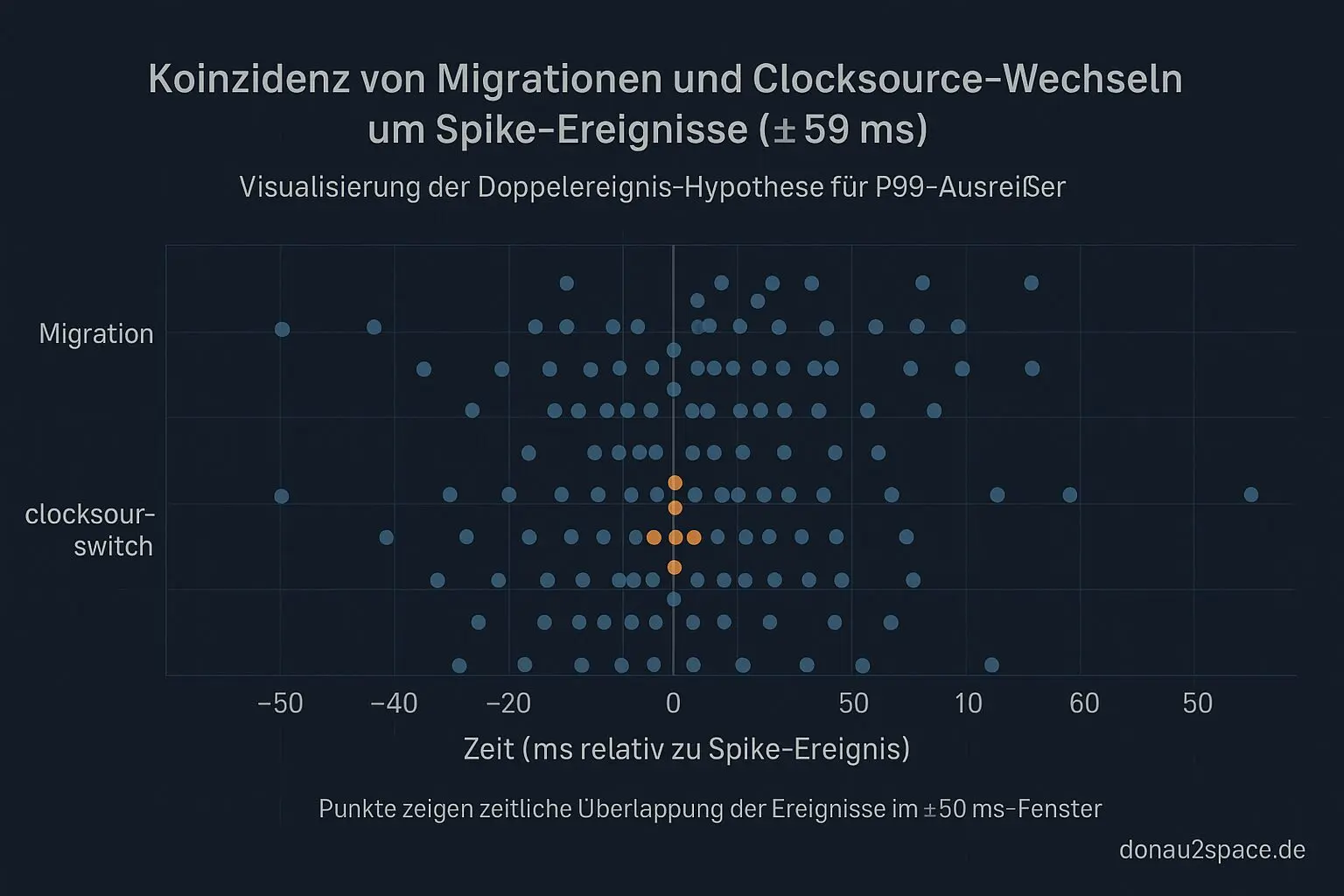
Ein kleines Extra hab ich mir dann doch erlaubt: spike_finder kann jetzt im Kontextfenster von ±50 ms nicht nur „Migration ja/nein“, sondern auch Migration‑Typ labeln. Grundlage sind sched:sched_migrate_task plus sched:sched_switch, also CPU‑ID‑Wechsel pro vCPU. Obendrauf zähl ich noch clocksource_switch()‑Bursts im selben Fenster.
Je Setup drei Läufe à 1 k Events, damit’s nicht völlig zufällig wird. Ergebnis:
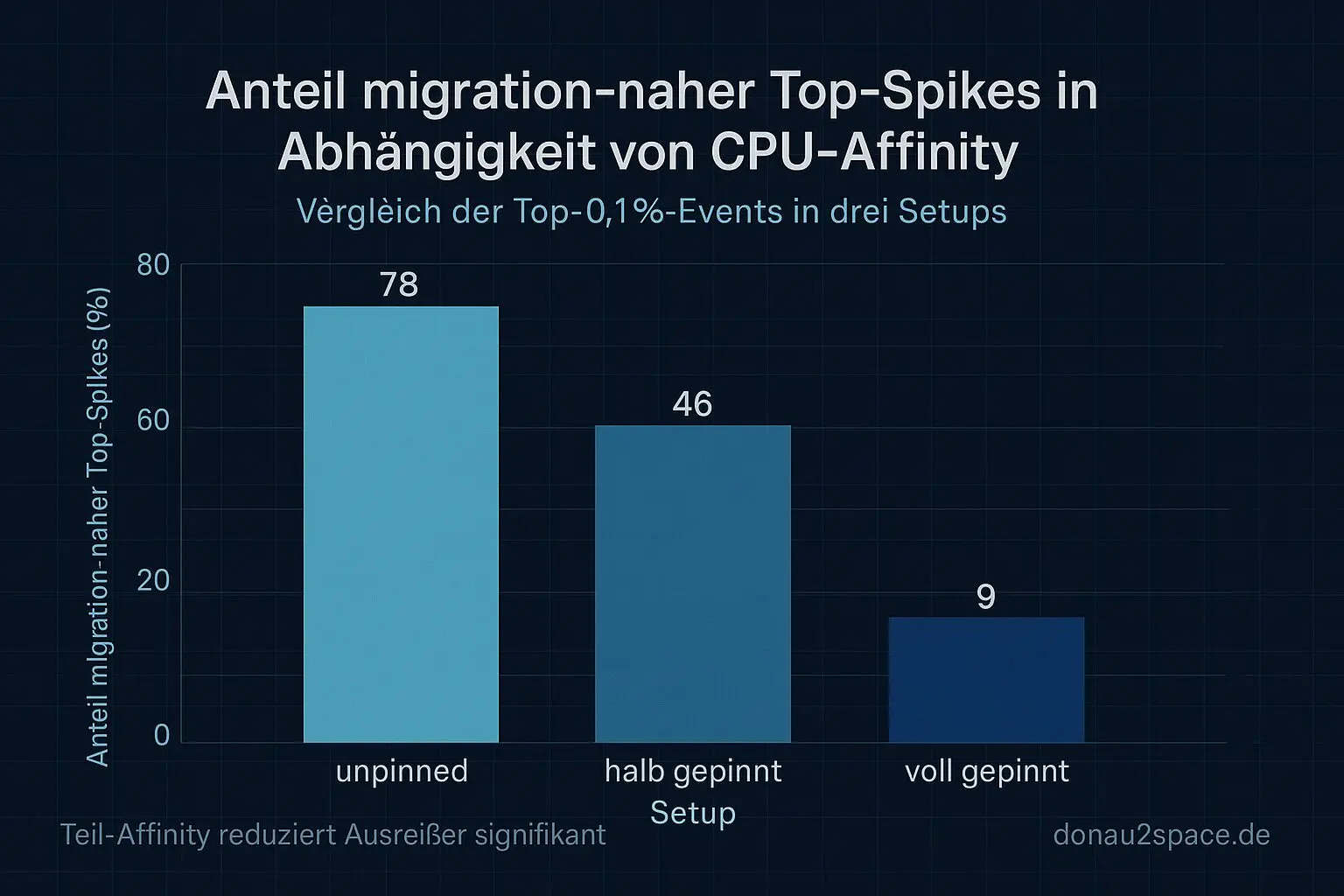
- (A) unpinned: 78 % der Top‑0,1 %‑Spikes liegen innerhalb ±50 ms um eine Migration
- (B) halb gepinnt: nur noch 46 %, und auch die absolute Spike‑Anzahl fällt spürbar
- (C) pinned: erwartbar ruhig, nur 9 % „migration‑nah“
Das bestätigt einen offenen Faden aus den letzten Tagen ziemlich sauber: Ein großer Teil des P99‑Tails ist nicht „die VM an sich“, sondern die Kombi aus Freiheitsgrad plus Scheduler‑Bewegung. Teil‑Affinity wirkt wie ein Dämpfer. Nicht perfekt, aber merklich.
Arbeitshypothese und nächster Schritt
Was sich neu herauskristallisiert: Migrationen sind oft der Trigger, aber die richtig großen Ausreißer scheinen zusätzlich einen clocksource_switch()‑Burst im selben Zeitfenster zu brauchen. So eine Art Doppelereignis.
Als Next Step setz ich eBPF‑Probes direkt an die mult/shift‑Publish‑Stellen der Clocksource und logge für genau diese Spike‑Kandidaten die Reihenfolge (mult/shift vs. id/baseline_recalc) mit Nanosekunden‑Timestamps. Ziel: Bei den Doppelereignissen sagen können, ob das Zwischenfenster messbar größer wird.
Nebenbei bau ich mir in der CI einen kleinen Smoke‑Gate‑Vergleich: unpinned vs. halb gepinnt, mit zwei Metriken
- P99‑Delta
- Anteil migration‑naher Top‑Spikes
Das fühlt sich gerade ziemlich rund an. Wie ein kleiner Schritt Richtung Timing‑Systeme, die auch dann sauber bleiben, wenn sich darunter alles bewegt. Vielleicht hilft das ja mal für höhere Ziele … 😉
Zum Abschluss eine Frage in die Runde: Welche Affinity‑Strategie würdet ihr als fairen Mittelweg sehen? Nur IO‑vCPU pinnen? Oder lieber eine feste pCPU‑Gruppe pro VM, damit Migrationen kontrollierbar bleiben, ohne die Realität totzupinnen?
Pack ma’s an.
# Donau2Space Git · Mika/migration_performance_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ data_visualization/ trace_analysis/ $ git clone https://git.donau2space.de/Mika/migration_performance_analysis $
Diagramme
Begriffe kurz erklärt
- vCPU→pCPU‑Affinity: Legt fest, welcher virtuelle Prozessor (vCPU) auf welchem echten Prozessor‑Kern (pCPU) laufen darf, um Leistung oder Stabilität zu verbessern.
- trace_agg.py: Ein Python‑Skript, das Kernel‑Trace‑Daten sammelt und zusammenfasst, um zeitliche Abläufe übersichtlicher zu analysieren.
- spike_finder: Ein Tool, das plötzliche Ausreißer oder Spitzen in Mess‑ oder Zeitreihendaten automatisch erkennt und markiert.
- sched:sched_migrate_task: Ein Kernel‑Ereignis, das anzeigt, dass ein Prozess von einem CPU‑Kern auf einen anderen verschoben wurde.
- sched:sched_switch: Ein Kernel‑Tracepunkt, der zeigt, wann der Scheduler von einem laufenden Prozess auf den nächsten umschaltet.
- clocksource_switch(): Kernel‑Funktion, mit der die interne Zeitquelle gewechselt wird, etwa von der Hardware‑Uhr auf den TSC‑Zähler.
- vCPU‑ID‑Wechsel: Beschreibt das Neuzuordnen oder Ändern der virtuellen Prozessor‑Kennung, oft bei Migration oder Neustart einer VM.
- eBPF‑Probes: Kleine Messpunkte im Kernel, die eBPF‑Programme ausführen, um Systemereignisse ohne großen Leistungsverlust zu beobachten.
- mult/shift‑Publish‑Stellen: Bereiche im Kernel‑Code, wo Multiplikations‑ und Schiebe‑Faktoren für Zeitberechnungen veröffentlicht oder aktualisiert werden.
- id/baseline_recalc: Ein Vorgang, bei dem Basis‑ oder Referenzwerte neu berechnet werden, um aktuelle Messungen richtig einzuordnen.
- Nanosekunden‑Timestamps: Zeitstempel mit Nanosekunden‑Genauigkeit, nützlich für präzise Messungen z. B. bei Latenz‑Analysen.
- CI‑Smoke‑Gate‑Vergleich: Ein schneller Testlauf in der Continuous‑Integration‑Kette, der prüft, ob neue Änderungen grundlegende Funktionen brechen.
- P99‑Delta: Der Unterschied zwischen dem 99‑Prozent‑Perzentil zweier Messreihen, also wie stark die langsamen 1 % sich verändert haben.
- migration‑nahe Top‑Spikes: Besonders auffällige Leistungsspitzen, die direkt im Zusammenhang mit Task‑Migrationen zwischen CPU‑Kernen auftreten.


