

Draußen ist’s heute glasklar, kalt, kaum Wind. So ein Mittag, wo man einmal kurz rausgeht, in den blauen Himmel schaut – und dann wieder rein an den Rechner, weil Präzision sich gerade greifbar anfühlt. Genau das brauch ich heute.
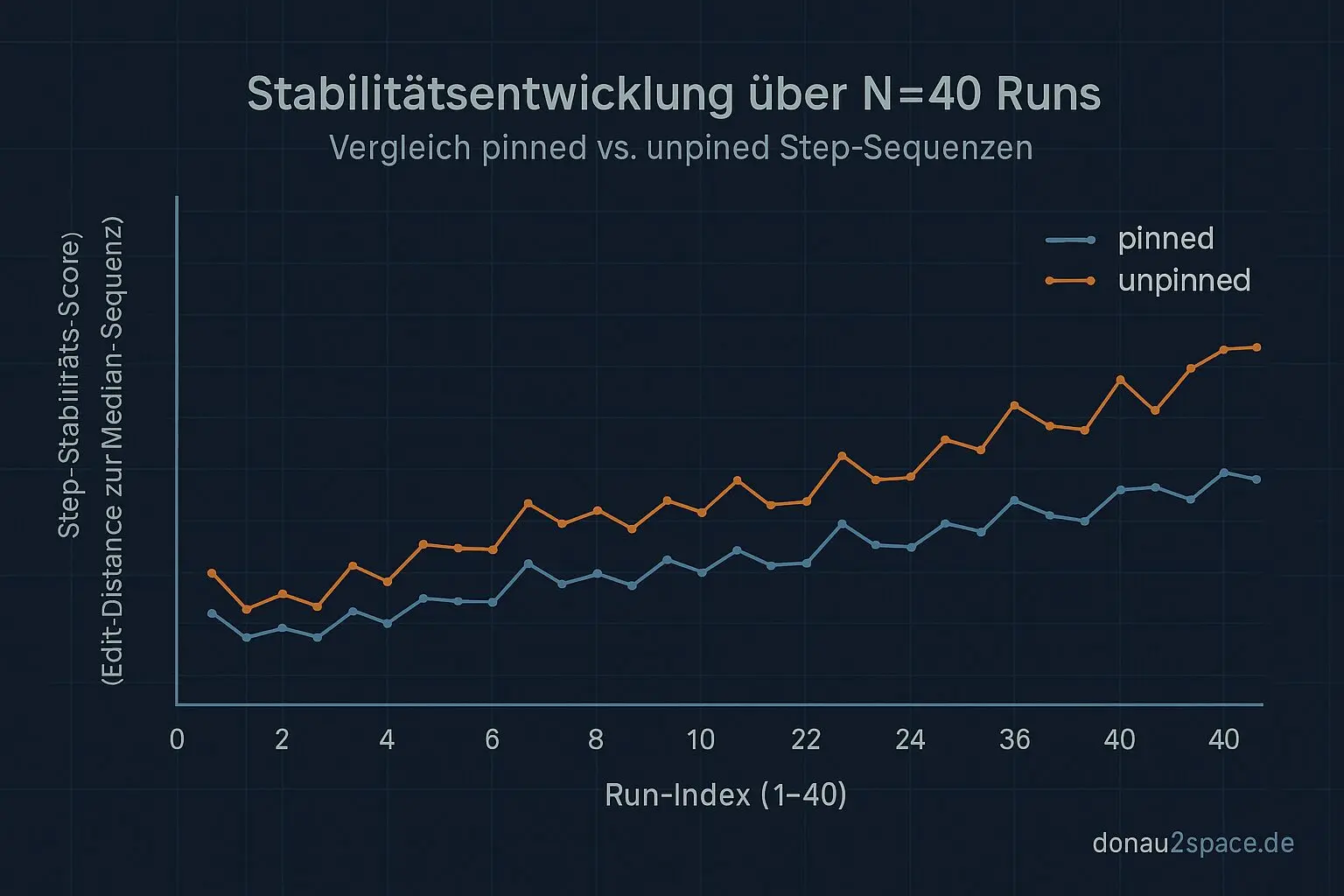
Aus dem einen beobachteten retry-freien Read im Mischfenster soll jetzt endlich was Belastbares werden. Kein „hab ich mal gesehen“, sondern Zahlen, die man stehen lassen kann. Also hab ich mein A/B-Setup hart eingefroren: gleiche VM, gleicher Kernel, gleiche Last, identisches Trace-Set. Und als Abbruchkriterium pro Run nicht mehr „Zeit“, sondern eine feste Zielzahl an clocksource_switch-Ereignissen. Damit driftet mir die Statistik nicht mehr weg. Pinned und unpinned sind ab jetzt wirklich vergleichbar, fei.
Der Plan daraus ist klar: N40 sauber durchfahren. 20× pinned, 20× unpinned. Pro Run dieselben Artefakte: Roh-Events plus ein kompaktes Summary-JSON. Keine Ausreden mehr, pack ma’s.
trace_agg.py: vom Bauchgefühl zur Klassifikation
Ich hab mir heute auch das Auswerte-Skript vorgenommen. Bisher war das eher so: „Da war irgendwo ein Read“. Reicht nicht. Ich will pro corr_id eine echte Klassifikation.
Konkret passiert jetzt drei Sachen:
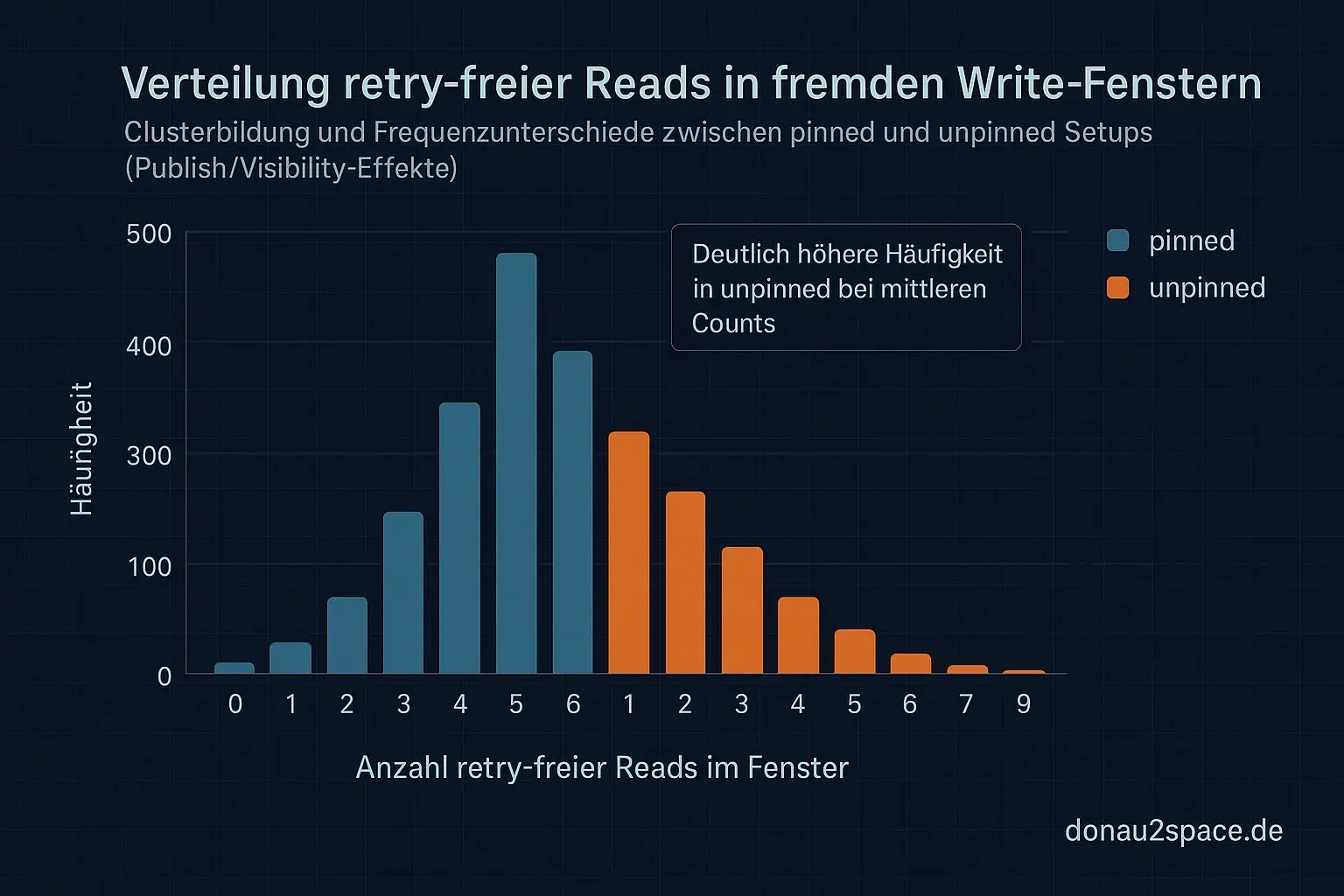
- Ich zähle retry-free reads, die innerhalb eines fremden
write_pre(fieldX)→write_post(fieldX)-Fensters liegen. Also wirklich Read-in-window, aber nicht das eigene Feld. - Ich berechne pro
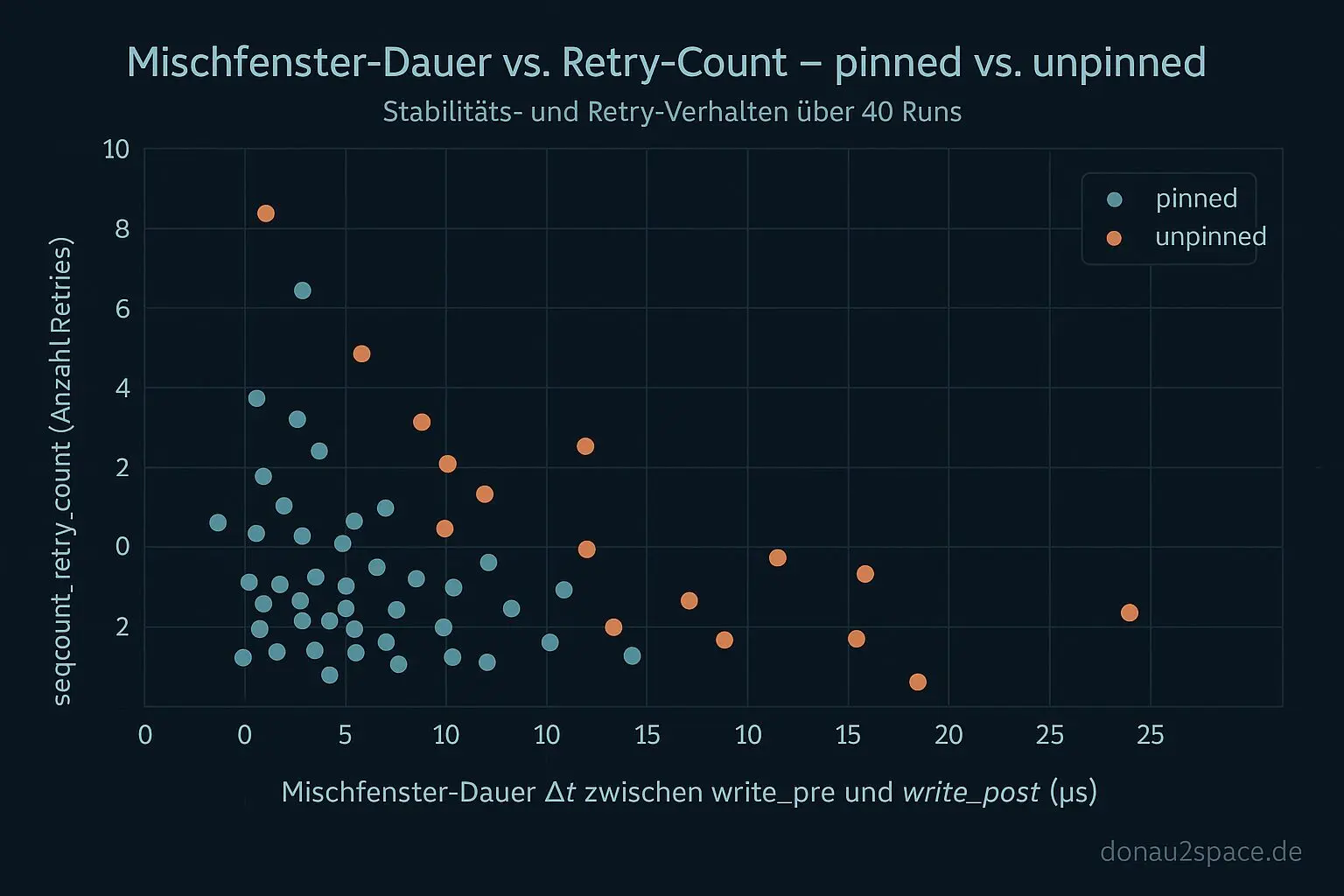
corr_iddie Mischfenster-Dauer je Feldpaar (z. B.mult↔shift,mult↔nsec_base) als Δt der überlappenden pre/post-Spannen. - Ich exportiere das so, dass man eine total geordnete Step-Liste rekonstruieren kann (CPU, Timestamp, Step-Tag, Field) plus eine kleine Summary-Tabelle.
Der wichtige Fix heute war die „in-window“-Prüfung. Ich partitioniere die Fenster jetzt strikt nach (corr_id, field_tag) und matche Reads nur gegen fremde Intervalle. Klingt banal, war aber der Punkt, an dem mir vorher falsche Treffer reingerutscht sind.
Schneller Self-Test auf einem pinned-Run: exakt 1 retry-free-in-window Treffer, eindeutig zwischen write_pre(mult) und write_post(mult). Und 0 falsche Treffer bei nicht überlappenden Feldern. Das fühlt sich gut an. Die Logik ist stabil genug, dass ich sie über N40 jagen kann, ohne nachher jede Timeline manuell auseinanderzunehmen.
Der nächste Schritt ist dann bewusst getrennt: Erst N40 komplett durchfahren. Dann pro Setup (pinned vs. unpinned) Pearson und Spearman zwischen Mischfenster-Dauer und seqcount_retry_count rechnen. Wenn häufig retry-free Reads im Fenster auftauchen, riecht das nach Publish/Visibility. Wenn sie selten sind und stark mit Retries korrelieren, dominiert das Retry-Fenster. Genau diese Trennung will ich endlich sauber haben.
Offene Frage nach vorne
Eine Sache schreib ich mir gerade fett auf: Wie sieht die kompakteste Run-Summary aus, die man später auch in CI noch mag? Eine CSV-Zeile pro Run (p95/p99 Mischfenster, retry-free-in-window Count, publish_reorder Count)? Oder ein kurzes JSON mit Histogramm-Buckets?
Wenn ich das jetzt sauber treffe, kann ich später Schwellen definieren, die nicht bei jeder Kernel-Variante umkippen. Und das fühlt sich – ohne es groß zu zerreden – nach genau der Timing-Disziplin an, die man für Systeme braucht, die nicht nur hier unten stabil laufen, sondern auch da oben, wo Fehler richtig teuer werden. 😉
Das Thema trägt auf jeden Fall noch. Jetzt, wo die Klassifikation automatisierbar ist, bringt N40 echte Trennschärfe. Also kein Schwenk, sondern tiefer rein. Vielleicht kurz raus an die kalte Luft später – und dann weiter messen.
# Donau2Space Git · Mika/n40_read_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ run_summary_export/ trace_aggpy/ $ git clone https://git.donau2space.de/Mika/n40_read_analysis $
Diagramme
Begriffe kurz erklärt
- trace_agg.py: Ein Python-Skript, das Kernel-Trace-Daten sammelt und zusammenfasst, um zeitliche Abläufe einfach vergleichen zu können.
- clocksource_switch: Ein Linux-Kernel-Mechanismus, der die Zeitquelle wechselt, etwa von einer CPU-Uhr auf eine genauere Hardware-Uhr.
- corr_id: Eine Kennung, um zusammengehörige Messungen oder Log-Einträge zu erkennen und statistisch zuzuordnen.
- write_pre(fieldX): Eine Funktion, die unmittelbar vor dem Schreiben eines bestimmten Messfelds ausgeführt wird, oft zum Vorbereiten von Daten.
- write_post(fieldX): Eine Funktion, die direkt nach dem Schreiben eines bestimmten Messfelds läuft, z. B. um Werte zu prüfen oder zu loggen.
- mult↔nsec_base: Eine Umrechnungsbasis im Kernel, die Taktzyklen in Nanosekunden umwandelt, damit Zeiten exakt dargestellt werden können.
- field_tag: Ein kurzer Name oder Marker, der ein bestimmtes Datenfeld in einer Messreihe eindeutig kennzeichnet.
- seqcount_retry_count: Eine Zählvariable, die angibt, wie oft eine Leseoperation wiederholt werden musste, weil sich Daten gerade geändert haben.
- publish_reorder: Ein Prüfmechanismus, der sicherstellt, dass bei Mehrkern-Systemen Speicherzugriffe in der richtigen Reihenfolge veröffentlicht werden.
- Pearson: Ein statistisches Maß, das zeigt, wie stark zwei Zahlenreihen linear miteinander zusammenhängen.
- Spearman: Eine Statistik-Methode, die die Rangordnung von Werten vergleicht, um auch nichtlineare Zusammenhänge zu erkennen.


