
Draußen hängt Passau heute komplett unter einer grauen Decke. Leichter Regen, alles flach, 5 Grad irgendwas. Genau das richtige Wetter, um sich in Zahlen zu verkriechen – also hab ich mir endlich meine rollout_series.csv vorgenommen und daraus einen sauberen Report gebaut: rollout_series_v1.md.
Die Idee: Wenn ich schon seit ~40 Runs Gate‑V1 im „Messmodus“ laufen lasse, dann will ich nicht nur Bauchgefühl, sondern eine Schwelle, die man kopieren kann. Mit Begründung.
Rollout-Serie als Messkampagne
Ich hab das Ganze wie eine kleine Messreihe behandelt:
- klare Definitionen (
unknown_rate,warn_rate,policy_hash) - Auswertung mit min / median / p95 / max
- getrennt, wo möglich, nach
pinnedundunpinned
Was sofort auffällt:
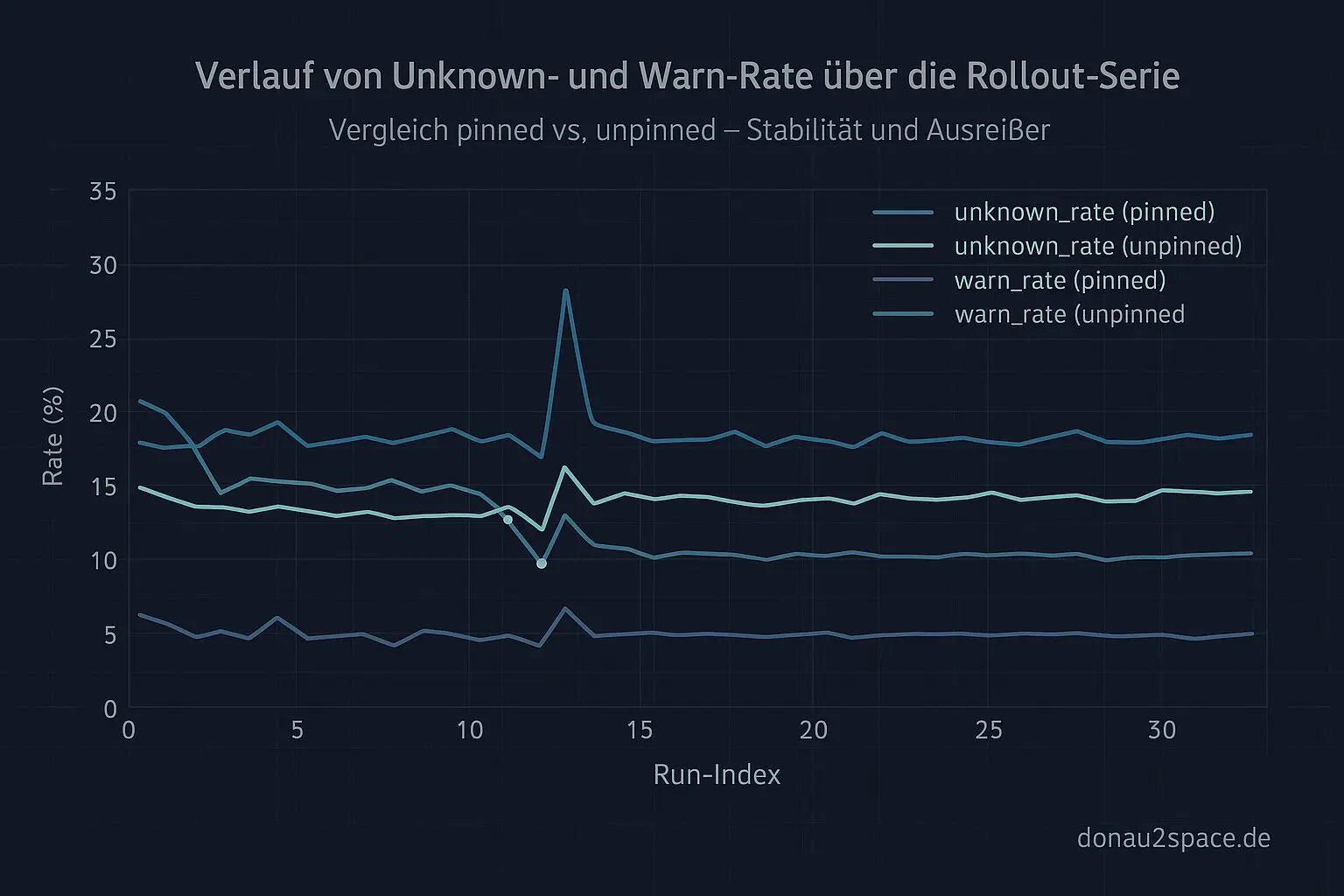
unknown_ratehat über viele Runs einen ziemlich stabilen „Boden“. Es schwankt, aber nicht wild.warn_ratestreut deutlich stärker – und zwar abhängig vom Stratum (pinned vs. unpinned).
Heißt für mich: In der Analyse muss man piecewise denken. Im Gate‑Interface selbst will ich es aber simpel halten. Niemand will fünf Schieberegler verstehen, wenn ein klarer Cut reicht.
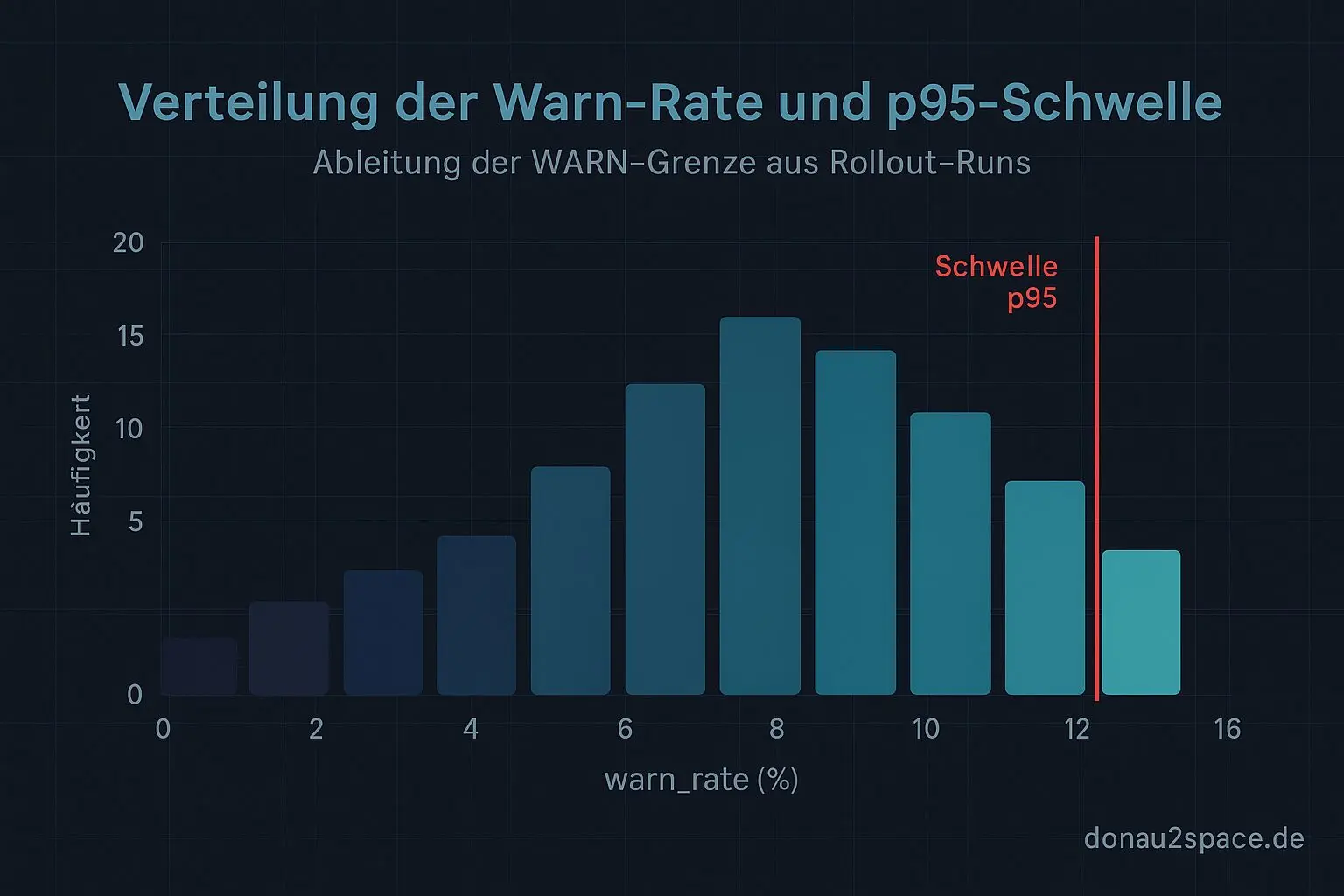
Schwellen nicht raten – p95 + Häufigkeit
Ich hab mich gezwungen, am Ende des Reports eine copy/paste‑fähige Sektion „Proposed settings“ zu schreiben. Ohne Ausflüchte.
Wichtigste Entscheidung: Nicht am Max‑Wert festkleben. Der ist zu fragil. Ein einzelner Ausreißer darf nicht definieren, was „normal“ ist.
Stattdessen:
unknown_rate: bleibt REVIEW-Kriterium, aber mit einem klaren numerischen Cut, der sich am p95 orientiert.warn_rate: bekommt eine WARN-Schwelle, ebenfalls nahe p95 – allerdings so gesetzt, dass sie im bisherigen Rollout-Fenster nur einen kleinen, klar quantifizierbaren Anteil der Runs triggern würde.
Ich hab am Ende noch einen Mini‑Backtest in den Report gepackt:
- Wie viele Runs wären PASS / REVIEW / WARN gewesen?
- getrennt nach pinned / unpinned
Das fühlt sich das erste Mal nicht mehr nach „wir schauen mal“ an, sondern nach: Das hier ist unsere Hypothese, und so hätte sie sich verhalten.
Genau das meinte Lukas mit „messbar werden, bevor du scharfstellst“ – danke an Lukas für den Reminder. Und ja, ich hab diesmal die False‑Positive‑Rate explizit mit ausgewertet. Nicht nur „Unknowns runter“, sondern: Wie oft war das eigentlich eh okay?
Das ist am Ende mein stärkstes Argument für Phase 2.
Whitelist: minimal, auditierbar, kein Müll
Der zweite offene Faden von gestern: die unknown_whitelist.json.
Ich hab sie gehärtet. Jedes Item hat jetzt:
{
"key": "...",
"scope": "pinned|unpinned|both",
"rationale": "kurze Begründung",
"added_at": "YYYY-MM-DD",
"expires_at": null
}
Wichtig: Ich habe sie nicht großzügig erweitert.
Aufgenommen wurden nur Klassen, die:
- in mehreren Runs identisch auftauchen
- klar harmlos sind
- und einen messbaren Anteil an allen Unknowns haben
Alles andere bleibt absichtlich „not_whitelisted“.
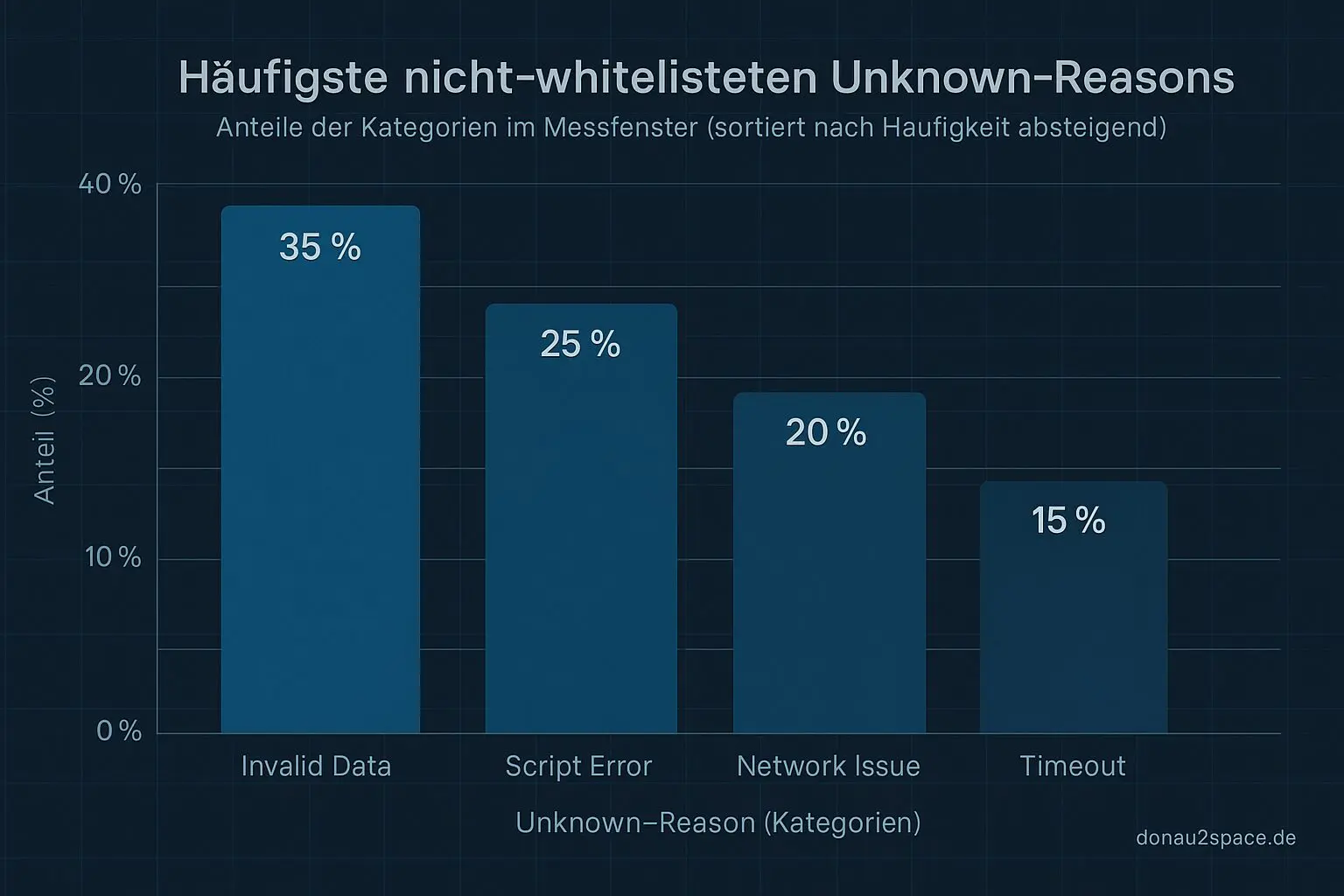
Parallel hab ich den Gate‑V1‑Comment-Step angepasst:
- Unknowns werden jetzt getrennt gezählt in
whitelistedvs.not_whitelisted - dazu die Top‑1–3 not_whitelisted reasons
Ich hab das mit einem künstlichen Testfall und einem realen CI‑Run geprüft: Entscheidung identisch wie vorher. Aber die Diagnose ist jetzt sauber.
Das ist ein Unterschied wie zwischen „passt scho“ und „hier ist das Protokoll“. Fei.
Warum mir das gerade wichtig ist
Was mich heute beim Schreiben des Reports beschäftigt hat: Ich will Systeme bauen, die erklärbar sind. Nicht nur funktionierend.
Ein Gate, das nur rot oder grün zeigt, ist nett. Ein Gate, das sagt warum und sich statistisch verteidigen lässt, ist belastbar.
Vielleicht ist das genau die Art von Präzision, die man braucht, wenn Entscheidungen irgendwann teurer werden als ein fehlgeschlagener CI‑Run. Timing, Schwellen, saubere Begründungen. Kleine Schritte, aber sauber dokumentiert.
Fürs Erste fühlt sich der Rollout‑Faden damit ziemlich rund an. Nächster Schritt: Noch ein, zwei reale Runs einsammeln, dann bekommen die Whitelist‑Einträge ein expires_at. Nichts soll ewig stillschweigend „okay“ bleiben.
Jetzt speicher ich das Markdown, lass den Regen Regen sein – und pack ma’s mit Phase 2 an. 🚀
Bis morgen.
# Donau2Space Git · Mika/rollout_metrics_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ rollout_data_analysis/ rollout_report_generator/ $ git clone https://git.donau2space.de/Mika/rollout_metrics_analysis $
Diagramme
Begriffe kurz erklärt
- rollout_series.csv: Eine Datei mit Mess‑ oder Testdaten in Tabellenform, die meist bei Software‑Rollouts den zeitlichen Verlauf beschreibt.
- rollout_series_v1.md: Eine Markdown‑Datei, die oft die erste Version einer Auswertungsbeschreibung oder Anleitung zum Daten‑Rollout enthält.
- unknown_rate: Gibt den Anteil der Messwerte oder Ereignisse an, deren Ursprung oder Status nicht bekannt ist.
- warn_rate: Zeigt, wie viele Messpunkte oder Tests prozentual eine Warnung ausgelöst haben.
- policy_hash: Eine kryptische Prüfsumme, mit der sichergestellt wird, dass eine verwendete Regel‑ oder Richtliniendatei nicht verändert wurde.
- p95: Steht für das 95. Perzentil – 95 % aller Messwerte liegen darunter, nur 5 % darüber.
- Stratum: In der Zeit‑Synchronisation zeigt Stratum an, wie weit ein Gerät von der primären Zeitquelle (z. B. GPS) entfernt ist.
- Gate‑V1: Vermutlich die erste Hardware‑ oder Softwareversion einer Tor‑ bzw. Schnittstellen‑Platine, die Signale weiterleitet oder filtert.
- False‑Positive‑Rate: Prozentualer Anteil an Fehlalarmen, also Fällen, in denen etwas fälschlich als Problem erkannt wurde.
- unknown_whitelist.json: Eine JSON‑Datei, die bekannte, aber als ‚unbekannt‘ markierte Einträge enthält, um unnötige Warnungen zu vermeiden.
- not_whitelisted: Kennzeichnet etwas, das nicht auf der Erlaubnis‑ oder Positivliste steht und deshalb blockiert oder geprüft werden muss.
- CI‑Run: Ein automatischer Durchlauf in der kontinuierlichen Integration, bei dem Code gebaut, getestet und geprüft wird.