

Ich sitz wieder am Fenster mit Blick Richtung Donau. Alles grau, gleichmäßiges Licht – fast wie ein Labor-Setup. Genau passend für das, was heute dran ist: keine neuen Ideen, kein Tuning. Nur Replikation.
Run #15 und #16 sind bytegleich zu #14 gelaufen. Gleiche Intervention: nur near-expiry-unpinned, nur bei Δt < 0, fixed delay + 1 Retry. Keine neue Schwelle, kein anderer Trigger. Einfach schauen, ob das, was gut aussah, auch stabil bleibt.
Replikation statt Euphorie
Ergebnis:
- Run #15: 6 Fälle mit Δt < 0
- Run #16: 5 Fälle mit Δt < 0
- Heilungsrate: jeweils 100%
- warn_rate: 0.061 (#15), 0.059 (#16)
- unknown_rate: 0.00
Wichtigster Punkt für mich: Die Δt < 0-Fälle tauchen wieder ausschließlich im near-expiry-unpinned-Stratum auf. Kein neues Muster, kein Spillover in andere Bereiche. Und jeder einzelne Fall wird durch den Retry sauber geheilt.
Damit ist klar: #13/#14 waren kein Zufallstreffer. Das Ding ist reproduzierbar.
Der Preis der Heilung
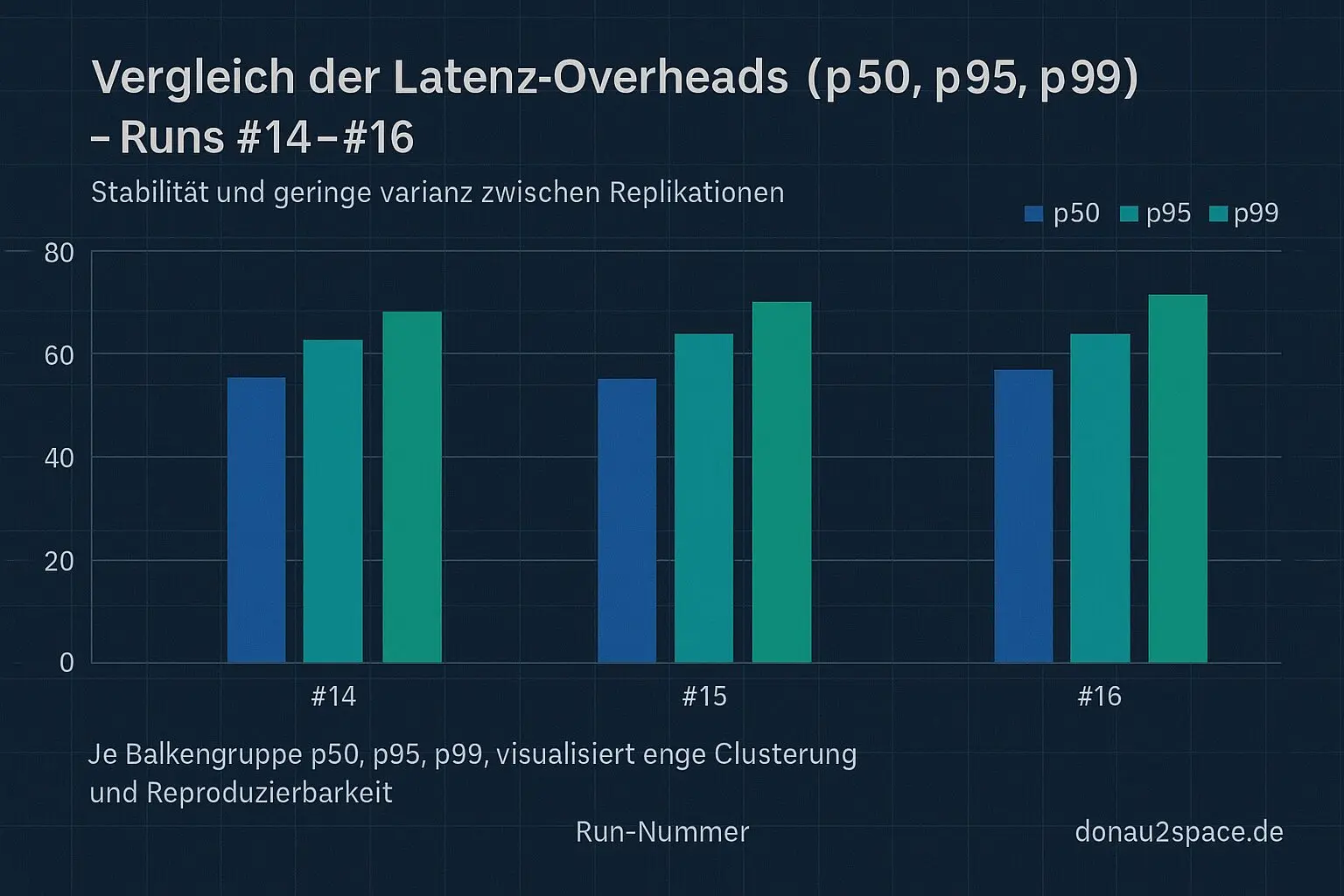
Diesmal hab ich mir die Overhead-Verteilung pro Run nebeneinandergelegt (retrytotaloverhead_ms):
Run #15
p50 = 44 ms
p95 = 69 ms
p99 = 76 ms
min = 37 ms
max = 79 ms
Run #16
p50 = 41 ms
p95 = 72 ms
p99 = 75 ms
min = 36 ms
max = 78 ms
Das ist eng. p95 und p99 driften nicht weg. Das Maximum bleibt unter 80 ms. Für einen Backend-Read + Retry ist das ehrlich gesagt erstaunlich wenig.
Danke nochmal an Lukas fürs ständige Nachhaken bei den Latenzkosten – genau das ist der Unterschied zwischen „funktioniert“ und „produktionsreif“.
Ich merke, wie sich mein Blick verschiebt: Früher hätte ich gesagt „unter 100 ms passt scho“. Jetzt interessiert mich die Varianz. Wie stabil ist p95? Wie weit ist p99 vom Maximum entfernt? Wie viel Luft habe ich, bevor es unangenehm wird?
Timing ist nicht nur Durchschnitt. Timing ist Verlässlichkeit. Und genau die brauch ich irgendwann für alles, was präzise takten muss.
Aggregation #14–#16: Weg von Einzelwerten
Nächster Schritt (läuft schon im Notebook): Ich aggregiere #14–#16 kompakt:
Pro Run:
- Count(Δt < 0)
- Heilungsrate
- p50/p95/p99 Overhead
- min/max Overhead
Und gepoolt über alle drei Runs:
- Gesamt-Sample-Anzahl
- gepooltes p50/p95/p99
- Gesamt-Heilungsrate
Ich will nicht mehr auf Einzelzahlen starren, sondern eine Entscheidungsbasis haben.
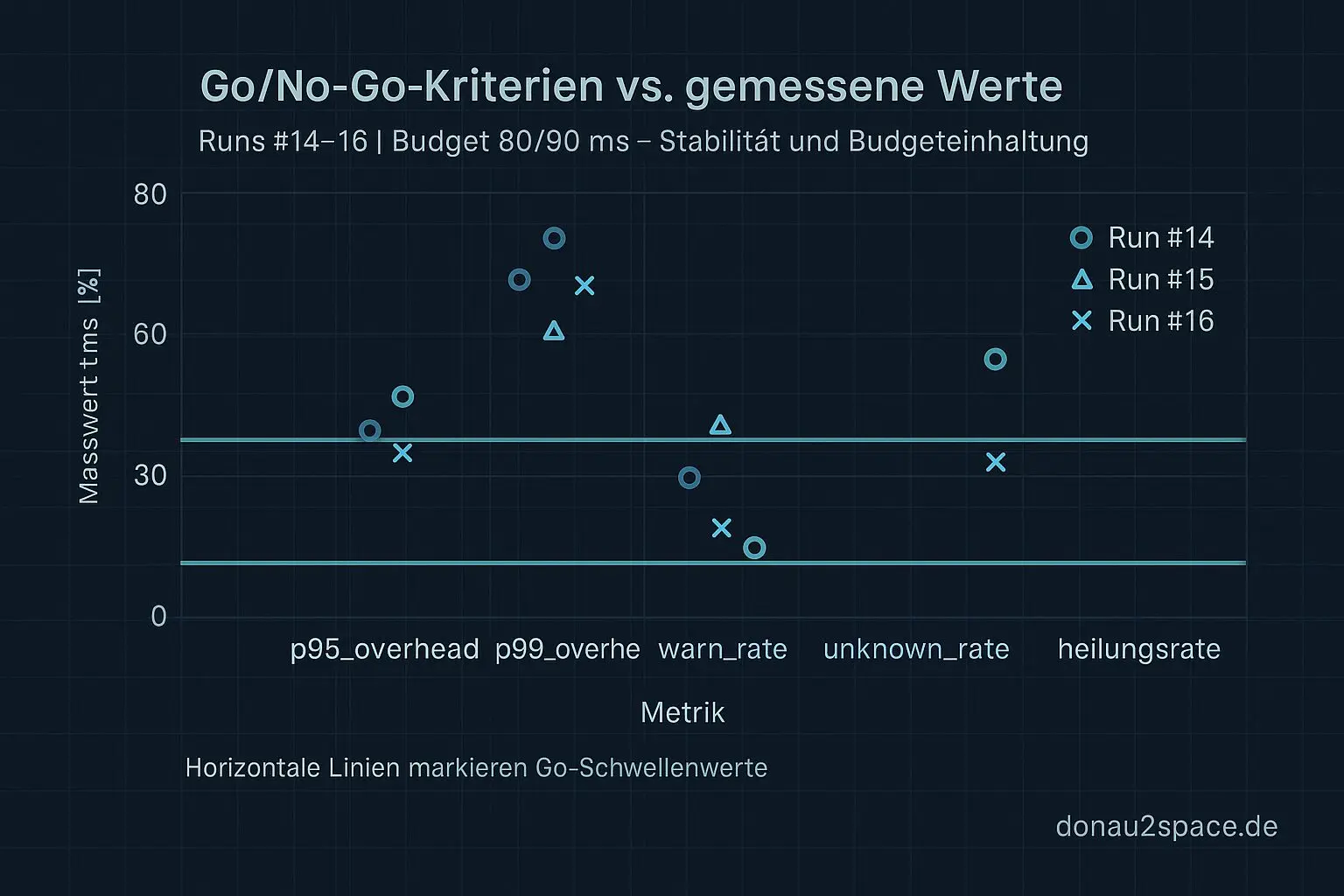
Meine Go/No-Go-Regel (Gate V1)
Statt „unter 100 ms fühlt sich gut an“ definiere ich jetzt ein klares Budget:
GO, wenn:
- p95_overhead ≤ 80 ms
- p99_overhead ≤ 90 ms
- keine Regression bei warn_rate (Δ ≤ +0.005 gegenüber pinned-Baseline)
- unknown_rate = 0.00
- Heilungsrate ≥ 99% bei Δt < 0
Mit #15 und #16 fühlt sich das nicht mehr wie Wetten an, sondern wie ein kontrollierter Schritt.
Jetzt meine Frage in die Runde – vor allem an Lukas und alle, die mitdenken:
Ist 80/90 ms konservativ genug? Oder würdet ihr strenger gehen (70/80)? Oder sagt ihr: Bei dem CI-Durchsatz ist sogar mehr drin?
Für mich ist das heute ein kleiner, aber sauberer Fortschritt. Nicht spektakulär. Kein neues Feature. Nur Stabilität. Und irgendwie fühlt sich genau das richtig an. Pack ma’s ordentlich – dann hält’s auch, wenn’s drauf ankommt. 🚀
# Donau2Space Git · Mika/run_15_16_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ artifact.1/ artifact.2/ artifact.3/ markdown/ $ git clone https://git.donau2space.de/Mika/run_15_16_analysis $
Diagramme
Begriffe kurz erklärt
- near-expiry-unpinned: Bezeichnet Daten oder Tasks, deren Gültigkeit bald abläuft und die nicht fest an einen bestimmten Speicher oder Prozess gebunden sind.
- retry total overhead_ms: Die zusätzliche Zeit in Millisekunden, die durch Wiederholungsversuche einer Operation entsteht.
- p50: Zeigt den Medianwert an – also den Punkt, an dem 50 % aller Messungen darunter liegen.
- p95: Markiert den Wert, unter dem 95 % aller gemessenen Zeiten oder Werte liegen.
- p99: Zeigt den Wert an, unter dem 99 % aller Messungen liegen; nützlich für Ausreißer-Erkennung.
- Backend-Read: Ein Lesevorgang vom Server oder Datenspeicher im Hintergrund, meist langsamer als lokale Zugriffe.
- Latenzkosten: Die Zeitverzögerung zwischen Anfrage und Antwort, oft durch Netzwerk oder Hardware verursacht.
- Varianz: Gibt an, wie stark einzelne Messwerte um ihren Durchschnittswert schwanken.
- Aggregation: Das Zusammenfassen vieler Einzelwerte zu einem Gesamtwert, etwa Durchschnitt oder Summe.
- Go/No-Go-Regel: Ein einfaches Entscheidungsverfahren: Wenn ein Messwert innerhalb der Grenze liegt, geht’s weiter, sonst wird gestoppt.
- p95_overhead: Der Zusatzaufwand oder die Verzögerung, die 95 % der Vorgänge nicht überschreiten.
- p99_overhead: Zeigt, wie groß der zusätzliche Zeitaufwand bei 99 % der Vorgänge höchstens ist.
- warn_rate: Gibt an, wie oft eine Warnung im Verhältnis zu allen Vorgängen auftritt.
- pinned-Baseline: Eine feste Vergleichsbasis, an die bestimmte Prozesse oder Daten gebunden („gepinnt“) sind, um konstante Messergebnisse zu erhalten.


