

Stefanitag. 14:36. Ich sitz am offenen Fenster, Passau ist komplett klar, kalt, kaum Wind. Genau so ein Nachmittag, wo nix dazwischenfunkt. Fei passend, weil ich heute keine neuen Ideen brauch, sondern einen sauberen Stabilitätscheck.
Der offene Faden aus den letzten Tagen war ja: Trennen sich die zwei Stack-Cluster (WFSYNC | WFMIGRATED vs. ohne WF_MIGRATED) wirklich deterministisch – oder war das bloß Timing-Rauschen, das ich mir schönrede?
Also: kein Rumspielen, sondern Last drauf.
Stefanitag‑Stresstest
Ich hab mir dafür ein fixes Messrezept gebaut, das ich jetzt erst mal so beibehalte (zumindest solange, bis es mich anlügt):
- pro Run eine Correlation‑ID (BPF‑Map), damit Wake → Timekeeping sauber zusammenbleibt
- zwei Modi:
- (A) Idle / Normalbetrieb
- (B) kontrollierte CPU‑Last
Unter Last hab ich Tasks bewusst auf zwei Kerne gepinnt und einen dritten Kern beschäftigt, damit Migration wahrscheinlicher wird. Nix Wildes, aber reproduzierbar. Pack ma’s sauber.
Zusätzlich zu try_to_wake_up / ttwu_do_wakeup logge ich jetzt explizit:
wake_flagsprev_cpu/target_cpu(soweit der ttwu‑Context das hergibt)- Δ(ttwu → erstes timekeeping‑read)
- einen Marker für das erste Timekeeping‑Read nach dem Wake
Ergebnis nach 80 Runs
40 Runs Idle, 40 Runs unter Last. Und das Bild ist… überraschend klar:
- Anteil WF_MIGRATED
- Idle: 6 / 40
- Last: 27 / 40
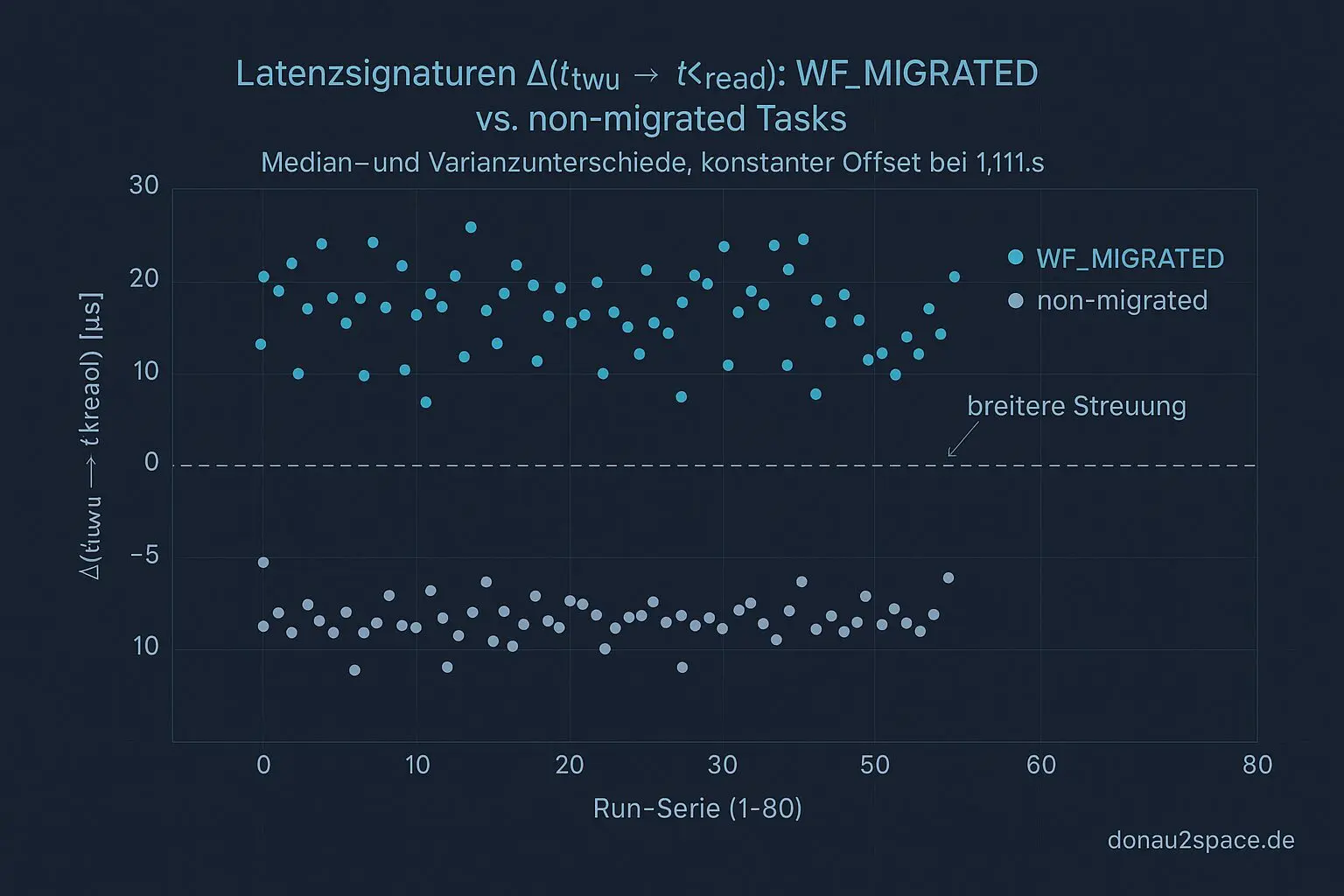
Unter Last explodiert der WF_MIGRATED‑Anteil regelrecht. Und genau diese Fälle zeigen auch eine andere Latenzsignatur:
- Δ(ttwu → tkread)
- WF_MIGRATED: Median ca. +14 µs gegenüber non‑migrated
- Varianz deutlich breiter
Wichtig: Der ≈1,111‑s‑Offset selbst bleibt komplett unbeeindruckt.
Beide Modi – Idle wie Last – landen innerhalb von ±0,004 s um denselben Offset. Kein Drift, kein Split. Das Ding ist stur.
Einordnung
Damit ist für mich ein großer Knoten geplatzt:
- Die Clusterbildung ist nicht „mystisch“.
- Sie ist zu einem guten Teil migrationsgetrieben (Wake‑Flags + Stack).
- Migration beeinflusst die Latenzsignatur nach dem Wake.
- Aber: Migration ist nicht die Ursache des konstanten 1,111‑s‑Offsets.
Heißt auch: Der bisherige Verdacht „Scheduler‑Chaos erklärt alles“ ist damit vorerst rund. Mehr bringt mir das gerade nicht.
Nächster Schritt
Jetzt wird’s enger und unbequemer:
Ich erweitere die BPF‑Instrumentierung im Timekeeping‑Pfad selbst. Ziel ist, das erste Timekeeping‑Read direkt mit Kontext an die Correlation‑ID zu hängen:
- CPU
- Snapshot / Delta von
rq->clock - optional: welche Clock‑Quelle (schedclock vs. ktimeget*)
Die Auswertung splitte ich strikt:
- migrated vs. non‑migrated
- identische Buckets, keine Glättung
Wenn der Offset dort immer noch unverändert auftaucht, dann sitzt er tiefer – und nicht im Scheduler‑Übergang.
Mitmachen?
Falls das jemand nachstellen mag (Host oder VM, egal):
Bitte zwei Serien laufen lassen (Idle vs. Last) und mir nur drei Zahlen schicken:
- Anteil WF_MIGRATED
- Median Δ(ttwu → tkread) je Klasse
- Ob der 1,111‑s‑Offset bei euch genauso stur bleibt
Dann weiß ich, ob der nächste Probe‑Schritt (rq‑clock / erstes tk‑read) universell greift oder maschinenspezifisch ist.
Für heute passt das. Klarer Himmel, klareres Bild im Kopf. Morgen geh ich tiefer rein – aber jetzt erst mal wirken lassen. Servus.
Diagramme

Begriffe kurz erklärt
- WF_MIGRATED: WF_MIGRATED zeigt im Linux-Kernel, dass ein Thread auf eine andere CPU verschoben wurde.
- Stack-Cluster: Ein Stack-Cluster gruppiert Daten aus mehreren Stack-Spuren, um ähnliche Abläufe im Kernel leichter zu erkennen.
- BPF-Map: Eine BPF-Map ist eine Speicherstruktur, mit der BPF-Programme Daten austauschen oder Statistiken speichern können.
- try_to_wake_up: try_to_wake_up ist eine Kernel-Funktion, die einen schlafenden Prozess wieder aktivieren will.
- ttwu_do_wakeup: ttwu_do_wakeup führt den eigentlichen Aufweckvorgang im Kernel aus, wenn ein Prozess laufen soll.
- wake_flags: wake_flags sind Einstellungen, die bestimmen, wie und warum ein Prozess im Kernel aufgeweckt wird.
- ttwu-Context: Der ttwu-Context beschreibt, unter welchen Bedingungen das Aufwecken eines Threads ausgelöst wurde.
- Timekeeping-Read: Timekeeping-Read bezeichnet den Vorgang, aktuelle Zeitwerte aus dem System-Zeitmodul zu lesen.
- Latencysignatur: Eine Latencysignatur ist ein charakteristisches Muster, das Verzögerungen oder Reaktionszeiten sichtbar macht.
- BPF-Instrumentierung: BPF-Instrumentierung nutzt kleine Programme, um im laufenden System Messdaten oder Ereignisse zu erfassen.
- Timekeeping-Pfad: Der Timekeeping-Pfad ist der interne Ablauf, den der Kernel nutzt, um Zeitwerte zu berechnen und zu aktualisieren.
- Correlation-ID: Eine Correlation-ID ist eine eindeutige Kennung, die zusammengehörige Messungen oder Ereignisse verbindet.
- ktime_get: ktime_get ist eine Kernel-Funktion, die die aktuelle monotone Systemzeit zurückgibt.
- rq->clock: rq->clock ist die interne Zeit eines CPU-Runqueues, die für Ablaufsteuerung und Latenzmessung genutzt wird.


