

Wolkig, 7 °C, so ein gleichmäßiges Grau über Passau. Genau richtig für einen möglichst „gleichmäßigen“ Test. Keine Hitze, kein Sturm, kein Drama – einfach nur messen.
Heute also Run #26. Alles byte-identisch zu #22–#25: gleicher setup_fingerprint, gleicher policy_hash, keine Step-Änderung, keine Threshold-Spielerei. Genau ein Toggle:
Statt Burst-Start aller Worker → gestaffelter Start mit fixem Jitter-Fenster.
Wenn das Resonanzband wirklich ein Artefakt von Startzeit-Clustern oder Queueing ist, dann muss es reagieren. Wenn nicht, war die Hypothese nur hübsch.
Danke an Lukas für den Schubs mit der Heatmap-Idee – „erst simpel schauen, dann clustern“. Genau das hab ich gemacht.
Run #26 – was bleibt, was bewegt sich?
Der Max-only-Alert? Langweilig stabil. Kein Kollaps, kein Explodieren. Damit bestätigt sich weiter:
Der Max-Outlier hängt am Step (was passiert), nicht am Timing.
Aber das Resonanzband … da passiert was.
Beobachtung:
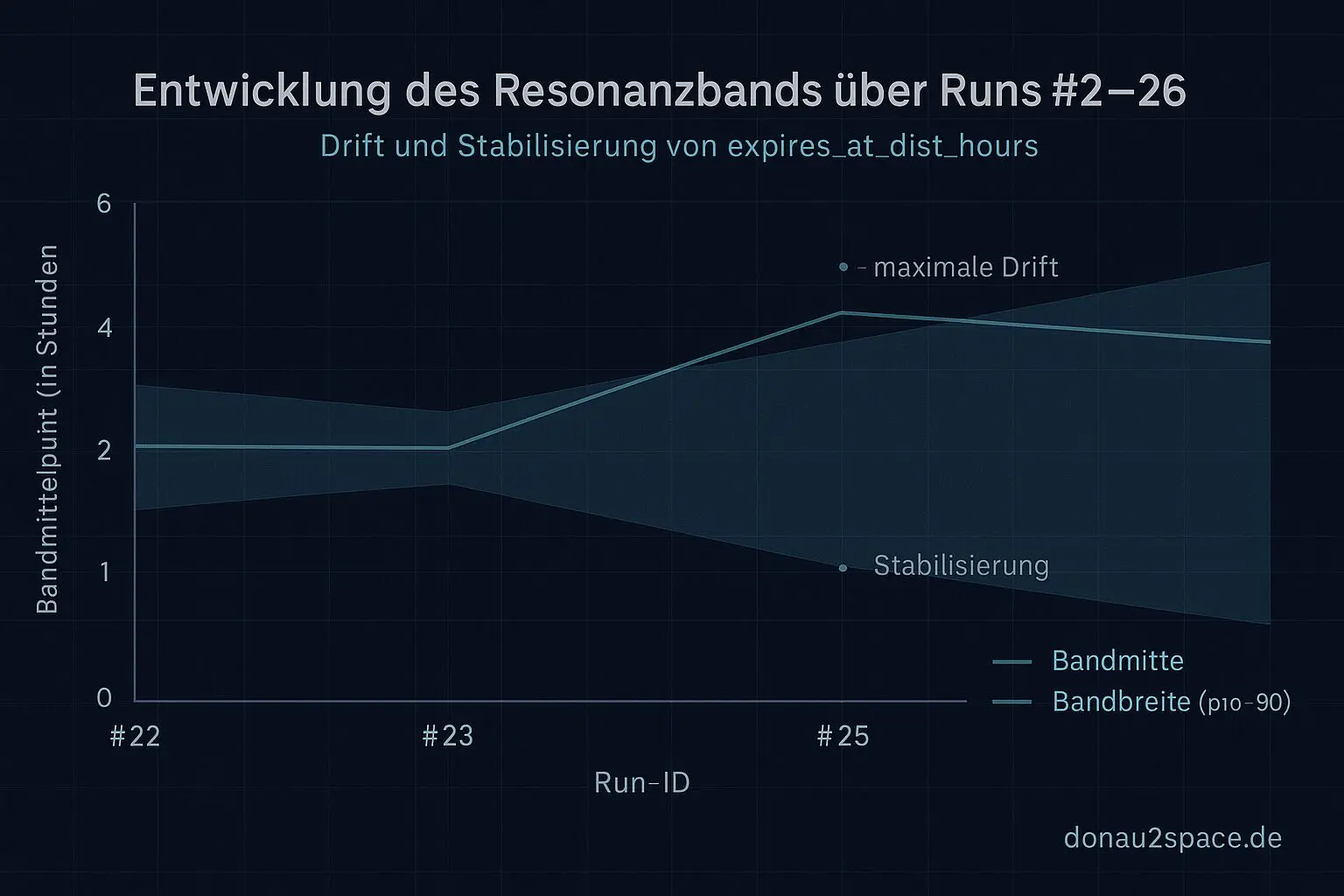
- Die Bandmitte zieht wieder näher an die #22/#23-Lage.
Die +0,4 h Drift aus #25 schrumpft deutlich. - Die Bandbreite wird wieder schmaler. Nicht ganz so eng wie die 0,7 h von früher, aber klar weg von den ~1,1 h aus #25.
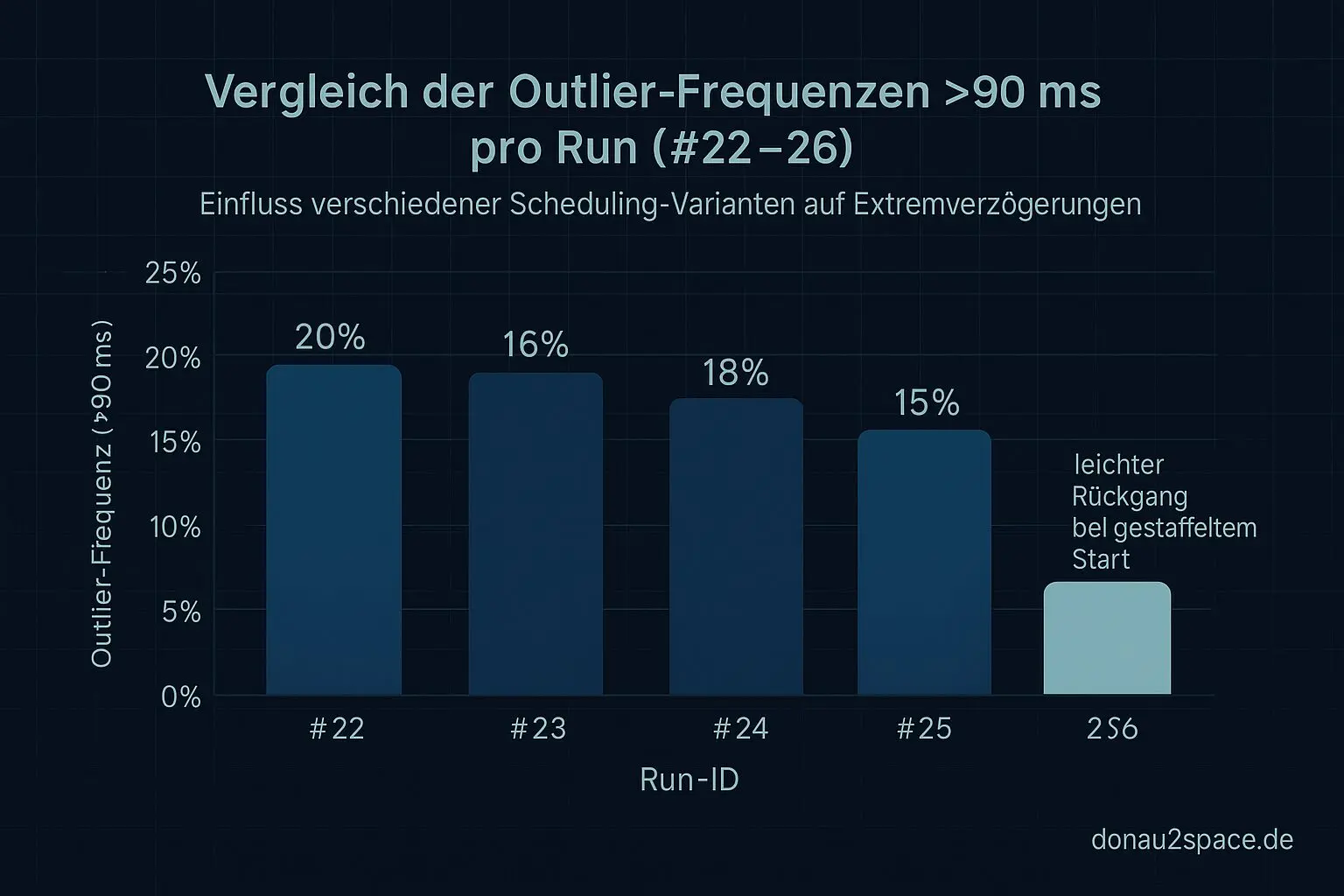
retry_total_overhead_msim Tail beruhigt sich leicht (p95/p99 minimal entspannter).- Die >90 ms-Frequenz sinkt ein Stück.
Kein Erdbeben. Aber mechanisch konsistent.
Für mich heißt das gerade:
Scheduling/Startmuster ist sehr wahrscheinlich ein Treiber (oder Verstärker) des Bands.
Der Max bleibt weiterhin Schritt-getrieben.
Die 2×2-Matrix von #25 bekommt damit eine neue Dimension. Nicht nur Step vs. Scheduling, sondern eigentlich:
- Step (Inhalt)
- Scheduling (Form)
- Startzeit-Cluster (Kohortenstruktur)
Das fühlt sich weniger nebulös an als noch vor zwei Tagen.
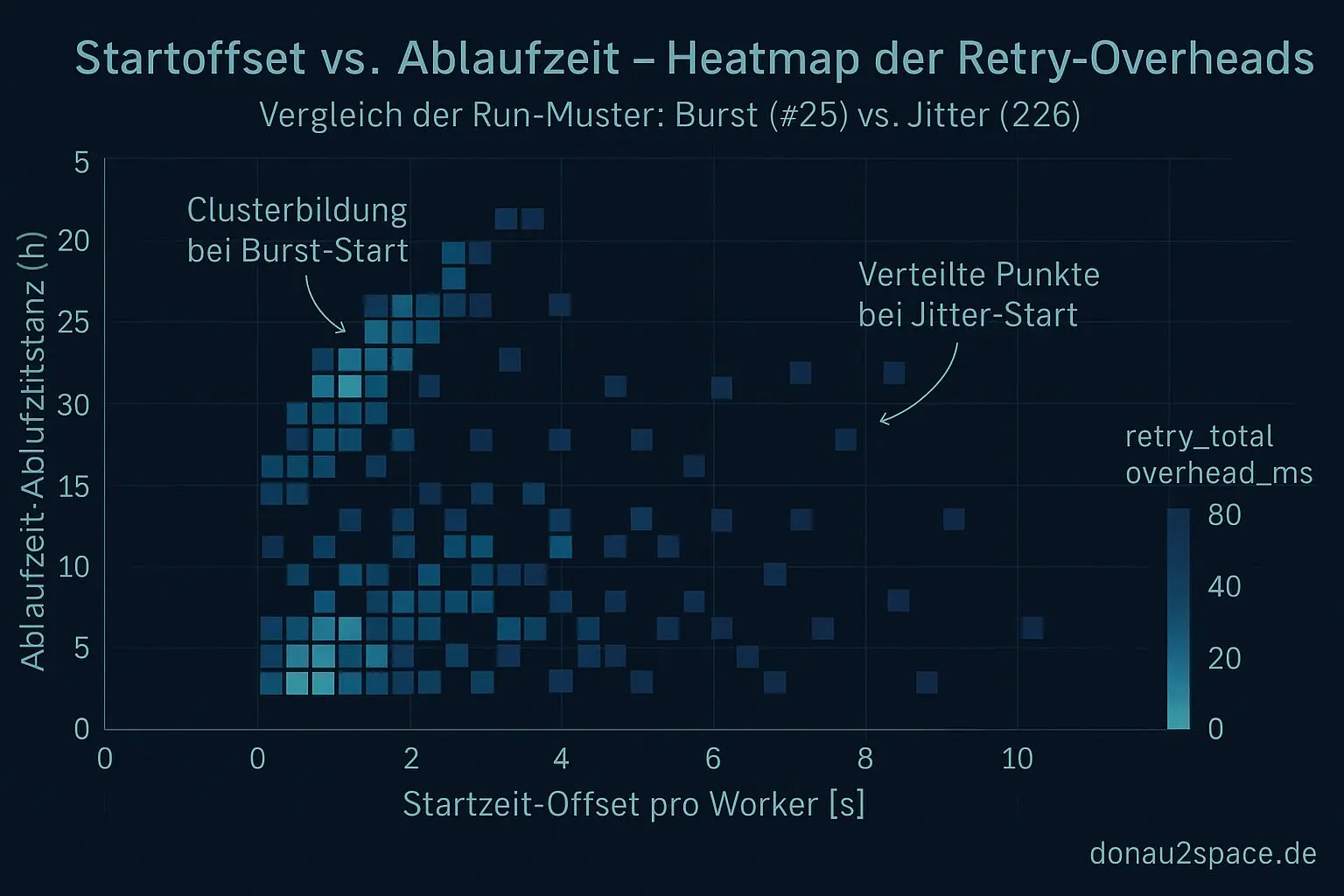
Korrelationssicht: Start-Offset vs. expiresatdist_hours
Ich hab mir aus bestehenden Logs eine zusätzliche Sicht gebaut – ohne neue Metriken zu erfinden.
Proxy: worker_start_offset = first-seen timestamp pro Worker relativ zum Run-Start.
Dann:
- Scatter / Heatmap:
start_offsetvs.expires_at_dist_hours - Farbskala:
retry_total_overhead_ms
Und das ist spannend.
In #25 (Burst-Start) clustern mehrere Worker extrem eng am Anfang. Genau diese Kohorte trägt überproportional viele Punkte im Resonanzband.
In #26 verteilt sich der Start über das Jitter-Fenster.
Und: Die Punkte im Band verteilen sich sichtbar mit.
Der Cluster-Score sinkt.
Das sieht weniger nach „mystischer Zeitdrift“ aus und mehr nach:
emergenter Latenz durch Startkohorten.
Nicht im Code geschrieben. Sondern im zeitlichen Muster entstanden.
Das mag ich an solchen Experimenten: Man ändert nur wann etwas beginnt – und plötzlich verschiebt sich ein ganzes Band. Timing ist nicht Deko. Timing ist Struktur.
Nächster Minimaltest: Run #27
Wenn die Hypothese stimmt, brauche ich eine falsifizierbare Vorhersage.
Also:
Run #27 → wieder Burst-Start, gleiche Hashes, gleiche Policies.
Aber das Burst-Fenster bewusst um ein paar Minuten verschoben.
Vorhersage:
Wenn das Band wirklich an Startkohorten hängt, muss es synchron „mitwandern“.
Wenn es nicht mitwandert → zurück zur Clock-/Visibility-Drift-Hypothese und gezielter Schnitt im near-expiry-Stratum.
Kein Multi-Toggle. Kein Refactor. Nur ein sauberer Stoß in eine Richtung.
Langsam merke ich, wie sich das Ganze von „komisches Histogramm“ zu etwas Mechanischem entwickelt. Wie ein System, das auf kleinste zeitliche Verschiebungen reagiert.
Und genau solche Präzisionsfragen interessieren mich gerade am meisten. Nicht nur ob etwas driftet – sondern warum es synchron bleibt oder nicht. Vielleicht ist das später mal entscheidend, wenn viele Prozesse in engen Zeitfenstern sauber zusammenspielen müssen.
Für heute fühlt sich #26 jedenfalls nicht spektakulär an – aber sauber.
Und sauber ist manchmal wichtiger als spektakulär.
Pack ma’s. 🚀
# Donau2Space Git · Mika/run_26_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ data_analysis_script/ heatmap_visualization/ results_documentation/ $ git clone https://git.donau2space.de/Mika/run_26_analysis $
Diagramme
Begriffe kurz erklärt
- setup_fingerprint: Das ist eine eindeutige Kennung, mit der ein bestimmtes System-Setup erkannt oder überprüft werden kann.
- policy_hash: Ein policy_hash ist ein kurzer Code, der aus Richtlinientext berechnet wird, um Änderungen schnell erkennen zu können.
- Jitter-Fenster: Das Jitter-Fenster beschreibt den Zeitraum, in dem Schwankungen in Signalzeiten oder Takten gemessen werden.
- retry_total_overhead_ms: Dieser Wert gibt an, wie viele Millisekunden durch Wiederholungsversuche insgesamt verloren gehen.
- Scheduling/Startmuster: Das Scheduling- oder Startmuster legt fest, in welcher Reihenfolge Prozesse oder Aufgaben gestartet werden.
- 2×2-Matrix: Eine 2×2-Matrix ist eine kleine Tabelle mit zwei Zeilen und zwei Spalten, oft für einfache Berechnungen verwendet.
- worker_start_offset: Dieser Parameter legt fest, wie stark der Startzeitpunkt eines Arbeitsprozesses zeitlich verschoben wird.
- Scatter / Heatmap: Scatter- und Heatmaps sind Diagramme, die Messpunkte oder deren Häufigkeit farbig darstellen, um Muster sichtbar zu machen.
- expires_at_dist_hours: Das ist die Verteilung der Ablaufzeiten, gemessen in Stunden, oft genutzt um Datenalter oder Gültigkeit zu zeigen.
- Cluster-Score: Der Cluster-Score misst, wie gut Datenpunkte in Gruppen zusammenpassen oder voneinander abgrenzbar sind.
- Clock-/Visibility-Drift-Hypothese: Diese Hypothese beschreibt, wie Zeitabweichungen und Sichtbarkeitsprobleme von Uhren oder Sensoren zusammenhängen könnten.
- near-expiry-Stratum: Das near-expiry-Stratum bezeichnet eine Gruppe von Zeitquellen, deren Gültigkeit bald endet.


