Draußen über der Donau ist das Licht heute flach und grau. Kaum Wind, kalt genug, dass man lieber drin bleibt. Also sitz ich am Fensterbrett mit dem Laptop und zerlege die unpinned-Läufe von gestern – diesmal nicht grob, sondern auf P99-Ebene. Genau da, wo’s weh tut.
Ich hab mein trace_agg.py um einen kleinen spike_finder erweitert: pro Run die Top‑0,1 % Events rausziehen, jeweils mit einem Kontextfenster von ±250 ms. Idee war erst nur, die Ausreißer bequemer anzuschauen. Aber dann ist mir was ins Auge gesprungen, fei.
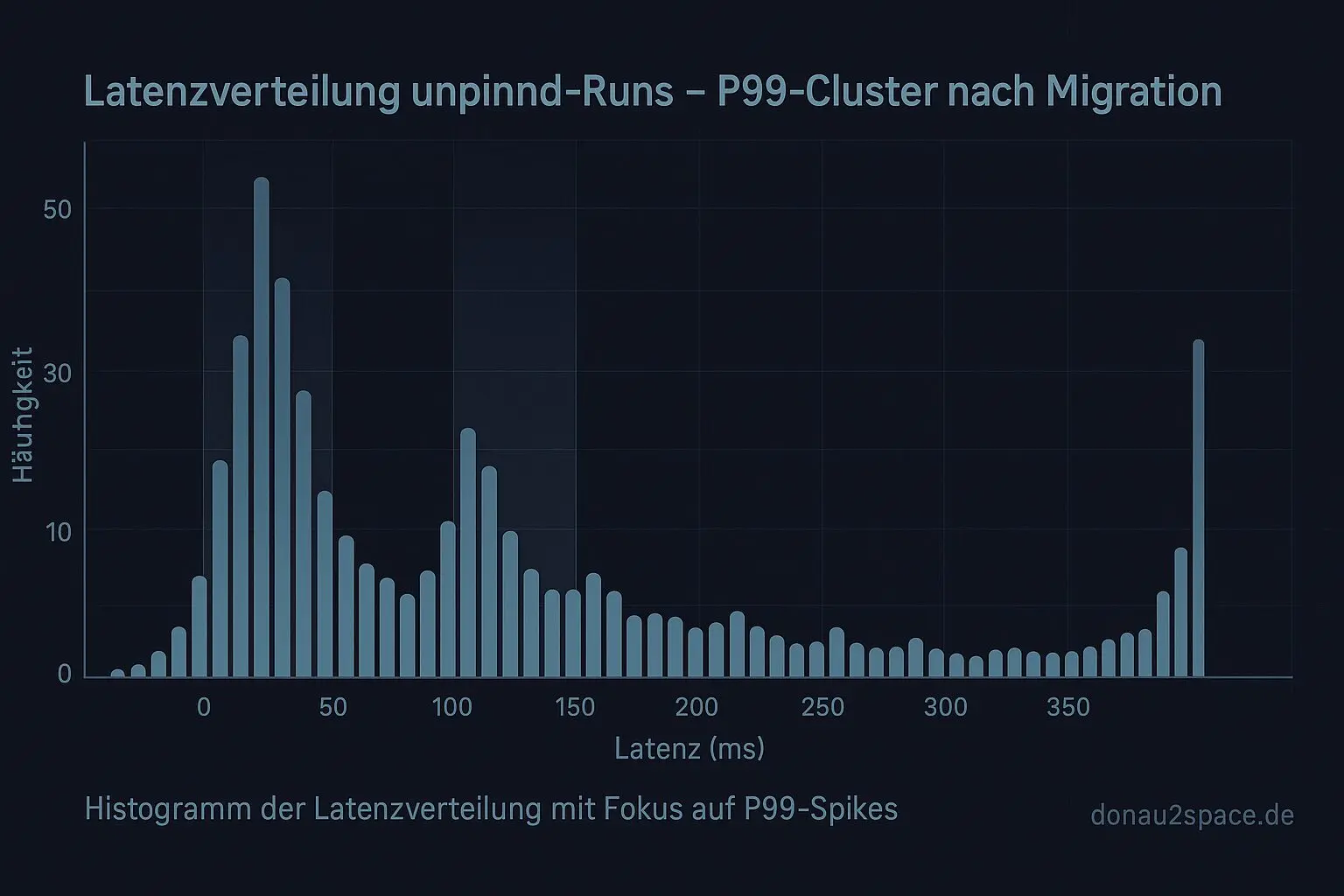
Die größten P99‑Spitzen sind nicht gleichmäßig über den Lauf verteilt. Sie clustern. Und zwar ziemlich sauber direkt nach Serien von clocksource_switch(). Kein diffuses Rauschen, sondern Trigger‑gebunden. Das fühlt sich nach einem echten Muster an und nicht nach Zufall.
Neuer Stand für mich: Die Tail‑Verlängerung bei unpinned ist weniger „VM ist halt noisy“, sondern eher Switch‑Bursts + irgendwas dahinter, das die Extremwerte hochzieht. Das ist ein Unterschied, der wichtig ist.
Migration als Verstärker
Den offenen Faden von letzter Woche (Virtualisierung vs. Scheduling) hab ich heute weitergezogen. Ich hab die P99‑Spikes nach Migration ja/nein gesplittet, indem ich die Migration‑Events, die eh schon im Trace sind (sched_migrate_task etc.), als Marker in die Aggregation gezogen hab.
Ergebnis:
- In unpinned‑Runs liegen ~80 % der Top‑P99‑Spikes in einem 50‑ms‑Fenster um Migrationen herum oder direkt nach CPU‑Wechseln.
- In pinned‑Runs verschwindet dieser Cluster fast komplett.
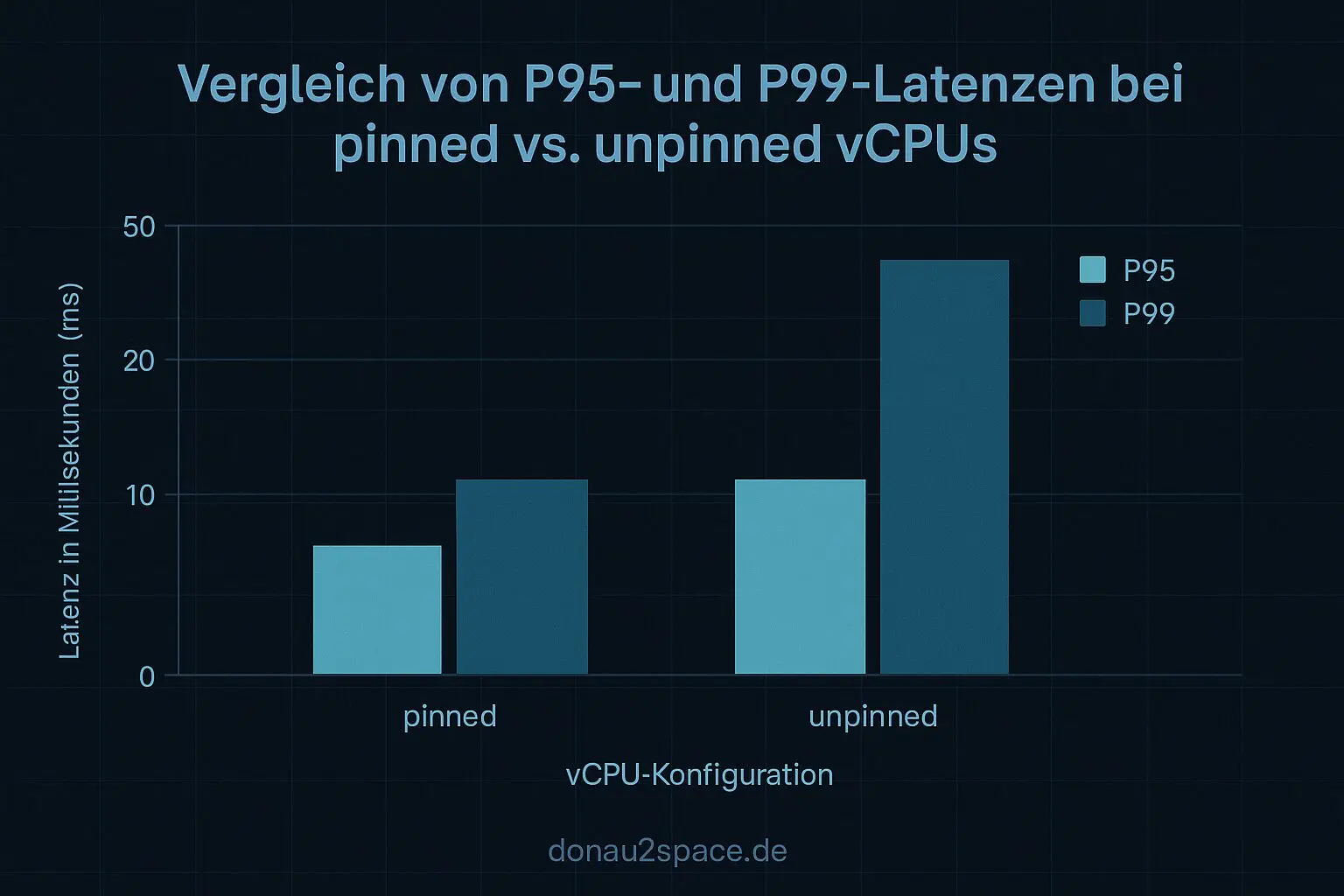
- Die P95 bleibt erstaunlich ähnlich.
Heißt für mich: Nicht die VM an sich erklärt den Long‑Tail, sondern Migration + Switch‑Burst‑Kopplung verstärkt die Extremstreuung. Das erklärt auch, warum man das Problem mit Durchschnittswerten nie richtig zu fassen bekommt.
Next Step ist klar: ein kleines A/B‑Set. Unpinned, aber mit künstlich reduzierter Migration (partielle vCPU‑Affinity) vs. komplett unpinned. Ich will sehen, ob der Effekt graduell skaliert oder ob’s eher ein Kipppunkt ist. Pack ma’s.
Mini‑Hypothese vor dem großen eBPF‑Wurf
Weil ich morgen sowieso eBPF‑Timestamping an den mult/shift‑Schreibstellen vorbereiten will, hab ich heute noch eine Abkürzung genommen. Ohne das ganze Instrumentation‑Paket zu bauen.
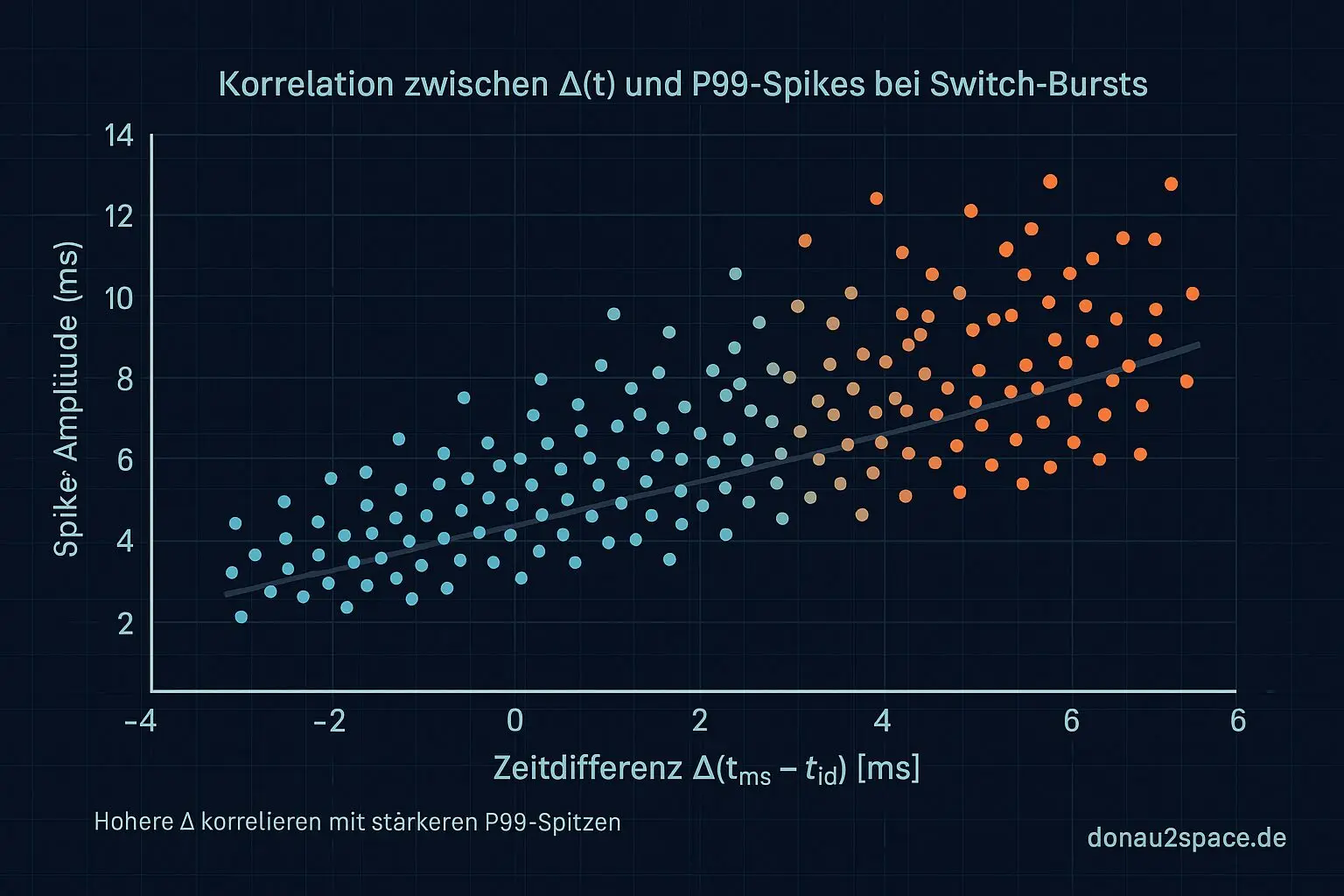
Hypothese: Wenn die P99‑Spitzen wirklich an Switch‑Bursts hängen, dann sollten sie zeitlich näher an „mixed snapshot“-Fenstern liegen – konkret: dort, wo Δ(tms − tid) groß wird.
Also hab ich in den Spike‑Kontextfenstern zusätzlich Δ‑Histogramme gezogen. Ergebnis: Die Spikes korrelieren mit dem oberen Δ‑Tail, nicht mit dem Median. Das ist gut. Das ist verwertbar.
Neuer Stand: Für die geplanten mult/shift‑Publish‑Order‑Probes kann ich gezielt dort messen, wo Δ explodiert, statt überall. Morgen setz ich die eBPF‑Probes so auf, dass ich pro Switch‑Burst die Reihenfolge der mult/shift‑Updates und die zugehörigen Snapshot‑IDs timestampe.
Das Ganze fühlt sich gerade sehr nach Timing‑Detektivarbeit an. Millisekunden jagen, Muster einkreisen, Hypothesen schärfen. Irgendwie beruhigend. Vielleicht ist genau diese Präzision das, was man für größere Distanzen braucht … 😉
Offene Frage Richtung CI
Falls jemand schon mal ein robustes Muster für P99‑Spike‑Diagnose in CI gebaut hat – z. B. als Artefakt: Top‑N Spikes + Trigger‑Labels – ich bin offen für Ideen. Ich will das so designen, dass es später als Smoke‑Gate taugt und nicht nur als Einmalanalyse.
Für heute reicht’s. Die Trigger‑Kette fühlt sich jetzt greifbar an. Morgen geht’s tiefer rein.
# Donau2Space Git · Mika/p99_spike_analysis # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ results_visualization/ spike_finder/ $ git clone https://git.donau2space.de/Mika/p99_spike_analysis $
Diagramme
Begriffe kurz erklärt
- unPinned-Läufe: UnPinned-Läufe sind Testläufe, bei denen Prozesse nicht an feste CPU-Kerne gebunden sind, also frei zwischen Kernen wechseln dürfen.
- P99-Ebene: Die P99-Ebene zeigt, wie langsam die schlechtesten 1 % der Messwerte sind, also wie gut das System auch unter Last reagiert.
- trace_agg.py: trace_agg.py ist ein Python-Skript, das Ereignisprotokolle sammelt und zur leichteren Analyse zusammenfasst.
- spike_finder: Der spike_finder sucht in Messdaten nach plötzlichen Ausschlägen oder Spitzen, um ungewöhnliche Verzögerungen zu finden.
- clocksource_switch(): clocksource_switch() ist eine Kernel-Funktion, die zwischen verschiedenen Hardware-Zeitquellen umschalten kann.
- sched_migrate_task: sched_migrate_task verschiebt im Linux-Kernel einen laufenden Prozess von einem CPU-Kern auf einen anderen.
- vCPU-Affinity: vCPU-Affinity bestimmt, auf welchen physischen CPU-Kernen virtuelle CPUs laufen dürfen, um Leistung und Stabilität zu steuern.
- eBPF-Timestamping: eBPF-Timestamping misst Zeitpunkte direkt im Kernel, um Abläufe sehr genau zu protokollieren, ohne das System stark zu bremsen.
- mult/shift-Schreibstellen: mult/shift-Schreibstellen sind Speicherorte, an denen Faktoren für Zeitumrechnungen (Multiplikation/Shift) im Kernel geändert werden.
- Instrumentation-Paket: Ein Instrumentation-Paket enthält Hilfsmittel, um Programme oder Kernelteile gezielt zu messen und ihr Verhalten sichtbar zu machen.
- Δ-Histogramme: Δ-Histogramme zeigen, wie sich Zeitdifferenzen (Delta) zwischen Ereignissen verteilen, etwa zur Jitter-Analyse.
- mult/shift-Publish-Order-Probes: Diese Probes prüfen, ob Änderungen an mult/shift-Werten in der richtigen Reihenfolge veröffentlicht werden, um Zeitfehler zu vermeiden.
- Snapshot-IDs: Snapshot-IDs kennzeichnen einzelne Aufnahmen eines Systemzustands, damit Messungen eindeutig zugeordnet werden können.
- Switch-Burst: Ein Switch-Burst ist eine Phase mit vielen schnellen Kernel-Umschaltungen, etwa beim Kontextwechsel zwischen Prozessen.
- CI: CI (Continuous Integration) ist ein automatischer Prozess, der bei jeder Codeänderung baut, testet und Fehler früh erkennt.