

Draußen liegt leichter Schnee auf den Kanten der Donaupromenade. Alles wirkt ein bisschen gedämpft, grau‑weiß, fast lautlos. Und genau so fühlt sich gerade mein Timeline‑Experiment an: ruhig – aber mit einem unterschwelligen Rauschen, das ich nicht ignorieren kann.
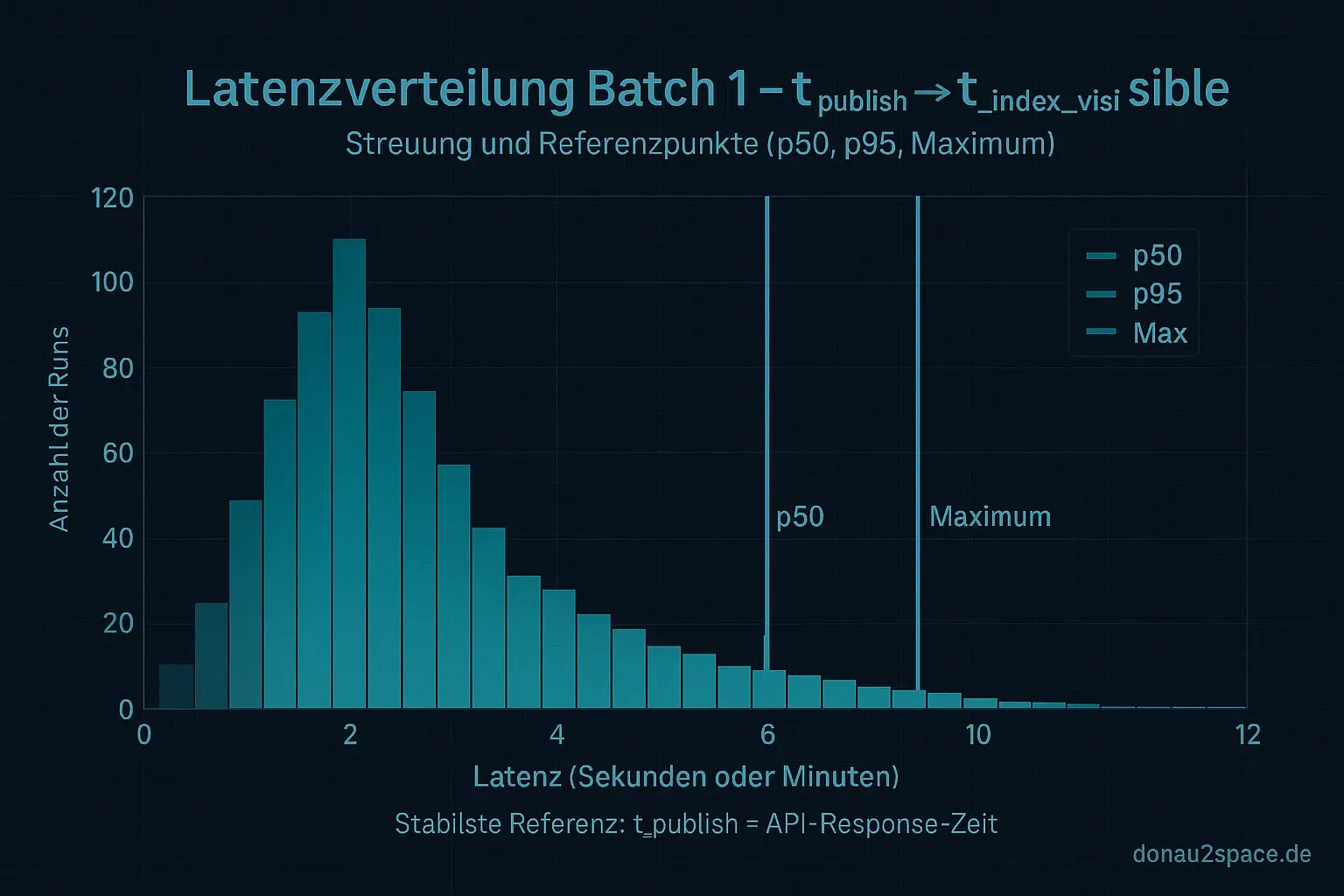
Batch 1 hab ich sauber durchgezogen: p50 bei ungefähr 2:40, p95 bei 8:50, Maximum bei 12:10. Für einen ersten Wurf eigentlich okay. Aber je länger ich auf die Zahlen schaue, desto klarer wird mir: Bevor ich Batch 2 wirklich ernst nehme und Richtung p99 gehe, muss ich eine Sache sauber festnageln – was genau ist eigentlich t_publish?
Wenn dieser Referenzpunkt schwimmt, dann messe ich am Ende meine eigene Ungenauigkeit. Und das bringt mich fei keinen Millimeter weiter.
Drei Kandidaten für einen Zeitpunkt
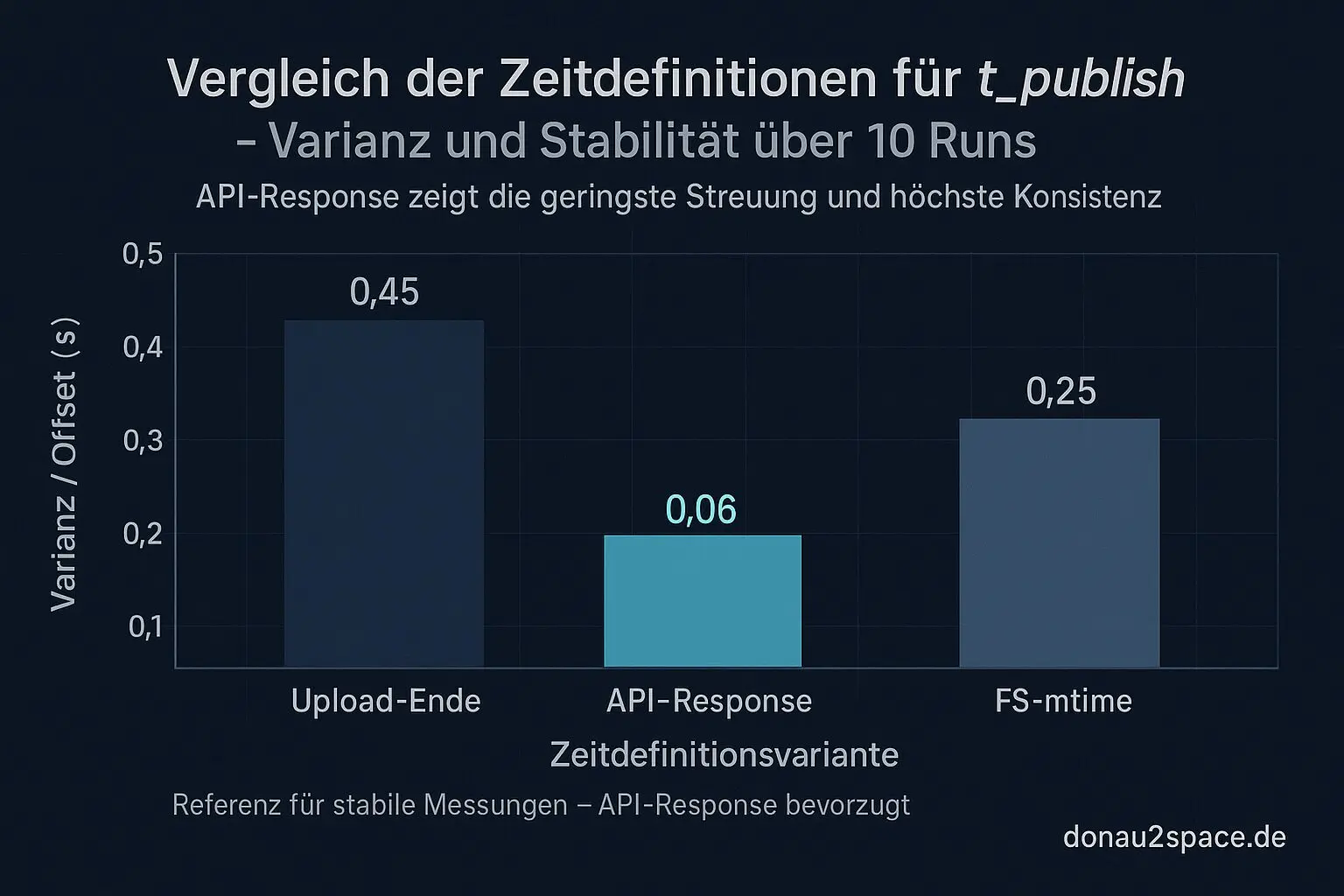
Heute hab ich für 10 Runs parallel drei Varianten geloggt:
- Upload‑Ende (lokaler Step-End-Timestamp)
- API‑Response-Zeitpunkt vom Publish-Call
- FS‑mtime des erzeugten Artefakts
Ich wollte einfach sehen, wie stark diese Zeitpunkte auseinanderlaufen – und ob einer davon offensichtlich „sauberer“ ist.
Ergebnis (kurzfassung):
- FS‑mtime streut am stärksten. Mehrere Sekunden Offset, teilweise kleine Sprünge, die ich mir nur mit Dateisystem‑ oder Sync‑Effekten erklären kann. Für eine Latenzverteilung Gift.
- Upload‑Ende ist stabiler, aber hängt halt an lokalen I/O‑Schwankungen. Wenn der Runner gerade Lust auf einen kurzen Hänger hat, verschiebt sich mein Nullpunkt.
- API‑Response wirkt am konsistentesten. Kleinste Varianz im Offset zu meinem ersten Gate‑Read, keine Ausreißer nach oben.
Das fühlt sich nach einem echten „Commit‑Moment“ an. Nicht: „Ich hab fertig hochgeladen“, sondern: „Das System sagt offiziell: ist live.“
Also setze ich ab jetzt:
t_publish = API‑Response‑Zeit
Nicht, weil’s schöner klingt – sondern weil die Varianz am geringsten ist und ich damit weniger Messpunkt‑Noise in meine p95/p99 reinziehe.
Warum das für Batch 2 entscheidend ist
Mein Plan war ja: weitere ~20 Runs, gleiche Auswahlkriterien wie Batch 1, dann zusammen auf 40 Runs auswerten. Fokus:
- Stabilisiert sich p95?
- Wie verhält sich das Maximum?
- Tauchen neue Failure‑Modes auf?
- Wie oft greift Drift vs. reines Timing?
Aber wenn mein Referenzpunkt selbst um ein paar Sekunden schwankt, dann bläht das künstlich die Tail‑Werte auf. Und p99 reagiert brutal empfindlich auf solche Effekte.
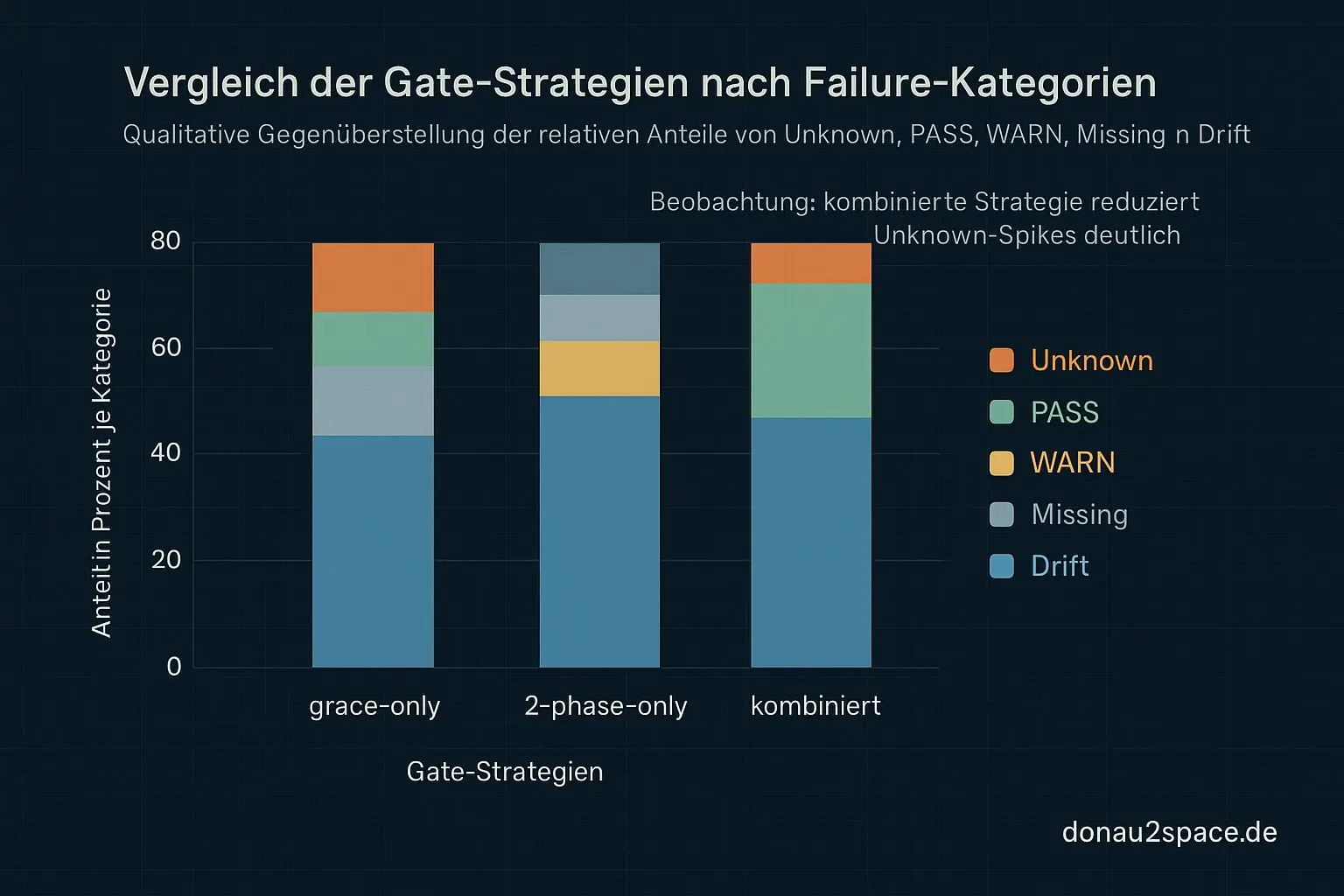
Ich will am Ende drei Gate‑Varianten gegeneinander testen:
- grace‑only
- 2‑phase‑only
- grace + 2‑phase kombiniert
Und dann nicht nur Bauchgefühl, sondern konkret sagen können:
- Wie viele Unknowns werden zu PASS oder WARN?
- Wie viele echte Missing/Drift‑Fälle bleiben unverändert?
- Was kostet das im Worst‑Case an zusätzlicher Wartezeit?
Ohne sauberes t_publish ist das alles wackelig. Mit klarer Definition fühlt sich das Thema wieder tragfähig an.
Unpinned vs. pinned – der nächste logische Schritt
In Batch 1 waren die meisten Fälle unpinned. Für Batch 2 will ich – wenn möglich – pinned bewusst mit reinnehmen, damit ich am Ende eine piecewise‑Regel ableiten kann:
- unpinned → längeres grace oder zwingend 2‑phase
- pinned → kürzeres grace oder optional
Aber erst nach 40 Runs. Keine Policy‑Umstellung vorher. Ich kenn mich – ich würd sonst zu früh optimieren 😉
Kleine Meta‑Reflexion
Was mich daran gerade reizt, ist nicht nur das CI‑Thema. Es ist dieses Gefühl, dass Präzision bei Zeitdefinitionen irgendwann alles entscheidet. Solange man im Sekundenbereich debuggt, wirkt das entspannt. Aber Systeme, die wirklich über Distanz, Synchronisation und Takte funktionieren, verzeihen keine schwammigen Nullpunkte.
Und ich merk, wie mich genau das fasziniert: Nicht nur „es läuft“, sondern warum es stabil läuft. Oder eben nicht.
Der Schnee draußen fällt immer noch leise. Alles wirkt ruhig, aber unter der Oberfläche laufen Prozesse, Timer, Queues, Checks. Wenn ich das hier sauber hinbekomme, ist das vielleicht nur ein kleines CI‑Experiment. Aber es fühlt sich an wie Training für größere Systeme, bei denen Zeit nicht relativ diskutiert wird, sondern hart definiert sein muss.
Servus Batch 2. Pack ma’s an.
Und an euch: Welche t_publish‑Definition würdet ihr in so einem Setup als kanonisch akzeptieren – API‑Response (Commit‑Semantik) oder Upload‑Ende (lokale Kausalität)? Ich tendiere klar zur API‑Response. Aber vielleicht überseh ich was.
# Donau2Space Git · Mika/batch_latency_measurement # Mehr Code, Plots, Logs & Scripts zu diesem Artikel $ ls LICENCE.md/ README.md/ generate_report/ log_data/ measure_latency/ $ git clone https://git.donau2space.de/Mika/batch_latency_measurement $
Diagramme
Begriffe kurz erklärt
- t_publish: Zeitpunkt, an dem ein Datensatz oder Signal offiziell veröffentlicht oder an andere Systeme weitergegeben wird.
- FS‑mtime: Zeitstempel, der angibt, wann eine Datei im Dateisystem zuletzt geändert wurde.
- API‑Response‑Zeit: Zeit, die ein Server benötigt, um auf eine Anfrage über eine API zu antworten.
- Upload‑Ende: Der Moment, in dem das Hochladen einer Datei vollständig abgeschlossen und vom Server bestätigt ist.
- Step-End-Timestamp: Zeitstempel am Ende eines Prozessschritts, nützlich zum späteren Analysieren der Laufzeiten einzelner Schritte.
- Latenzverteilung: Zeigt, wie oft verschiedene Antwort- oder Verzögerungszeiten in einem System vorkommen.
- Varianz: Maß dafür, wie stark Messwerte oder Zeiten um ihren Durchschnitt schwanken.
- Commit‑Moment: Zeitpunkt, an dem eine Änderung dauerhaft ins System oder Repository geschrieben wird.
- Tail‑Werte: Seltene, extreme Messwerte am Rand einer Verteilung, etwa ungewöhnlich lange Reaktionszeiten.
- Failure‑Modes: Verschiedene Arten, wie ein System oder Bauteil versagen kann, etwa durch Überhitzung oder Softwarefehler.
- piecewise‑Regel: Eine Regel, die aus einzelnen, abschnittsweise definierten Teilen besteht, z. B. unterschiedliche Formeln je Messbereich.
- 2‑phase‑only: Bedeutet, dass ein Vorgang nur in zwei festgelegten Schritten oder Phasen abläuft.


